はじめに
実験をやっていると、測定量 $Z$ が2つのパラメータ $X$, $Y$ に依存するような状況がよくあります。こういう時、結果を $X$ vs $Z$ ないし $Y$ vs $Z$ のグラフで個々にまとめても良いですが、$X$ vs $Y$ vs $Z$ のカラープロット1一枚にまとめると、より俯瞰的にデータを見渡すことができます。
ただ、このカラープロットというのが少々厄介で、作成に必要な $(X,Y,Z)$ の2次元データを用意するためには素のデータに対し何らかの前処理が必要となることがほとんどです。そこで、この記事では実際によく直面する2つのケースを例に、カラープロット作成のためのデータ整形方法を説明します。
カラープロット作成に必要なデータ
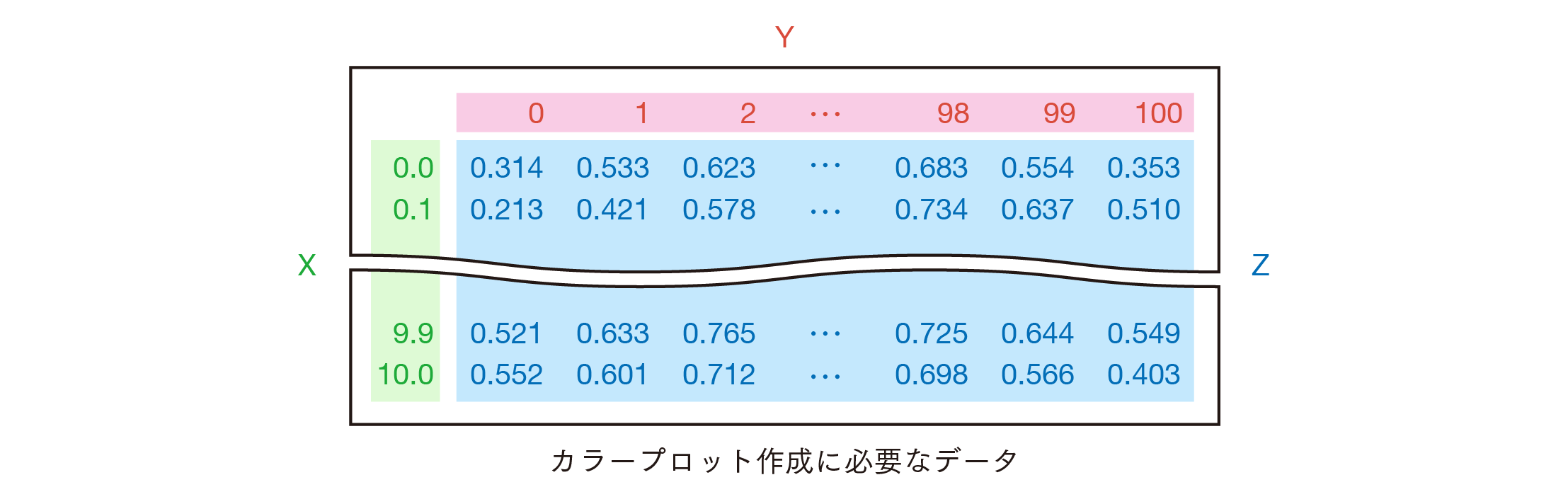
カラープロットを作成するときには上のようなデータ構造が必要になります。
つまり、$X$、$Y$の2軸に対して$Z$の値が格納されているようなメッシュ状のデータです。
以下ではこの形をゴールに、データを整形していきます。
よくあるケース
では前処理が必要となる2つのケースです。
なお、以下の例ではファイルの拡張子をDATにしていますが、処理のところではCSVについても補足を入れています。最初の読み込み方が違うだけで処理は同じです。
1. データファイルが分割されている
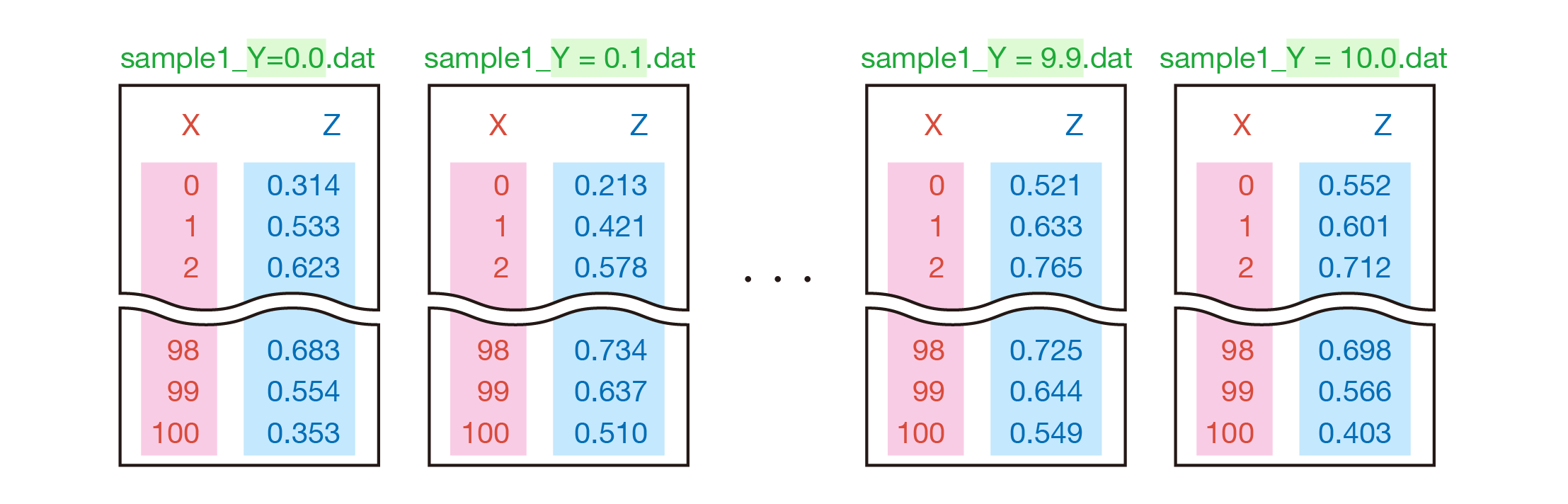
一つ目の例は $X$、$Y$ のうち、どちらかのパラメータでデータファイルが分割されている場合です。
この場合は分割されたファイルの結合が必要になり、また今 $Y$ の値はファイル名に記録されているため、その値を抽出して、$Y$ のリストを作る必要があります。
# このファイルを実行すると例1のサンプルデータができます。
# 適当な作業ディレクトリを作成した上で実行してください。
import numpy as np
# パラメータの定義
intensity = 50 #強度
HWHM = 3 #半値半幅
a = 3 #データのばらつきの大きさ
# データファイルの作成
for Y in np.arange (0, 10.1, 0.1):
filename = 'sample1_Y={}.dat'.format(str(Y))
X0 = (200 * Y * Y + 2500) ** 0.5 - 50
with open(filename, 'w') as file:
file.writelines('X' + '\t' + 'Z' +'\n')
for X in range (0, 101):
Z = intensity * HWHM ** 2 / ((X - X0) ** 2 + HWHM ** 2)\
+ 20 + a * np.random.rand()
file.writelines(str(X) + '\t' + str(Z) + '\n')
2. 一つのファイル内にすべてのデータが連なっている
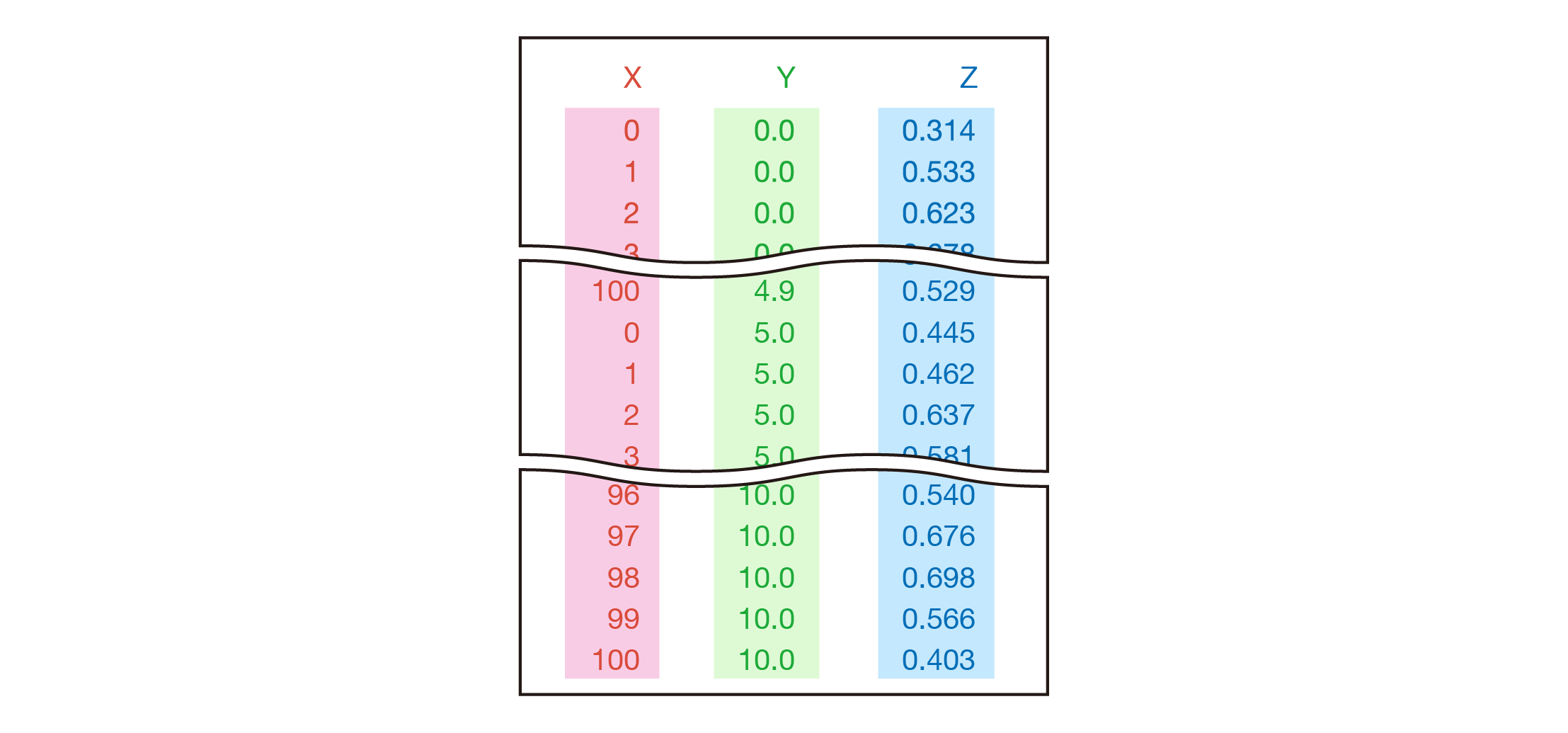
2つ目の例は一つのファイル内にひたすら $X$、$Y$、$Z$ が書き込まれている場合です。
この場合は $Y$ 列を横軸にして $Z$ を並び替えるようなデータ整形が必要になります。
# このファイルを実行すると例2のサンプルデータができます。
# 適当な作業ディレクトリを作成した上で実行してください。
import numpy as np
# パラメータの定義
intensity = 50 #強度
HWHM = 3 #半値半幅
a = 3 #データのばらつきの大きさ
# データファイルの作成
with open('sample2.dat', 'w') as file:
file.writelines('X' + '\t' + 'Y' + '\t' + 'Z' +'\n')
for Y in np.arange (0, 10.1, 0.1):
X0 = (200 * Y * Y + 2500) ** 0.5 - 50
for X in range (0, 101):
Z = intensity * HWHM ** 2 / ((X - X0) ** 2 + HWHM ** 2)\
+ 20 + a * np.random.rand()
file.writelines(str(X) + '\t' + str(Y) + '\t' + str(Z) + '\n')
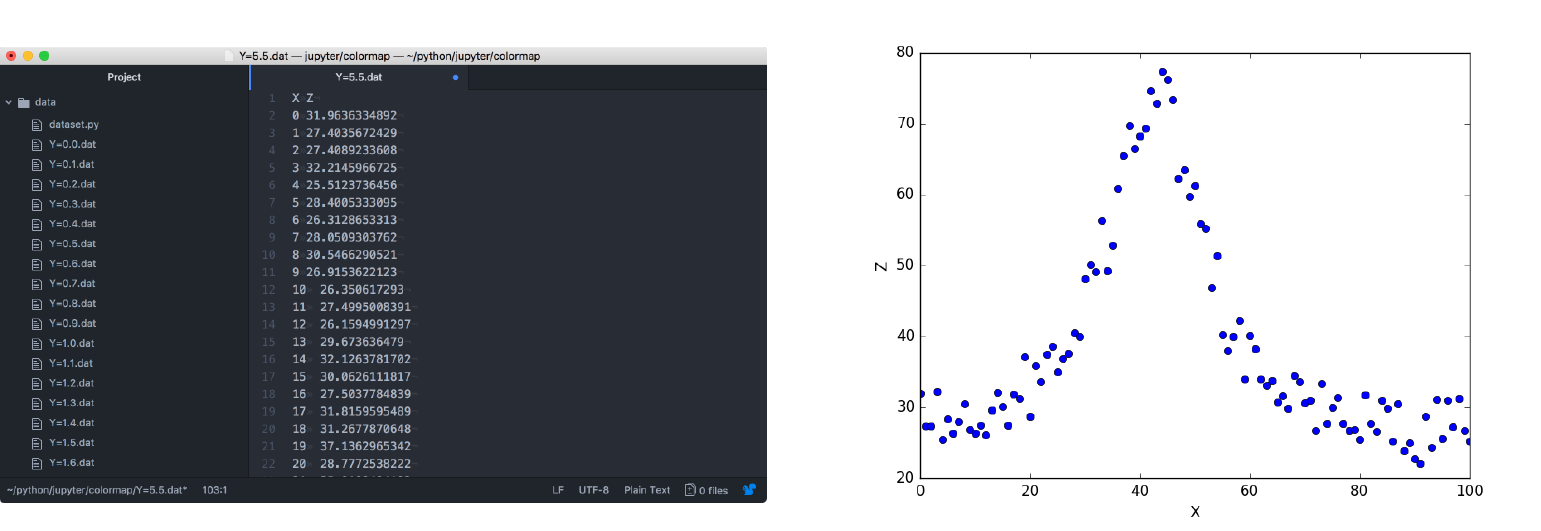
[余談]今回サンプルとして用意したのはローレンツ分布です。sample2.pyは1ファイルですが、sample1.pyの場合はデータファイルを分割しており、Y=0.0~10.0まで、0.1刻みで101個のdatファイルになります。試しにY=5.5.datを開くと左図のようになっています。$Z$ を $X$ についてプロットしたグラフが右図です。この山の位置が $X$ と $Y$ に依存しています。
データ処理とカラープロット
ということで、この2つのケースを例に、これからデータの整形を行います。
作業にはJupyter Notebookを使います。
1.データファイルが分割されている場合
import re, glob
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
ライブラリを読み込みます。
filelist = glob.glob('*.dat')
df = pd.DataFrame()
for file in filelist:
match = re.match('sample1_Y=(.*).dat', file)
df_sub = pd.read_table(file) #CSVの時はpd.read_csv()を使用
df[float(match.group(1))] = df_sub.Z
df.columns.name = 'Y'
df.index = df_sub.X
df
Y 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 ... 9.0 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9
X
0 71.307065 71.624977 72.568247 70.073268 71.388264 71.429283 69.430455 66.104600 64.251044 61.960019 ... 20.892164 21.724984 20.259025 21.625291 22.658143 22.641024 20.799494 21.042593 20.667364 20.451245
1 66.347248 65.184597 66.907600 67.807422 67.879276 70.401552 72.100718 72.617697 72.195462 70.692071 ... 20.409888 22.230631 21.106551 22.801198 21.159110 20.973036 21.779757 20.625188 21.405971 21.577096
2 54.815612 54.960281 55.477640 57.619689 59.971637 60.601975 63.984228 65.729155 67.846441 69.637961 ... 21.854349 20.668861 20.172761 20.416828 21.374005 21.202518 21.688063 21.056256 22.637612 20.305400
3 46.311290 46.916455 47.512971 47.175870 48.731614 50.673641 52.572572 55.803255 59.562894 62.597950 ... 22.427942 20.156526 21.141887 22.187281 21.712688 22.921697 22.876228 22.972608 22.592168 21.185094
4 40.442910 38.820936 38.994950 41.859569 40.333883 42.995725 45.152994 47.650007 49.414120 53.309453 ... 21.873397 20.659303 21.022158 20.543980 23.023661 21.418374 22.771670 20.218522 22.349163 21.412955
5 35.598731 33.633262 35.782304 36.352184 35.778557 37.035520 38.947890 40.425551 41.307669 43.021355 ... 22.766781 20.876074 20.208458 21.890359 22.792392 22.499805 22.652404 22.497508 22.339281 21.668357
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
95 21.804124 21.797596 23.010401 20.258773 20.073975 21.918238 22.169896 21.988170 20.120070 20.975194 ... 28.402855 28.041022 32.390451 36.689843 48.158836 58.781772 71.028003 67.065172 52.942427 42.138778
96 21.250080 21.630843 21.553191 22.952056 21.329605 20.270100 21.658320 20.191202 21.166837 20.145893 ... 27.438835 27.227526 31.282917 32.428334 40.363609 50.900390 63.092738 70.580351 63.513627 48.526807
97 22.389748 21.693057 20.886997 21.460203 22.610140 20.102447 23.021290 22.793081 22.306881 20.704143 ... 25.180590 26.366878 28.042743 30.121939 36.192960 40.735346 53.298041 67.425563 70.242088 60.144091
98 21.265201 21.367930 21.225976 20.466155 21.115541 20.294466 20.556839 22.789051 20.945778 21.343996 ... 23.949042 24.200023 26.902070 28.732446 32.388426 35.483425 44.613251 56.697203 68.448203 70.253491
99 22.688459 22.243006 22.604197 22.114754 22.967067 22.538572 21.954847 22.286714 22.779653 20.139557 ... 23.386930 24.568997 25.573001 27.852061 30.095048 32.057468 37.229132 47.773504 61.152210 71.645167
100 21.503768 20.480336 21.507903 21.943483 21.158995 20.880028 22.613661 21.468507 22.059082 20.855645 ... 24.196745 25.333946 24.965214 27.570366 27.059141 31.368592 34.169847 40.928392 48.591212 62.390900
101 rows × 101 columns
ディレクトリにあるDATファイルをglobで検索し、一つずつデータフレームdf_subとして読み込みます。
そして、df_subの2列目($Z$)を最終的にカラープロットに起こすデータフレームdfに追加していきます。
その際、カラム名にはファイル名からre.matchで読んだ $Y$ の値を設定しています。
plt.pcolor(df.index, df.columns, df.T)
plt.colorbar()
plt.axis('tight')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()

最後はmatplotlibを使って、この通りカラープロットできます。
※データフレームでは Y=10.0 のカラムがないように見えますが、Y=1.9 と Y=2.0 の間に入っています。これはglobでファイルを検索したときに数値の箇所が文字列として比較されたためです。plotする際には当然Yの値で並ぶので問題ありませんが、もしなにか問題があるときには別途カラムのソートが必要になります。
2. すべてのデータが連なっている場合
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
ライブラリを読み込みます。
df = pd.read_table('sample2.dat') #CSVの時はpd.read_csv()を使用
df
| | X | Y | Z |
|:--|:--|:--|:--|
| 0 | 0 | 0.0 | 72.891364 |
| 1 | 1 | 0.0 | 66.015389 |
| 2 | 2 | 0.0 | 56.577833 |
| 3 | 3 | 0.0 | 47.967175 |
| 4 | 4 | 0.0 | 40.049795 |
| 5 | 5 | 0.0 | 33.520995 |
| ... | ... | ... | ... |
| 10195 | 95 | 10.0 | 34.230043 |
| 10196 | 96 | 10.0 | 39.323960 |
| 10197 | 97 | 10.0 | 47.548997 |
| 10198 | 98 | 10.0 | 55.833268 |
| 10199 | 99 | 10.0 | 66.757378 |
| 10200 | 100 | 10.0 | 70.632926 |
10201 rows × 3 columns
データを読み込みました。これを $X$、$Y$ について集計します。
DataFrameのメソッド、.pivot_table()を使います。
df_pivot = pd.pivot_table(data=df, values='Z', columns='Y', index='X', aggfunc=np.mean)
df_pivot
Y 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 ... 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9 10.0
X
0 72.891364 71.124620 70.654984 70.037212 70.172797 69.732972 68.793112 65.933899 64.488065 59.392308 ... 23.045598 22.673641 22.600140 22.112334 21.315886 21.963097 21.105755 21.827151 21.567903 21.151945
1 66.015389 66.330797 67.099211 69.468310 68.399146 68.998129 70.942877 71.911890 70.655064 68.509530 ... 20.235786 21.015988 22.415627 20.175461 20.249661 21.286285 22.163261 20.167906 22.193590 22.611962
2 56.577833 55.291176 57.559546 57.364896 58.140628 61.156353 63.832460 66.498951 67.410308 69.306595 ... 20.598574 21.103155 21.149578 21.014833 21.009504 21.841099 21.587648 22.296160 21.123641 22.874411
3 47.967175 47.952907 45.950706 47.029444 48.391456 51.034951 52.411894 56.019204 59.728020 63.807839 ... 22.514587 22.240905 22.201533 21.571261 22.403295 21.390697 20.246681 22.210926 21.520711 21.784959
4 40.049795 38.779545 41.234613 40.129730 41.675496 43.363557 44.458340 45.149790 49.194773 53.192819 ... 20.296393 21.070061 20.863386 21.854448 21.168673 22.133117 21.882360 20.162296 21.350260 20.466510
5 33.520995 34.508065 33.640439 34.172906 37.379081 35.589519 38.723906 38.893507 40.820806 44.050499 ... 21.119756 20.837089 22.140866 23.018667 21.209434 22.741423 20.494395 21.803438 20.179044 21.418150
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
95 21.609598 21.595324 21.822186 21.381549 21.119773 22.047828 22.708401 21.714110 22.622491 21.829242 ... 28.407967 32.270296 37.226492 48.122027 60.701823 69.480529 65.041743 52.447009 40.167799 34.230043
96 22.725472 20.298792 22.131073 20.807929 21.241496 20.429434 21.873849 20.708636 21.940816 21.854451 ... 27.856948 29.345740 33.471768 39.978015 50.693978 64.438375 70.241885 63.729539 48.403309 39.323960
97 22.734694 22.755155 21.598300 20.712057 22.349692 21.692798 22.985825 22.995810 20.447362 22.031959 ... 27.358939 27.096302 30.500497 35.350520 41.393291 54.023276 65.693318 69.426084 60.709163 47.548997
98 20.429320 20.835029 22.714230 22.396262 22.322744 21.048957 22.671866 21.613990 20.339620 22.711587 ... 24.988529 28.050123 29.537614 32.430894 36.235623 44.963558 56.700622 68.762960 69.940436 55.833268
99 21.826368 22.945654 22.277211 20.131568 21.019710 21.633040 21.798181 21.139721 20.183818 22.055120 ... 25.848098 27.116651 27.592164 29.924541 31.438265 39.224727 45.971381 60.573153 70.092905 66.757378
100 22.964366 22.522586 22.005465 20.918149 21.038924 22.418933 21.325841 22.340799 20.054492 22.689244 ... 23.969884 26.387081 25.109298 26.920826 28.967549 34.624010 38.952119 49.455348 64.123081 70.632926
101 rows × 101 columns
先ほどと同じ形にデータが整形されました。
あとはmatplotlibでプロットするだけです。
plt.pcolor(df_pivot.index, df_pivot.columns, df_pivot.T)
plt.colorbar()
plt.axis('tight')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
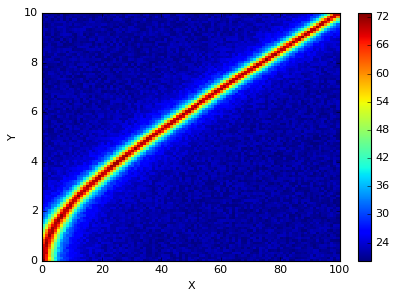
ということで、2つの例でカラープロットができました。
[宣伝]こういう記事も書いてるのでよかったら参考にどうぞ。。
Python / pandasのDataFrameで実験データ解析(物理屋さん、工学屋さん向け)
-
イメージプロットやカラーマップ、ヒートマップとも呼ばれますが、この記事では呼び方をカラープロットで統一します。 ↩