はじめに
リレーショナルデータベース(RDB)についての記事も早くも第3段となりました。今回は前回インストールしたPostgreSQLを使い、実装をしてみたいと思います。
今回はdelikaのダミーデータを使用したいと思います。
delikaとは、データの収集や分析をオープンにする事で、より効率良く新たな価値創出につながると考え開発されたプラットフォームです。
(ちなみに、今Qiitaでいい感じのイベントも開催中なので要チェックです。)
前回↓
CREATE TABLE文(データインポート)
PostgreSQLはcsvファイルを直接読み込ませる事ができないので、読み込ませる前にCREATE TABLE文を使い、空のデータテーブルを作成する必要があります。その際に、どのようなデータが入ってくるか、ある程度指定してあげます。
PostgreSQLを開き、Query Editorに以下のコードを打ち込みます。
CREATE TABLE articles (
id char(15) Primary Key, /*Primary Keyになるデータ*/
created_at TIMESTAMP NOT NULL, /*時系列データ*/
likes_count INTEGER NOT NULL, /*数値データ*/
comments_count INTEGER NOT NULL,
url VARCHAR(255) NOT NULL, /*255文字以内の文字列データ*/
users VARCHAR(50) NOT NULL, /*50文字以内の文字列データ*/
page_views_count INTEGER NOT NULL
);
CREATE TABLE tags (
id char(15) PRIMARY KEY,
name char(50) NOT NULL
);
CREATE TABLE articles_tags_map (
id char(50) PRIMARY KEY,
article_id char(50) NOT NULL,
FOREIGN KEY (article_id) /*Foreign Keyになるデータ*/
REFERENCES articles (id),/*Foreign Keyになるデータの参照データ*/
tag_id char(50) NOT NULL,
FOREIGN KEY (tag_id)
REFERENCES tags (id)
);
コードを走らせ、Database→Scheme→public→Tableの下に上記で指定したテーブルが表示されていれば成功です。
右クリックし、Import/Export Dataを選択し、インポートしたいファイルを選択します。
データ概観
Articles テーブル
SELECT 文を使って、articlesのデータセットを呼び出して見ましょう。*は「全て」を意味しています。
SELECT * FROM articles;
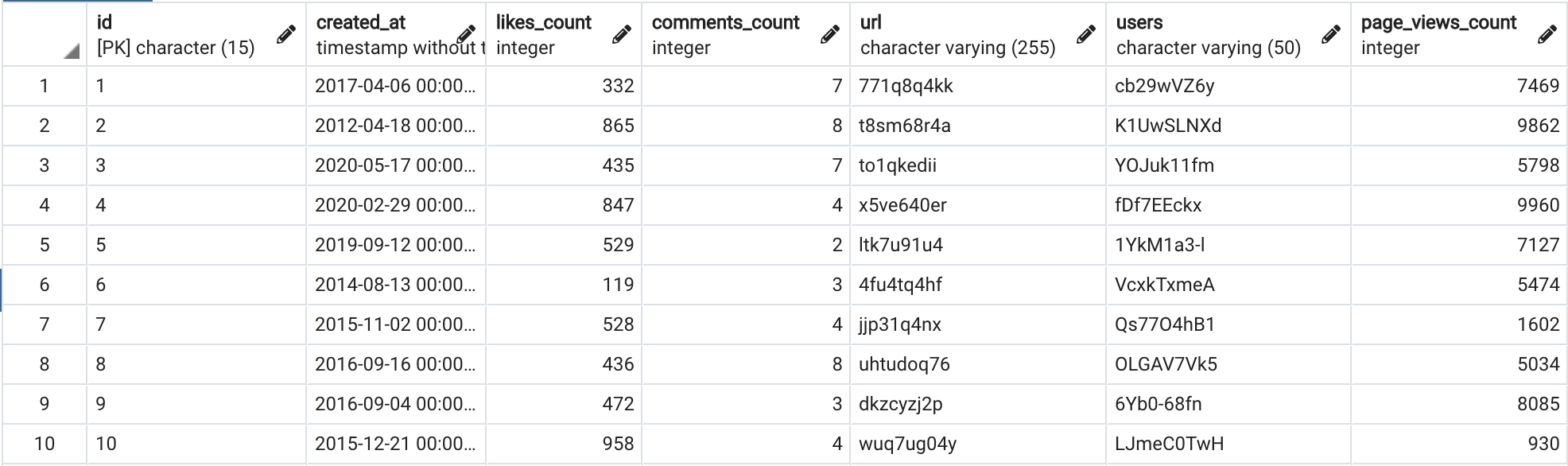
Articleテーブルには以下のデータが入っている事がわかります。
- id (Primary Key)
- created_at(投稿日)
- likes_count(いいね数)
- url (記事のURL)
- users(ユーザー名)
- page_views_count(閲覧数)
次に、tagsテーブルを見てみましょう
Tags テーブル
SELECT * FROM tags;

tagsテーブルには以下のデータが入っている事がわかります。
- id (Primary Key)
- name(タグ名)
次はarticles_tags_mapテーブルです。
articles_tags_map テーブル
SELECT * FROM articles_tags_map;

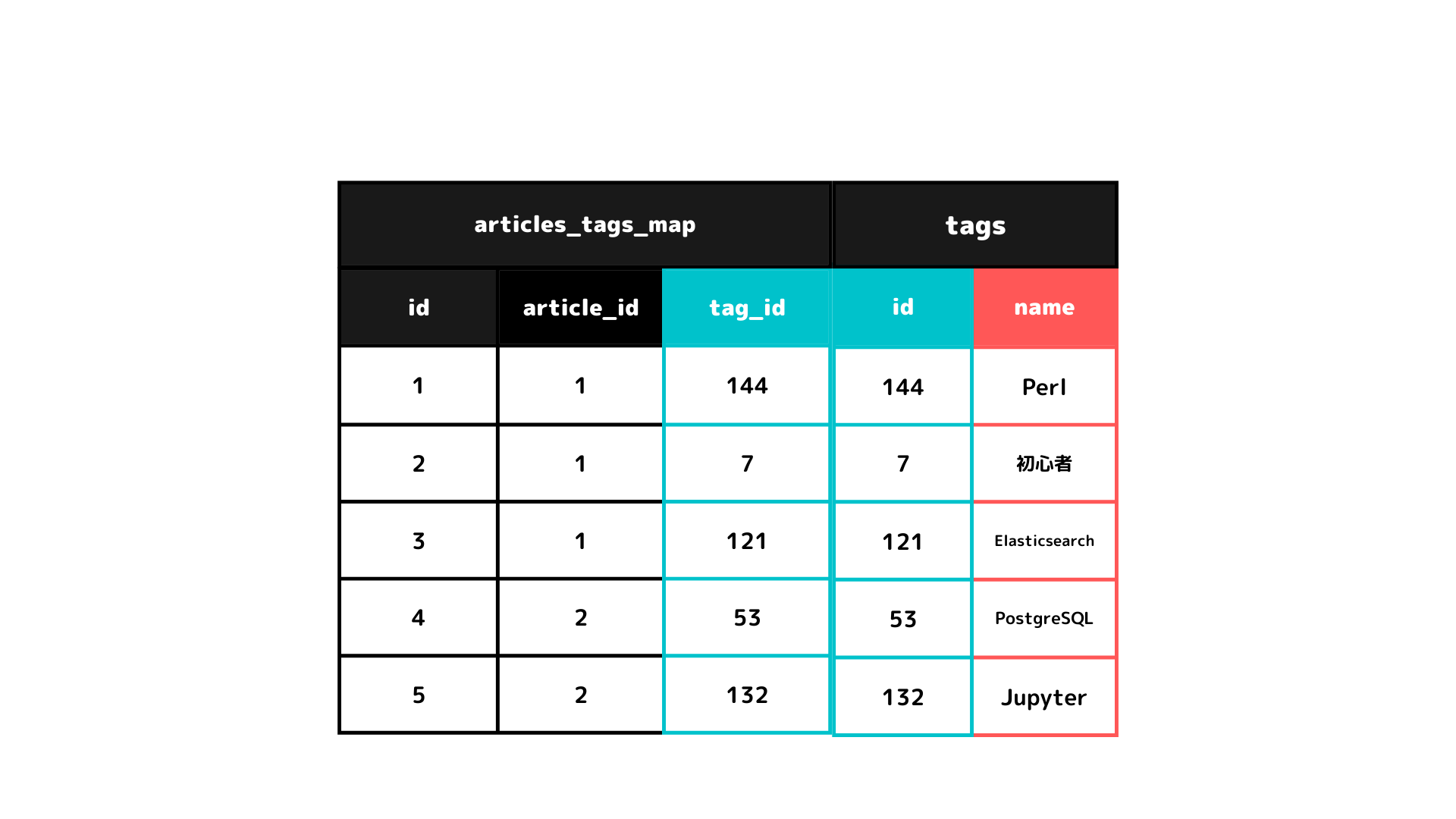
勘の言い方はもうお気づきかと思いますが、これは、Associative Table(連想テーブル)です。
article_id が「1」の記事にtag_idが「144」,「7」,「121」のタグがついている事を表します。
JOIN文
では、article_id = 1 の記事のタグ「144」,「7」,「121」は一体何なのか見てみましょう
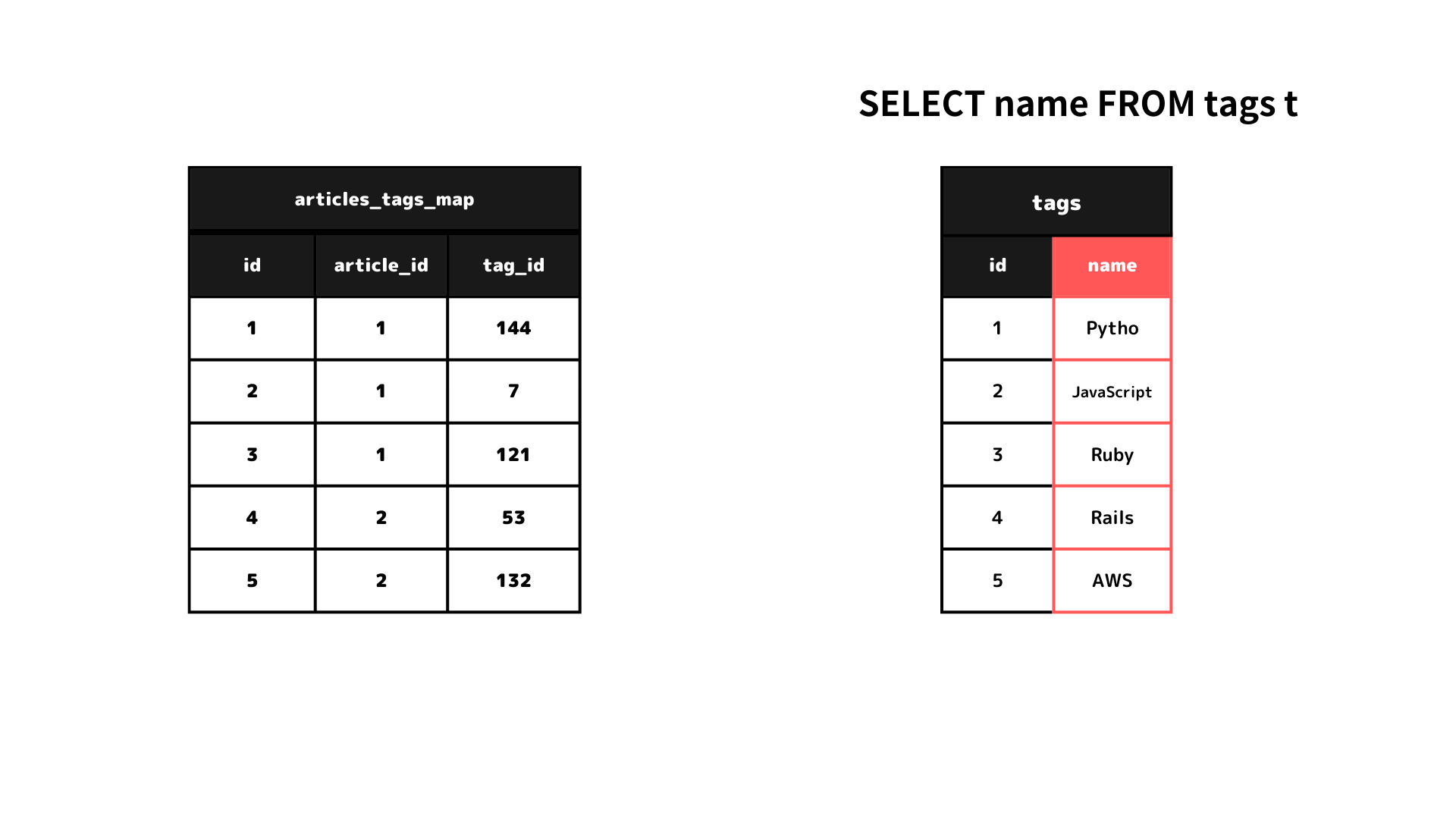
SELECT name FROM tags t
JOIN articles_tags_map ON t.id = tag_id
WHERE article_id = '1'

なるほどarticle_id = 1 の記事のタグは「Perl」,「初心者」,「Elasticsearch」だったのですね!
コードを1行づつ説明します。
1.SELECT
まず、タグの名前を知りたいので、SELECT分を使ってtagsテーブルのnameの属性を指定します。
SELECT name FROM tags
2.JOIN
次にJOIN分を使い、articles_tags_mapと繋げます。その際に、
「articles_tags_mapのtag_idと、tagsのidを繋げるヨ」と、指定しています。
(この際「id」という属性が、articles_tags_mapとtagsテーブル両方に存在しているので、tagsの方の「id」を繋げるようにtags.idとしています)
JOIN articles_tags_map ON tags.id = tag_id
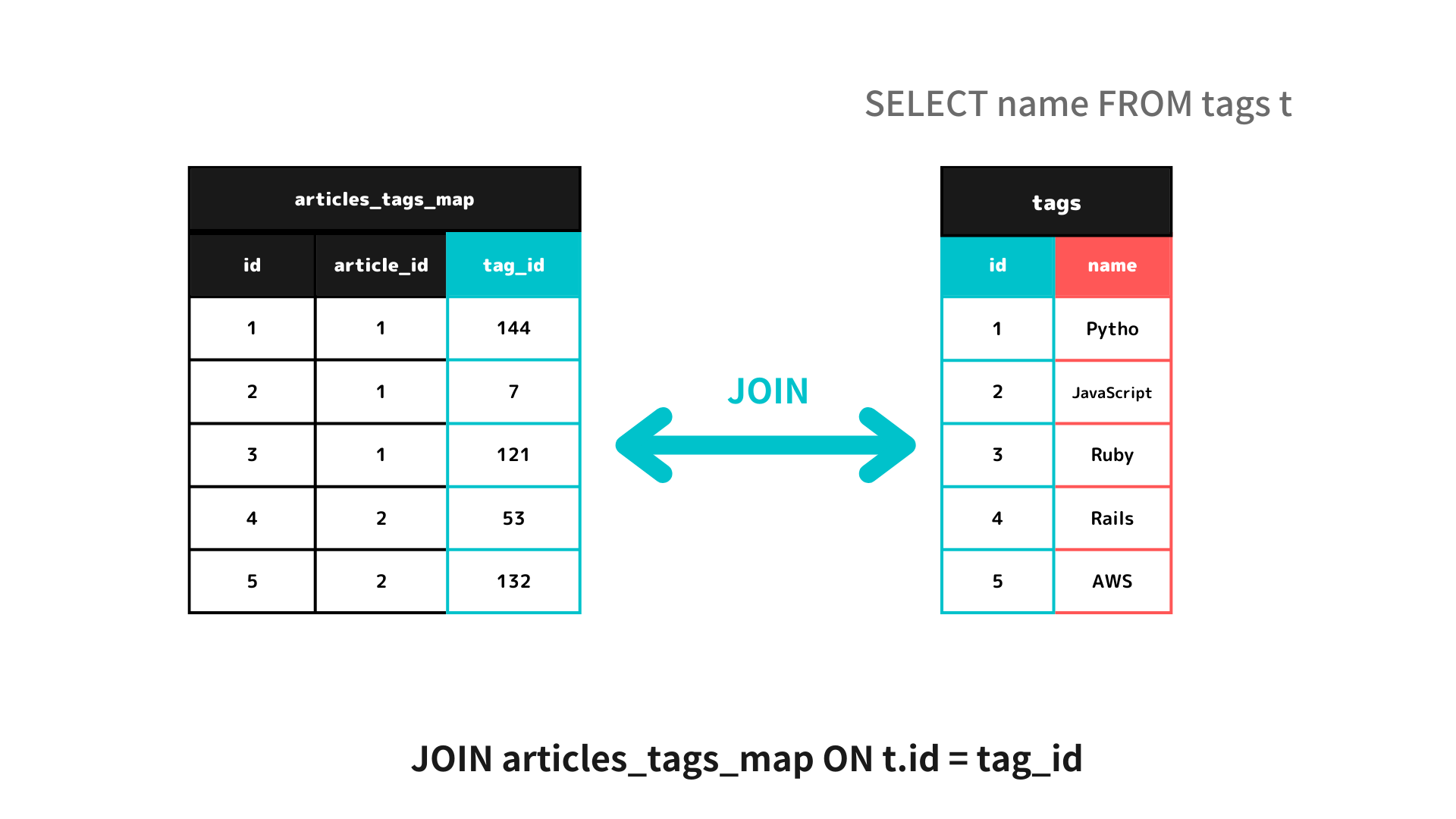
JOIN (結合)後↓
3.WHERE
最後に、「article_idが1の」、と指定してあります。
WHERE article_id = '1';

この様な工程を経て、以下のアウトプットがされたのです!
SELECT name FROM tags t
JOIN articles_tags_map ON t.id = tag_id
WHERE article_id = '1'
GROUP BY 文
作者ごとのいいね数を比較したい時、はGROUP BY文が有効です。
SELECT users, sum(likes_count) as count /*sum関数で合計を計算し、countオブジェクトに定義*/
FROM articles
GROUP BY users /*グループにするぞ属性を選択*/
ORDER BY count desc /*1行目で定義したcountが高い順に表示*/
limit 5 /*上位5名を表示*/;
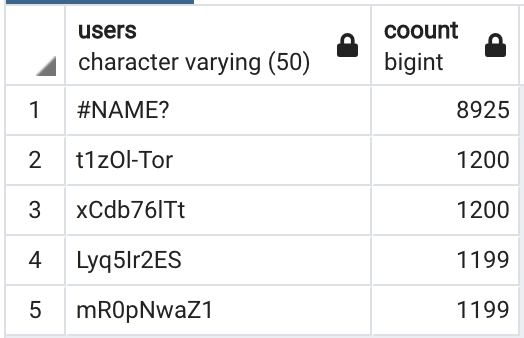
「#NAME?」という方がいいねランキング1位ですね、名前からしてデータの欠損値の可能性が高いですね。1位は「t1zOl-Tor」さんとして良いでしょう。
おわりに
慣れない間はややこしい作業ですが、一度慣れちゃえばすぐできる様になります!SQL100本ノックとやればすぐ慣れます。(昔学校で永遠とSQLを打つという課題あったなぁ…)
次回はSQLのもう少し難しいテクニックを紹介しようかと思います!
次回↓
関連記事はこちら