※本記事は題名の通りPostgreSQL13でのPITRについて記載しています。PostgreSQL11以前では設定ファイル名が異なるのでご利用のPostgreSQLのバージョンに合わせて公式ドキュメントもご参照ください。
PITR(ポイントインタイムリカバリ)とは
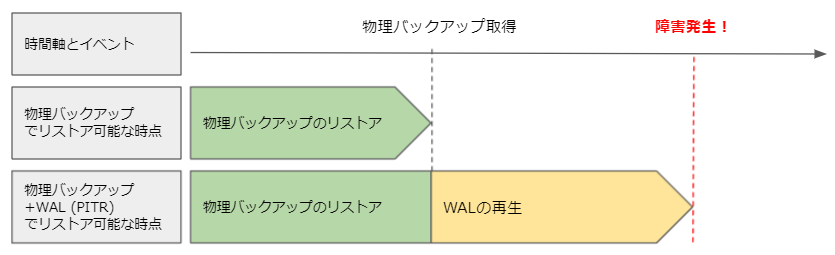
PITR (ポイントインタイムリカバリ) とはDBを過去の任意の時間の状態に戻すことを言います。
定期的なバッチ処理等による物理バックアップのみだとバックアップ時の断面にしかDBを戻すことができません。
しかし物理バックアップに加えてトランザクションのログ(WAL)も逐一保存しておくことにより、物理バックアップ断面からWALを再生することでDBを任意の時間の状態に戻すことができるようになります。
前提知識 - WALとWALアーカイビング
WALとは、先ほど述べたようにDBに対して与えた変更(トランザクション)を記録したログのことです。WALは実質的には無限に生成されるバイナリデータですがPostgreSQLはそれを一定の大きさ(16MB)で切り分けてファイルに記録しており、それをWALセグメントファイルと言います。
WALセグメントファイルは${PGDATA}/pg_walに保存されており、PostgreSQLにより任意のタイミングで改廃されます。
しかしWALセグメントファイルが勝手に改廃されてはいざ障害が起きたときにリストアに必要なWALセグメントファイルが失われている可能性があります。
そこで、PostgreSQLには新たなWALセグメントファイルが生成されたときにユーザの好きな方法(外付けHDDへのコピー、クラウドへのアップロード等)でWALセグメントファイルを退避できる仕組みがあります。
それをWALアーカイビングと言います。
PITRを実現するためにはこのWALとWALアーカイビングに関して適切に設定をしておく必要があります。
PITRを実現するために最低限必要な設定
以下にPITRを実現するために最低限必要な設定を示します。他にも数多くの設定項目があるので詳しくはPostgreSQLのドキュメントを参照してみてください。
postgresql.confに記載する設定
| パラメータ名 | 説明 | PITRを実現するための設定値 |
|---|---|---|
| wal_level | walに記録する情報の量を設定する。minimal, replica, logicalの順で記録する量が多くなる。デフォルトはreplica。 | replica以上 |
| archive_mode | WALアーカイビングを有効化するかどうかの設定。on, off, alwaysを指定できる。 | onかalways |
| archive_command | WALセグメントファイルをアーカイブする際に実行するコマンドを設定する。%pはアーカイブ対象となるファイルパス、%fはアーカイブされるファイル名のみに置き換えられる。アーカイブに成功した時のみリターンコード0を返す必要がある。例)cp %p /mnt/server/archivedir/%f | 適当なコマンド |
| restore_command | リストア時に必要となるWALセグメントファイルを取得するコマンドを設定する。%pは取得したWALセグメントファイルの設置先パス、%fは必要なWALセグメントファイル名に置き換えられる。例) cp /mnt/server/archivedir/%f %p | 適当なコマンド |
| max_wal_senders | standbyサーバやバックアップ取得のためのWAL senderの最大数を設定する。物理バックアップ取得の際に2つ使うため、WAL senderが足りるよう妥当な数を設定する。デフォルトは10。 | 適当な数 |
pg_hba.confに記載する設定
物理バックアップを取得できるようにするために、レプリケーション接続を許可する必要があります。以下のように、物理バックアップ取得コマンドを実行するサーバからreplication接続が許可されていれば良いです。
# TYPE DATABASE USER ADDRESS METHOD
host replication all samenet md5
PITRを実際にやってみる
0. 環境
OS: CentOS Linux release 8.4.2105
DB: PostgreSQL 13
1. DBの設定
postgresql.confに関しては、デフォルトから変えたのは以下の通りarchive_mode、archive_command、restore_commandのみです。WALのアーカイブ先は/backup/wal_archivesディレクトリにしました。
[postgres@instance-1 ~]$ diff /dbdata/postgresql.conf /dbdata/postgresql.conf.default
237c237
< archive_mode = on # enables archiving; off, on, or always
---
> #archive_mode = off # enables archiving; off, on, or always
239c239
< archive_command = 'cp %p /backup/wal_archives/%f' # command to use to archive a logfile segment
---
> #archive_command = '' # command to use to archive a logfile segment
250c250
< restore_command = 'cp /backup/wal_archives/%f %p' # command to use to restore an archived logfile segment
---
> #restore_command = '' # command to use to restore an archived logfile segment
[postgres@instance-1 ~]$
pg_hba.confに関しては、デフォルトでunixソケット経由でのレプリケーション接続は許可されているのでインストール時から特に何も変えていません。
2. データ準備
適当なテーブルを作成し何件かレコードを挿入します。
create table test_table (title varchar(30));
insert into test_table (title) values ('record_001'), ('record_002'), ('record_003');
結果的にtest_tableには3レコード入っている状態です。
postgres=# select * from test_table;
title
------------
record_001
record_002
record_003
(3 rows)
postgres=#
3. 物理バックアップ(ベースバックアップ)取得
ここで物理バックアップを取得してみます。物理バックアップを取得するにはPostgreSQLインストール時に標準で入っているpg_basebackupというコマンドを実行します。pg_basebackupを使うとオンライン(DBが稼働状態)で物理バックアップを取得することができます。主なオプションは以下の通りです。
| オプション | 説明 |
|---|---|
| -D | バックアップの配置先ディレクトリを指定する。 |
| -F | バックアップ形式を指定する。pかplainを指定すると圧縮をせずにそのままの状態でバックアップする。tかtarを指定するとtar圧縮した状態でバックアップする。 |
| -z | -Fでtarを指定した時のみに指定できるフラグで、tarに加えてさらにgzip圧縮をかけた状態でバックアップする。 |
| -P | バックアップの進捗を表示する。 |
| -v | verboseモード。より多くの情報を表示する。 |
| -h | 接続するDBのホスト名。指定しなかった場合unixソケットでの接続が行われる。 |
| -p | 接続するDBのポート。 |
| -U | 接続するユーザ名を指定する。 |
今回はバックアップしたデータをtar圧縮し/backup/base_backups/20211205に配置します。
[postgres@instance-1 ~]$ pg_basebackup -D /backup/base_backups/20211205 -Ft -P -v -U postgres
pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: 0/6000028 on timeline 1
pg_basebackup: starting background WAL receiver
pg_basebackup: created temporary replication slot "pg_basebackup_1807"
24395/24395 kB (100%), 1/1 tablespace
pg_basebackup: write-ahead log end point: 0/6000100
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: syncing data to disk ...
pg_basebackup: renaming backup_manifest.tmp to backup_manifest
pg_basebackup: base backup completed
[postgres@instance-1 ~]$ ls -al /backup/base_backups/20211205/
total 40920
drwxr-xr-x. 2 postgres postgres 63 Dec 5 06:10 .
drwxr-xr-x. 3 postgres postgres 79 Dec 5 06:10 ..
-rw-------. 1 postgres postgres 136306 Dec 5 06:10 backup_manifest
-rw-------. 1 postgres postgres 24981504 Dec 5 06:10 base.tar
-rw-------. 1 postgres postgres 16778752 Dec 5 06:10 pg_wal.tar
[postgres@instance-1 ~]$
4. 更にデータを挿入
物理バックアップのみのリストア時とPITR実行時の違いを見るために、物理バックアップ後にいくつかレコードを挿入してみます。
insert into test_table (title) values ('record_004'), ('record_005');
結果的にtest_tableには5レコード入っている状態です。
postgres=# select * from test_table ;
title
------------
record_001
record_002
record_003
record_004
record_005
(5 rows)
postgres=#
ここで障害が起きたと仮定し、物理バックアップのみのリストアをした場合とPITRを実行した場合のtest_tableの様子を確認してみましょう。
5-1. リストア (物理バックアップのみ)
まずは物理バックアップのみのリストアを行ってみます。ご自身の環境で行う場合は適宜パス等をを読み替えてください。
# 1. DBを停止する。
[root@instance-1 ~]# systemctl stop postgresql-13
# 2. 現時点のWAL(${PGDATA}/pg_wal配下)を圧縮して退避しておく。可能であれば${PGDATA}配下のすべてを退避しておくことが望ましい。
[root@instance-1 dbdata]# cd /dbdata/pg_wal/
[root@instance-1 pg_wal]# tar zcvf latest_pg_wal.tar.gz *
...
[root@instance-1 pg_wal]# mv latest_pg_wal.tar.gz ~
# 3. ${PGDATA}配下を全て削除する。
[root@instance-1 ~]# su - postgres
Last login: Sun Dec 5 05:57:56 UTC 2021 on pts/0
[postgres@instance-1 ~]$ rm -rf /dbdata/*
# 4. 物理バックアップ (base.tar) を${PGDATA}にコピーし解凍する。
[postgres@instance-1 ~]$ cp /backup/base_backups/20211205/base.tar /dbdata/
[postgres@instance-1 ~]$ cd /dbdata/
[postgres@instance-1 dbdata]$ tar xvf base.tar
...
[postgres@instance-1 dbdata]$ rm base.tar
# 5. 物理バックアップ時のWAL (pg_wal.tar) を${PGDATA}/pg_walにコピーし解凍する。
[postgres@instance-1 dbdata]$ cp /backup/base_backups/20211205/pg_wal.tar /dbdata/pg_wal/
[postgres@instance-1 dbdata]$ cd pg_wal/
[postgres@instance-1 pg_wal]$ tar xvf pg_wal.tar
000000010000000000000006
[postgres@instance-1 pg_wal]$ rm pg_wal.tar
# 6. DB起動
[postgres@instance-1 dbdata]$ exit
logout
[root@instance-1 ~]# systemctl start postgresql-13
これで物理バックアップのみのリストアは完了しました。この状態でtest_tableの中身をのぞいてみましょう。
postgres=# select * from test_table ;
title
------------
record_001
record_002
record_003
(3 rows)
postgres=#
当たり前ですが物理バックアップ取得時の断面に戻っているのでレコードは3件しか入っていません。
5-2. リストア (PITR)
いよいよPITRを行ってみます。
[注意] 以下の手順は「5-1. リストア (物理バックアップのみ)」を実施後に行っているのではなく、「4. 更にデータを挿入」の後に行っているものです。5-1と5-2は直列に実施するものではなく別々の世界線で並列に行われたものだと思ってください。
# 「5-1. リストア (物理バックアップのみ)」の1. ~ 4.と同じ手順を実施する。
# 5. 2.で圧縮退避した最新のWALを${PGDATA}/pg_walにコピーし解凍する。
[root@instance-1 ~]# cp latest_pg_wal.tar.gz /dbdata/pg_wal
[root@instance-1 ~]# cd /dbdata/pg_wal/
[root@instance-1 pg_wal]# tar xvf latest_pg_wal.tar.gz
...
[root@instance-1 pg_wal]# rm latest_pg_wal.tar.gz
# 6. ${PGDATA}にrecovery.signalというファイルを作成する。
[root@instance-1 pg_wal]# touch /dbdata/recovery.signal
# 7. ${PGDATA}配下のファイルの所有者・グループを全てpostgresにする。
[root@instance-1 pg_wal]# chown -R postgres:postgres /dbdata
# 8. DB起動
[root@instance-1 pg_wal]# systemctl start postgresql-13
これでPITRが完了しました。この状態でtest_tableの中身をのぞいてみましょう。
postgres=# select * from test_table ;
title
------------
record_001
record_002
record_003
record_004
record_005
(5 rows)
postgres=# \q
無事物理バックアップ後の2件のinsertも反映された状態になっています。
今回は特に指定していないので障害発生の直前の状態にまで戻っていますが、上記手順の「8. DB起動」の前にpostgresql.confに設定を書き込んでおくことで、物理バックアップ取得時~障害発生時の間で任意の状態に戻すことができます。
以下のいずれかを設定することができます。
| パラメータ名 | 説明 |
|---|---|
| recovery_target_name | pg_create_restore_point()で作成したリストアポイント名を指定し、そのリストアポイントまでリストアする。 |
| recovery_target_time | 指定したtimestampまでリストアする。 |
| recovery_target_xid | 指定したトランザクションIDまでリストアする。 |
| recovery_target_lsn | 指定したlsn (ログシーケンス番号。WALの位置)までリストアする。 |
なお上記のいずれかを設定してDBを起動しリストアが完了した場合、ユーザが望んだ状態にリストアができているかどうかを確認できるようにするためにRead Onlyとなります。
もし望んだ状態になっているのであれば、pg_wal_replay_resume() 関数を呼ぶことで通常通りDBが動くようになります。
注意点
アーカイブされたWALセグメントファイルはユーザが改廃しなければならない
アーカイブされたWALセグメントファイル(上記の例で言えば/backup/wal_archives配下のWAL)は改廃されません。従ってユーザが改廃を行わないと無限にWALセグメントファイルが増え続けディスクがあふれてしまいます。
アーカイブ先のディスクがあふれてしまうとarchive_commandに失敗するようになりますが、その場合PostgreSQLはpg_wal配下のWALはまだ安全な場所に退避されていないとみなし改廃を行わなくなります。
結果的にpg_walも膨らみ続け、いずれpg_walに書き込めない状態となりDBが落ちてしまいます。
PostgreSQLにはデフォルトでアーカイブされたWALセグメントファイルを削除するpg_archivecleanupというコマンドがあり、これを利用したりすると良いかもしれません。
以下のように物理バックアップ取得時にできる.backupファイルを指定すると、物理バックアップ以前の不要なWALセグメントファイルを削除することができます。(-nオプションを付けるとdry runになります)
[postgres@instance-1 ~]$ pg_archivecleanup -n /backup/wal_archives 000000010000000000000004.00000028.backup
/backup/wal_archives/000000010000000000000001
/backup/wal_archives/000000010000000000000002
/backup/wal_archives/000000010000000000000003
[postgres@instance-1 ~]$ pg_archivecleanup /backup/wal_archives 000000010000000000000004.00000028.backup
大量データ投入時に注意
大量のデータをDBにインポートすると、その分大量のWALセグメントファイルが生成・アーカイブされます。これもディスク圧迫やそれに伴うDBの停止につながる可能性がありますので、大量データ投入時は一時的にarchive_modeをoffにすると良いかもしれません。
参考
- PITRについて (公式ドキュメント)
https://www.postgresql.org/docs/13/continuous-archiving.html - WALに関するパラメータ (公式ドキュメント)
https://www.postgresql.org/docs/13/runtime-config-wal.html - pg_basebackupコマンドリファレンス (公式ドキュメント)
https://www.postgresql.org/docs/13/app-pgbasebackup.html