はじめに
SPA では JavaScript によるクライアントレンダリングを考慮しないと、すべての要素をスクレイピングすることはできない。
そのため、実際のブラウザを使ってスクレイピングを行うことになる。
これを行うデファクトライブラリの一つに、Chrome チームが公式にサポートしている Puppeteer がある。Puppeteer は Chrome DevTools Protocol を介して Chrome の操作を行うためのライブラリである。Chrome DevTools Protocol とは Chrome を操作するための Protocol であり API 定義が含まれている。例えば、特定の URL に遷移して画面を描画したり、ボタンをクリックしたり、要素の情報を抜き取ったり、スクリーンショットを取得したりできる。
ただ、Puppeteer は JavaScript のライブラリなので Go からは使えない。Go では、これに相当する公式のライブラリはないが、非公式で chromedp がある。そこで今回は chromedp の使い勝手を確認するためにサンプルアプリを作った。CircleCI 上でのスクレイピング動作のテストを含めている。
この記事では以下のバージョンを前提に書く。
- Chrome
- Version 72.0.3626.119
- chromedp
- v0.1.3
chromedp
chromedp は Chrome を Go で操作するためのライブラリである。そのため、まずは Chrome が別プロセスで立ち上がっている必要がある。その際、chromedp 経由で Chrome を新規に立ち上げることもできるし、事前に立ち上げ済みの Chrome を利用することもできる。
サーバーで動かすときには UI は必要ないので、Headless Chrome を使うことになる。Headless Chrome は UI なしの Chrome である。chromedp 経由での起動は Headless Chrome もサポートしている。
別プロセスにある Chrome とは HTTP エンドポイントを経由してやり取りを行うので、port をマッピングしておけば Docker で Chrome を立ち上げても良い。chromedp/headless-shell が用意されているのでこれを使うと楽である。
並列処理
複数の URL を並列にスクレイピングしたい場合がある。chromedp では直列処理と同じ実装のまま、並列処理を実現することはできない。 Chrome DevTools Protocol では一度に一つの URL ページの操作しかできないためである。つまり、並列に処理するためには、1 URL ごとに 1 つの Chrome を立ち上げる必要がある。
chromedp は Pool という仕組みを実装しており、これを使うのが良い。中身は、並列数分ポートを別々にした Chrome をオンデマンドで起動してそれを使って処理を行っているだけである。
結果的に並列処理を行う場合には、事前に立ち上げ済みの Chrome を利用するやり方はとれない点に注意する必要がある。Docker で Chrome を立ち上げる方法も採用できない。
サンプルアプリ
このサンプルアプリでは、StockX という靴のオークションサイトを対象とする。
具体的には、特定の靴のページにある、サイズごとの Bid 価格一覧をスクレイピングする。ワークフローは次の通り。
- https://stockx.com/buy/air-jordan-1-retro-high-og-defiant-couture にアクセスする
- 確認画面が描画されるのを待つ
- 確認ボタンを押す
- サイズと Bid 価格の一覧が描画されるのを待つ
- サイズと Bid 価格の一覧を取り出す
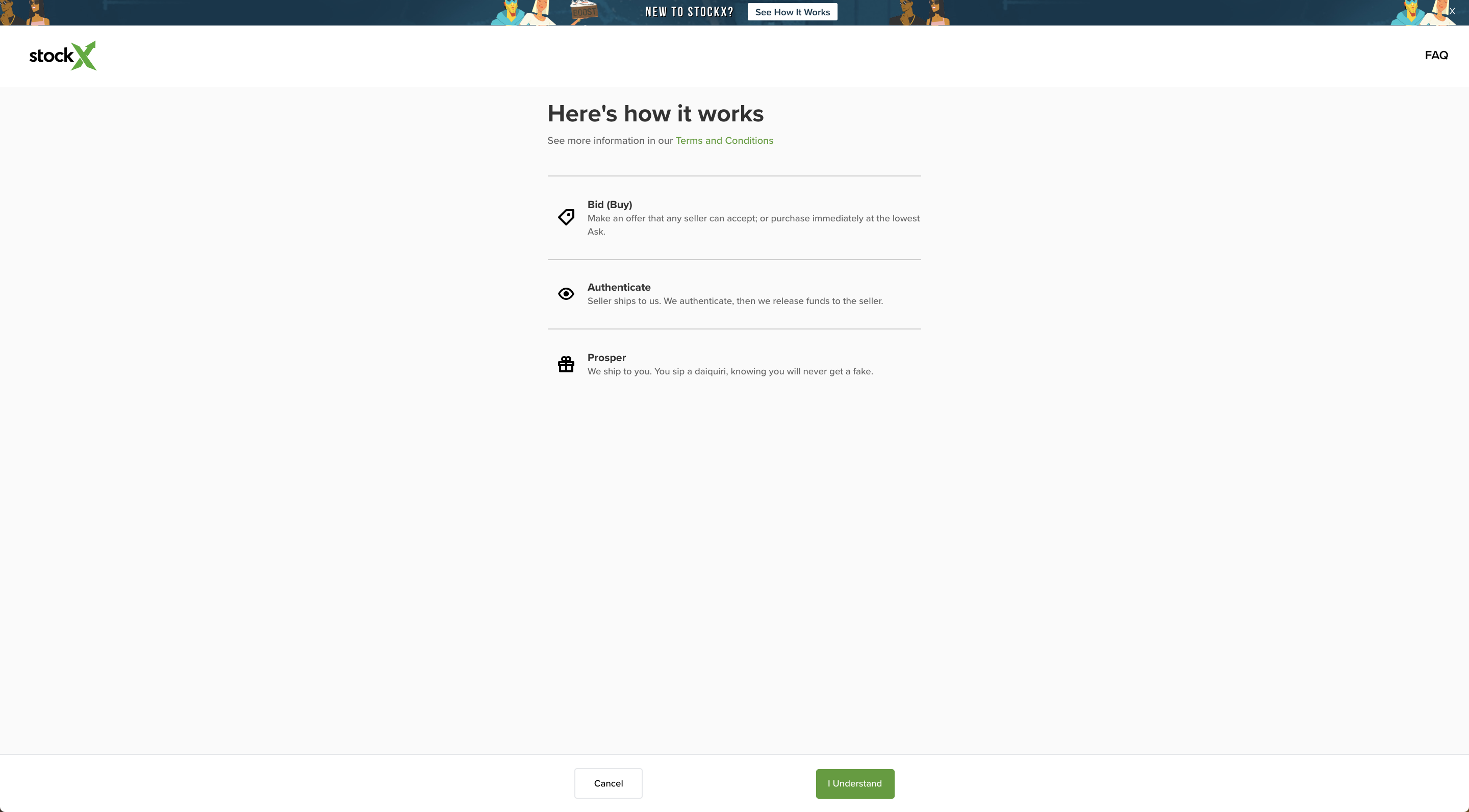
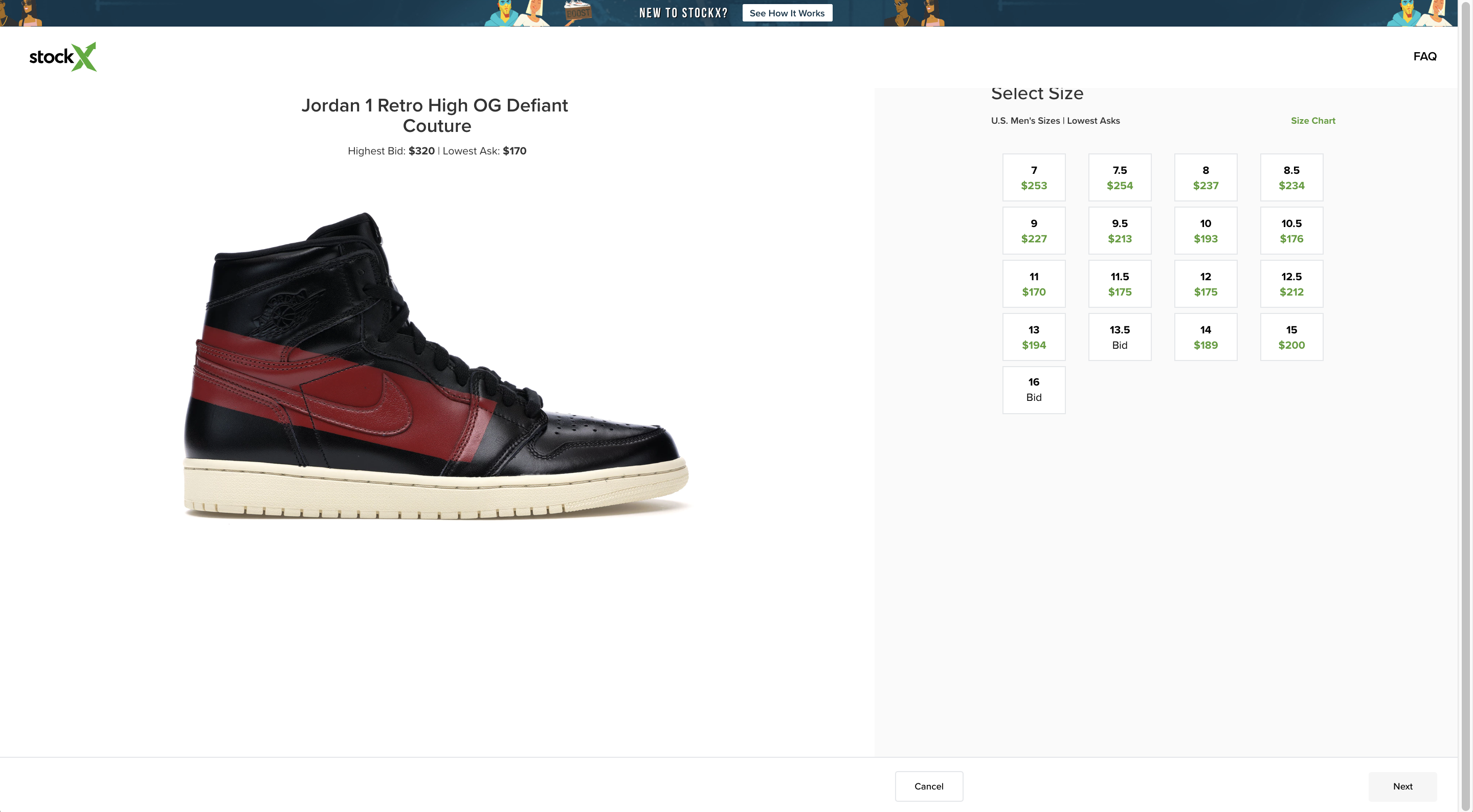
chromedp の使い方や使い勝手を把握するために、スクレイピングの実装は 3 パターン用意した。
- 上記のワークフローを順番に処理する実装
- 1 をベースにしつつ、クッキーをセットしておくことで確認画面をスキップする実装
- 1 の実装を並列に行う実装
1 と 2 は事前に Headless Chrome を Docker で立ち上げておいてそこに接続するようにしている。3 はローカルの Chrome をアプリから都度立ち上げるようにしている。
以下では chromedp を使った操作のメイン部分を抜粋(一部わかりやすさのために編集している)する。詳細は GitHub を参照。
共通するコード
前提となる靴のデータ構造は次の通り。[]*Variant をスクレイピングでとってくることになる。
type Variant struct {
Size float64
Price string
}
type Product struct {
URL string
Variants []*Variant
}
chromedp はスクレイピング結果を *cdp.Node 構造体に格納する。
ここでは *cdp.Node から text 属性を取り出している。後述の処理内で使っている、ただの utility 関数である。
func NodeValues(nodes []*cdp.Node) []string {
var vs []string
for _, n := range nodes {
vs = append(vs, n.NodeValue)
}
return vs
}
1. 直列処理
chromedp.New(ctx, chromedp.WithTargets(client.New().WatchPageTargets(ctx))) は事前に立ち上がっている Headless Chrome を操作するクライアントを生成する。
chromedp.Tasks は chromedp.Action のリストで、Run に渡すと順番にその Action が実行される。
それぞれの Action で DOM を指定する場合は、XPath を渡している。
やっていることは上のワークフローどおりである。
func ScrapeBuyShoesProduct(
ctx context.Context,
shoesURL string,
) (
*shoes.Product,
error,
) {
c, err := chromedp.New(ctx, chromedp.WithTargets(client.New().WatchPageTargets(ctx)))
if err != nil {
return nil, err
}
var sizes []*cdp.Node
var prices []*cdp.Node
confirmSel := `//*[@id="bottom-bar-root"]/div/div/button[2]`
sizesSel := `//div[@class='tile-inner']/div[@class='tile-value']`
sizeTextsSel := sizesSel + `/text()`
priceTextsSel := `//div[@class='tile-inner']/div[@class='tile-subvalue']/div/text()`
err := c.Run(ctx, chromedp.Tasks{
chromedp.Navigate(shoesURL),
chromedp.WaitVisible(confirmSel),
chromedp.Click(confirmSel),
chromedp.WaitVisible(sizesSel),
chromedp.Nodes(sizeTextsSel, &sizes),
chromedp.Nodes(priceTextsSel, &prices),
})
if err != nil {
return nil, err
}
variants, err := shoes.NewVariants(
expchromedp.NodeValues(sizes),
expchromedp.NodeValues(prices),
)
if err != nil {
return nil, err
}
return &shoes.Product{
URL: shoesURL,
Variants: variants,
}, nil
}
2. 直列処理+クッキーセット
1 と違うのは chromedp.Tasks の中身。
最初のアクションはクッキーをセットしている。
stockx_seen_bid_new_info=true がセットされていると、確認画面が出てこなくなるので、そのあとの画面遷移のためのクリックアクションはスキップしている。
func ScrapeBuyShoesProduct (
ctx context.Context,
shoesURL string,
) (
*shoes.Product,
error,
) {
c, err := chromedp.New(ctx, chromedp.WithTargets(client.New().WatchPageTargets(ctx)))
if err != nil {
return nil, err
}
u, err := url.Parse(shoesURL)
if err != nil {
return nil, err
}
var sizes []*cdp.Node
var prices []*cdp.Node
sizesSel := `//div[@class='tile-inner']/div[@class='tile-value']`
sizeTextsSel := sizesSel + `/text()`
priceTextsSel := `//div[@class='tile-inner']/div[@class='tile-subvalue']/div/text()`
err = c.Run(ctx, chromedp.Tasks{
chromedp.ActionFunc(func(ctxt context.Context, h cdp.Executor) error {
success, err := network.SetCookie("stockx_seen_bid_new_info", "true").
WithDomain(u.Hostname()).
Do(ctxt, h)
if err != nil {
return err
}
if !success {
return fmt.Errorf("could not set cookie")
}
return nil
}),
chromedp.Navigate(shoesURL),
chromedp.WaitVisible(sizesSel),
chromedp.Nodes(sizeTextsSel, &sizes),
chromedp.Nodes(priceTextsSel, &prices),
})
variants, err := shoes.NewVariants(
expchromedp.NodeValues(sizes),
expchromedp.NodeValues(prices),
)
if err != nil {
return nil, err
}
return &shoes.Product{
URL: shoesURL,
Variants: variants,
}, nil
}
3. 並列処理
複数の URL を引数にとって、それぞれに対応する靴のスライスを返すようにするのでシグネチャが少し変わる。
chromedp.Tasks の中身は同じで、Run を実行する主体の生成・管理の方法が違う。
goroutine 内で、chromedp.Pool の Allocate メソッドを呼ぶことで並列数分の Headless Chrome を立ち上げる。
func ScrapeBuyShoesProducts(
ctx context.Context,
shoesURLs []string,
) (
[]*shoes.Product,
error,
) {
// create pool
pool, err := chromedp.NewPool(c.poolOptions()...)
if err != nil {
return nil, err
}
// shutdown pool
defer func() {
serr := pool.Shutdown()
if err == nil && serr != nil {
err = serr
}
}()
// loop over the URLs
productChan := make(chan *shoes.Product, len(shoesURLs))
eg := errgroup.Group{}
for _, url := range shoesURLs {
url := url
eg.Go(func() error {
vs, err2 := scrapeBuyShoesVariants(
ctx,
pool,
url,
)
if err2 != nil {
return err2
}
productChan <- &shoes.Product{
URL: url,
Variants: vs,
}
return nil
})
}
// wait for to finish
if err = eg.Wait(); err != nil {
return nil, err
}
var products []*shoes.Product
for p := range productChan {
products = append(products, p)
if len(products) == len(shoesURLs) {
break
}
}
close(productChan)
return products, nil
}
func scrapeBuyShoesVariants(
ctx context.Context,
pool *chromedp.Pool,
shoesURL string,
) (
_ []*shoes.Variant,
err error,
) {
// allocate
r, err := pool.Allocate(ctx)
if err != nil {
return nil, fmt.Errorf("url `%s` error: %v", shoesURL, err)
}
defer func() {
_ = r.Release()
}()
// run tasks
var sizes []*cdp.Node
var prices []*cdp.Node
confirmSel := `//*[@id="bottom-bar-root"]/div/div/button[2]`
sizesSel := `//div[@class='tile-inner']/div[@class='tile-value']`
sizeTextsSel := sizesSel + `/text()`
priceTextsSel := `//div[@class='tile-inner']/div[@class='tile-subvalue']/div/text()`
err = r.Run(ctx, chromedp.Tasks{
chromedp.Navigate(shoesURL),
chromedp.WaitVisible(confirmSel),
chromedp.Click(confirmSel),
chromedp.WaitVisible(sizesSel),
chromedp.Nodes(sizeTextsSel, &sizes),
chromedp.Nodes(priceTextsSel, &prices),
})
if err != nil {
return nil, err
}
return shoes.NewVariants(
expchromedp.NodeValues(sizes),
expchromedp.NodeValues(prices),
)
}
それぞれの実行時間
テストは上記をほぼそのまま動かしているので、テストの実行時間はほぼスクレイピング時間と考えてもいいと思う。
見て分かる通り、実行時間はばらばらで、事前に chrome を立ち上げておいたから早いというわけでもない。
大雑把には、1 度のスクレイピングには 10 秒くらいは見ておいたほうが良さそう(接続先のレスポンスタイムによるが)。
--- PASS: TestApp_GetBuyShoes (62.10s)
# 1 のテスト
--- PASS: TestApp_GetBuyShoes/Got_1_url (11.31s)
--- PASS: TestApp_GetBuyShoes/Got_2_urls (4.27s)
# 2 のテスト
--- PASS: TestApp_GetBuyShoes/Got_1_url_with_the_cookie_to_skip_the_confirmation_page (1.61s)
--- PASS: TestApp_GetBuyShoes/Got_2_urls_with_the_cookie_to_skip_the_confirmation_page (21.50s)
# 3 のテスト
--- PASS: TestApp_GetBuyShoes/Got_1_url_with_parallel_mode (11.61s)
--- PASS: TestApp_GetBuyShoes/Got_2_urls_with_parallel_mode (11.71s)
- ref.
まとめ
- chromedp は Go で使える Puppeteer のようなもの
- chromedp のインターフェースはタスクを並べてシーケンシャルに実行を命令するというもので、わかりやすく読みやすい
- 並列実行するには Pool を使ってオンデマンドで Chrome を立ち上げる必要がある。その場合、Docker で Chrome を立てておくという方法は採用できない。
- 実行速度にはボラティリティがかなりあり、 10 秒近くかかることは見込む必要がある。JavaScript の解釈が必要ないところでは、素朴に HTML をダウンロードして、Headless Chrome は補完的に使うのが現実的。
参考
Getting Started with Headless Chrome | Web | Google Developers
Chrome DevTools Protocol Viewer
chromedp/chromedp: A faster, simpler way to drive browsers supporting the Chrome DevTools Protocol.