目的
お客様向け勉強会を行う中で再度整理したいと思った部分をまとめます。
前提知識
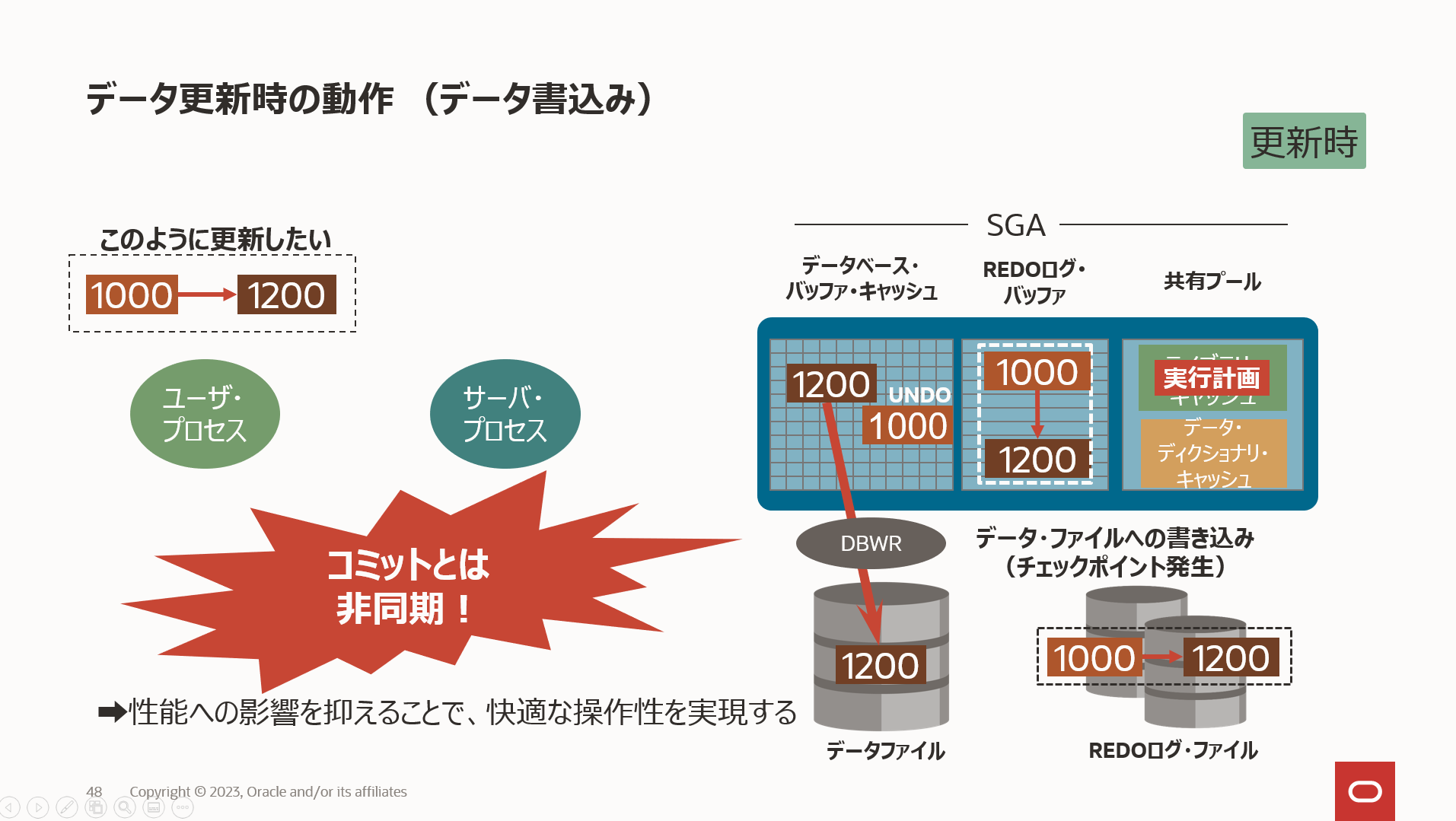
チェックポイントは以下の2つの意味を持っている。
https://docs.oracle.com/cd/F19136_01/cncpt/oracle-database-instance.html#GUID-A6959126-0ECF-40A2-880D-D74A1BFB5BC4
①チェックポイント位置を示すデータ構造。これは、インスタンス・リカバリを開始する必要があるREDOストリーム内のSCNです。
チェックポイント位置は、データベース・バッファ・キャッシュ内の最も古い使用済バッファによって決まります。チェックポイント位置は、REDOストリームへのポインタとして機能し、制御ファイル内と各データファイル・ヘッダー内に格納されます。
②データベース・バッファ・キャッシュ内の変更済データベース・バッファのディスクへの書込み
REDOログファイルへの書き込み(コミット)とデータファイルへの書き込み(チェックポイント)を非同期にすることによって、性能への影響を抑えてアプリケーションの快適な操作性を実現している。
チェックポイントのタイミングについて
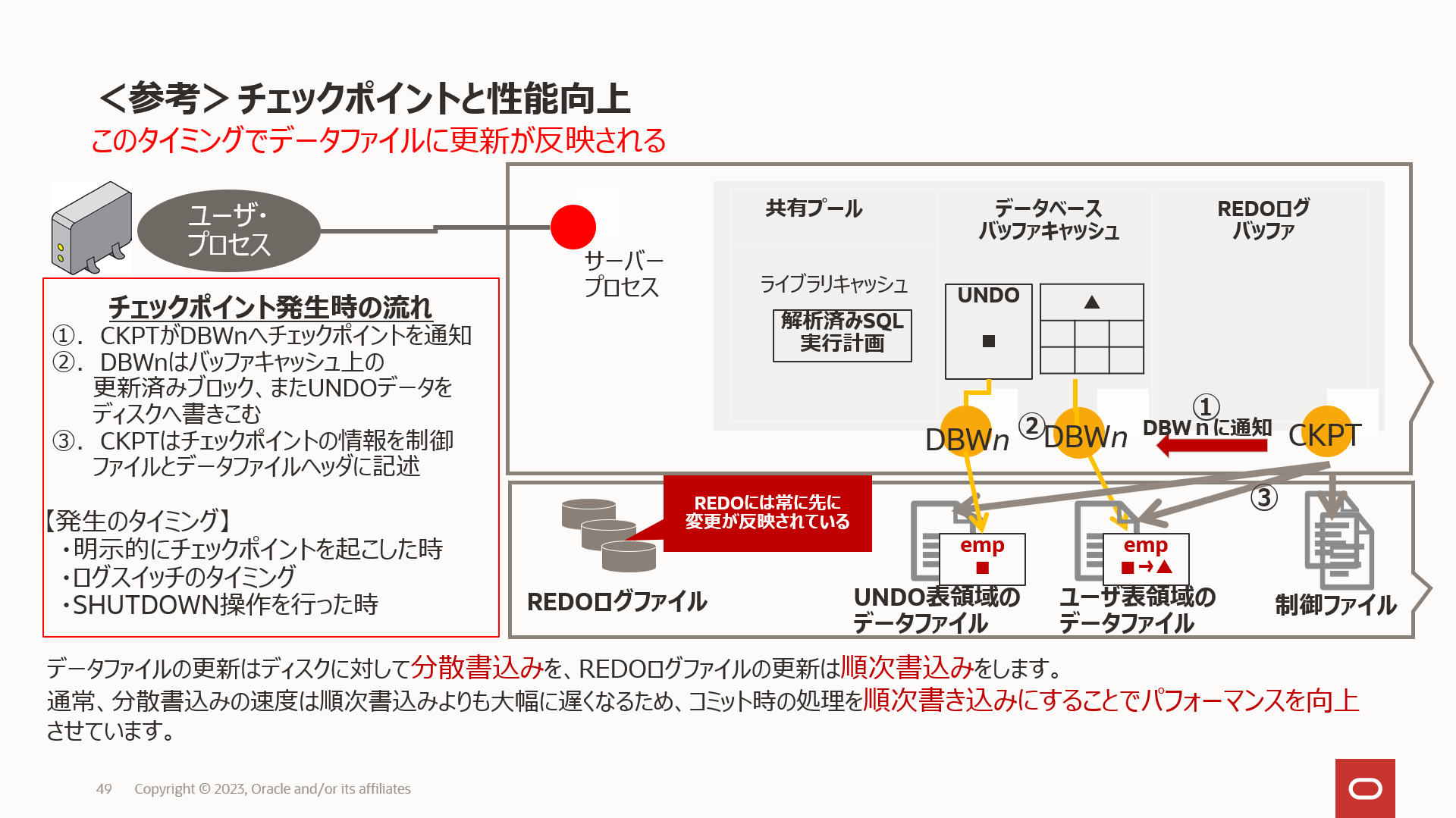
1. 明示的にチェックポイントを起こした時
ALTER SYSTEM CHECKPOINTコマンドで手動チェックポイントを発生させることができる
https://docs.oracle.com/cd/F19136_01/sqlrf/ALTER-SYSTEM.html#GUID-2C638517-D73A-41CA-9D8E-A62D1A0B7ADB
・ALTER SYSTEM CHECKPOINT GLOBAL
⇒Oracle Real Application Clusters (Oracle RAC)環境で、データベースをオープンしているすべてのインスタンスに対してチェックポイントを実行します。
・ALTER SYSTEM CHECKPOINT LOCAL
⇒Oracle RAC環境で、文を発行するインスタンスのREDOログ・ファイル・グループのスレッドに対してのみチェックポイントを実行します
他にも以下の初期化パラメータを利用してチェックポイントを起こす方法もある。
・LOG_CHECKPOINT_INTERVAL
https://docs.oracle.com/cd/F19136_01/refrn/LOG_CHECKPOINT_INTERVAL.html#GUID-2AD1BEC0-B768-4CD6-A630-9570F358C3DF
・LOG_CHECKPOINT_TIMEOUT
https://docs.oracle.com/cd/F19136_01/refrn/LOG_CHECKPOINT_TIMEOUT.html#GUID-2FB2D347-82B8-4F15-9B47-8F75E9383A79
・FAST_START_MTTR_TARGET
https://docs.oracle.com/cd/F19136_01/refrn/FAST_START_MTTR_TARGET.html
どんな時に明示的にチェックポイントを起こすのか?
メディア障害からのリカバリ・テストのように、データファイルへのアクセスを伴う動作検証を行う場合や、オンラインREDO ログ・ファイルのメンテナンスを行うときなどに、手動でチェックポイントを発生させることが考えられる。
また、推奨のREDOログスイッチ間隔は1時間に2回前後程度。checkpointが頻繁に発生する場合はREDOログファイルのグループ数を増やすかサイズを大きくすることで発生を抑えることを考えましょう。
2. ログスイッチのタイミング
現行のREDOログ・ファイル・グループが一杯になると、ログ・スイッチが自動的に発生する。
REDOログのメンテナンス操作を実行するために、ログ・スイッチを強制的に発生させて、現在アクティブなグループを非アクティブの状態に手動で変更することもできる。
具体的にはALTER SYSTEM SWITCH LOGFILEもしくはALTER SYSTEM ARCHIVE LOG CURRENTで行う。
指定した時間間隔でログ・スイッチを強制する ARCHIVE_LAG_TARGETという初期化パラメータも活用できる。
https://docs.oracle.com/cd/E82638_01/refrn/ARCHIVE_LAG_TARGET.html#GUID-405D335F-5549-4E02-AFB9-434A24465F0B
3. SHUTDOWN操作を行った時
ただし、SHUTDOWN ABORT時には、チェックポイントが発生しないまま、shutdown状態に移行する