3行まとめ
- Recurrent Neural Networkによるかな漢字変換をTensorFlowを使って実装しました。
- 既存手法のN-gramと比べて高い精度(文正解率2.7ポイント向上・予測変換3.8ポイント向上)を実現しました。
- RNNの特性により離れた単語の共起関係と低頻度語の扱いが改善されました。
かな漢字変換とN-gramモデルの限界

パソコンやスマートフォンで日本語を入力するためのかな漢字変換には、同音異義語や単語区切りに曖昧さがあります。この問題に対処するため、現在は大規模な訓練データに基づく統計的言語モデルが主流になりました。その中でも代表的な単語のN-gramモデル1では、連続する単語列の頻度を使って言語モデルを構成し、変換候補の確率が高いほど順位が高いと考えます。
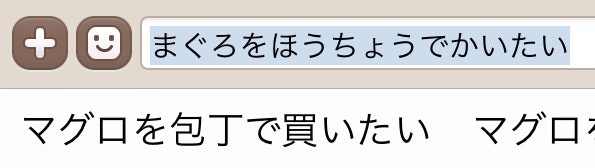
しかし、N-gramモデルには離れた単語の共起関係を考慮できないという問題点(マルコフ性)と、低頻度語の文脈が考慮されない(スパースネス)という問題点があります。例えば上のスクリーンショットはGoogle日本語入力(2.10)とiPhoneの日本語入力(10.1)の誤変換を示していて、「猫を飼いたい」が「猫を解体」に、「マグロを包丁で解体」が「マグロを包丁で買いたい」にそれぞれ誤変換されています2。これらの問題点を改善するため、Recurrent Neural Networkを言語モデルとして用いたニューラルかな漢字変換を提案します。
Recurrent Neural Network(RNN)言語モデルとは
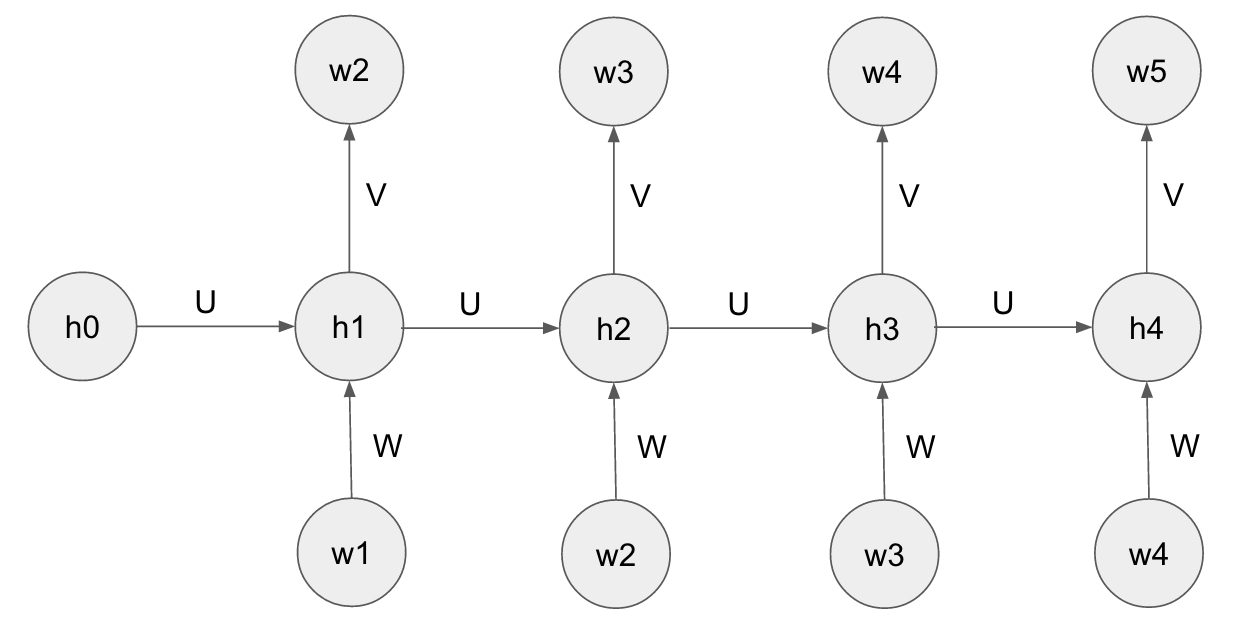
RNNは系列データに適したニューラルネットワークで、ここでは最も簡単なMikolovらのRNN言語モデルを紹介します。3 このモデルでは一つの文を長さ$T$の単語を表す整数(単語IDと呼びます)の系列$w=\lbrace w_1, w_2, ...w_{T}\rbrace $として表します。4語彙数を$D$とすると、$1 \le w_t \le D$が成り立ちます。次に隠れユニットの系列を$h_0, h_1, ...h_T$(ただし$h_t\in\mathbb{R}^H$)で表し、初期値を$h_0=0$とします。するとMikolovのRNN言語モデルは2つの数式で表されます。
h_{t} = {\rm tanh}(U h_{t-1} + W[w_t]) \\
P(w_{t+1}|w_{<t+1};U,W,V) = {\rm softmax}(V h_t)[w_{t+1}]
ここで行列$U\in\mathbb{R}^{H\times H}$、$W\in\mathbb{R}^{H\times D}$、$V\in\mathbb{R}^{D\times H}$は訓練可能なパラメータで、$U$は状態遷移を、$W$は単語の埋め込みを、$V$は最終出力をコントロールしています。これらのパラメータは時間$t$に依存せず、すべての時刻で共有されていることに注意してください。$W[w_t]$は行列$W$の$w_t$番目の列ベクトルで、単語$w_t$を表すことから単語ベクトルと呼ばれています。5最後の$P(w_{t+1}|w_{<t+1};U,W,V)$はそれまでの文脈$w_{<t+1}$を与えられたときの次の単語$w_{t+1}$の予測確率で、$D$次元ベクトル${\rm softmax}(V h_t)$の$w_{t+1}$番目の要素で表されます。
パラメータ学習の目的は、訓練データに対するクロスエントロピーを最小化することです。訓練データ中の文$w$が与えられた場合の目的関数は以下の数式になります。
J(U,W,V;w) = -\sum_{t=2}^T \rm{log}P(w_t|w_{<t};U,W,V)
この目的関数を最小化するために、以下の擬似コードで示した確率的勾配降下法を実行すると最適なパラメータが求まります。
Input: training_data, num_epoch, learning_rate
Initialize U, W, V to small random values
for epoch := 1 to num_epoch do
for each w in training_data do
U, W, V -= learning_rate * gradient(U, W, V, w)
end
end
return U, W, V
training_dataは訓練データ中の文$w$のリスト、num_epochは学習の回数(エポックと呼びます)、learning_rateは小さな正の数で学習率と呼びます。関数gradientは目的関数の勾配ベクトル$\nabla_{U,W,V} J(U,W,V;w)$を返します。この勾配ベクトルは数式として書き下ろすとやや複雑になりますが、TensorFlowなどの自動微分をサポートするフレームワークを使えば簡単に計算できます。
このように学習したパラメータを使って文脈が与えられたときの単語の確率が高い順に単語を順位付けすると、次単語予測(入力がないときの予測変換)を実装することができます。しかしどうやってかな漢字変換に適用するかは自明ではありません。
RNN言語モデルによるかな漢字変換
RNNに訓練データとして単語列の代わりに単語の表記$y_t$と読み仮名$x_t$のペアの系列$w=\lbrace(y_1,x_1),...(y_T,x_T)\rbrace$を与えると、Joint Source Channel Modelと呼ばれる種類の言語モデルが得られます。67 かな漢字変換のゴールはこうして訓練した言語モデルのもとで、読み仮名$x$が与えられたときに最も確率の高い漢字仮名交じり文$\hat{y}$を見つけることです。
\hat{y} = \underset{y}{\rm argmax} \prod_{t=2}^T P(y_t,x_t|y_{<t},x_{<t};U,W,V)
ただし$x$の単語分割方法は与えられていないので、$\lbrace x_1..x_T \rbrace \in {\rm split}(x)$を満たすような$x$の中を探す必要があります。また、訓練データ中にない単語の表記と読み仮名の組み合わせは無視します。
この探索空間を愚直に全探索すると入力の長さに対して指数的に計算量が増加して時間がかかりすぎるため、枝刈りをしながら幅優先探索をするビームサーチが必要になります。8 以下にこのアルゴリズムの擬似コードを示します。
Input: x, model, dictionary, beam_size
Initialize queues to list of empty queues of size x.length
queues[1].add(new Hypothesis(1.0, zero_vector, uniform_distribution, [])
for i := 2 to x.length do
for j := 1 to i - 1 do
key = x.substring(j, i)
results = dictionary.lookup(key)
for each word_id in results do
previous_hypotheses = queues[j]
for each hypothesis in previous_hypotheses do
probability = hypothesis.probability * hypothesis.prediction[word_id]
prediction, state = model.predict(word_id, hypothesis.state)
word_ids = hypothesis.word_ids + word_id
new_hypothesis = new Hypothesis(probability, state, prediction, word_ids)
queues[i].add(new_hypothesis)
end
end
end
Prune queues[i] to most probable hypotheses of beam_size
end
return queues[x.length].top_hypothesis()
xは入力の読み仮名文字列、modelは訓練済みのRNNモデル、dictionaryは訓練データ中の単語を格納した辞書、beam_sizeは枝刈りに使うパラメータです。関数dictionary.lookupは読み仮名で辞書を引いてマッチする単語のIDのリストを返します。関数model.predictは現在の単語のID$w_t$と隠れユニットの値$h_{t-1}$を受け取って次の単語の確率分布${\rm softmax}(V h_t)$と次の隠れユニットの値$h_t$を返します。9
ちょっとややこしいですね。このアルゴリズムは入力文字列を左から順番に辞書引きしていって、途中の変換候補を確率の高い順に残しておくように動作します。例として「きょうのてんき」という入力文字列を与えられたときのビームサーチの様子を見てみましょう。

なんとなく雰囲気はつかめたかなと思います。
比較実験
RNNとN-gramを比較するため、国立国語研究所の現代日本語書き言葉均衡コーパス(BCCWJ)を使って両モデルの訓練と評価を行いました。10 BCCWJのコアデータは約6万文からなるタグ付きデータで、かな漢字変換モデルの訓練に必要な単語の境界と読み仮名が含まれています。このデータをシャッフルして89%を訓練用、10%を評価用、1%を検証用に使いました。両モデルとも訓練データ中の全ての語彙($D$=約5万語)を使って訓練しました。
RNNのモデルはTensorFlowのチュートリアルにもなっているZarembaらの設定11をもとに、セルにはGRU12、最適化はADAM13、隠れ層のサイズ$H$は400、Dropout14の確率は0.5、エポック数は10、バッチサイズは50、ステップ数は30、勾配クリッピングは5に設定しました。訓練にはAWSのp2.xlargeインスタンスで1時間ほどかかりました。N-gramのモデルはSRILMを使って訓練し、Modified Kneser-Neyで平滑化し15、N-gramの次数はかな漢字変換ではN=2、予測変換ではN=4としました。16 公平を期すため両モデルの探索にビームサイズ5の枝刈りを適用しました。
評価指標は文正解率と予測正解率の2つで、どちらも評価用データを使って計算しました。文正解率は文全体を一発変換したときの評価データとの一致率で、BCCWJの一文は平均23語というかなりの長文なのと表記ゆれのような些細な違いも不正解とみなすため挑戦的なタスクになっています。予測正解率は文中の単語ごとの次単語予測の第一候補との一致率で、単語の長さや部分文字列の一致は考慮していません。
以上の設定でRNNとN-gramを比較した結果を示します。
| 評価指標 | N-gram | RNN |
|---|---|---|
| 文正解率 | 41.5% | 44.2% |
| 予測正解率 | 22.9% | 26.7% |
RNNがN-gramよりもかな漢字変換と予測変換の精度において勝ることが確認できました(ほっ)。
隠れ層のサイズによる影響
RNNモデルにおいて最適な隠れ層のサイズを見つけるため、他の条件を固定して隠れ層のサイズを変化させ、検証データにおける文正解率への影響を調べました。18
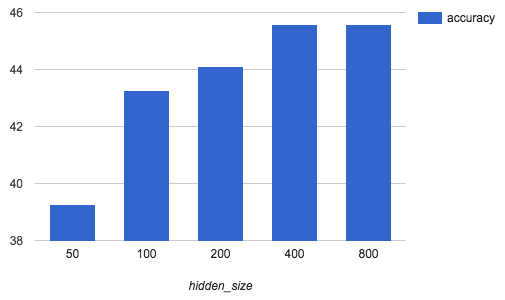
隠れ層のサイズを指数的に大きくしているにも関わらず、文正解率は飽和してしまいました。モデルサイズは大まかに隠れ層のサイズと語彙数の積に比例するので、変換精度とのトレードオフを考慮して決める必要があります。
Dropoutによる影響
RNNの入力層と出力層にDropoutを適用する方法はZarembaらによって提案され、過学習を防ぐために重要なテクニックとされています。ここではDropoutの影響を調べるため、Dropoutなしの場合と比べて学習中の検証データに対する変換精度がどう変化するか調べました。
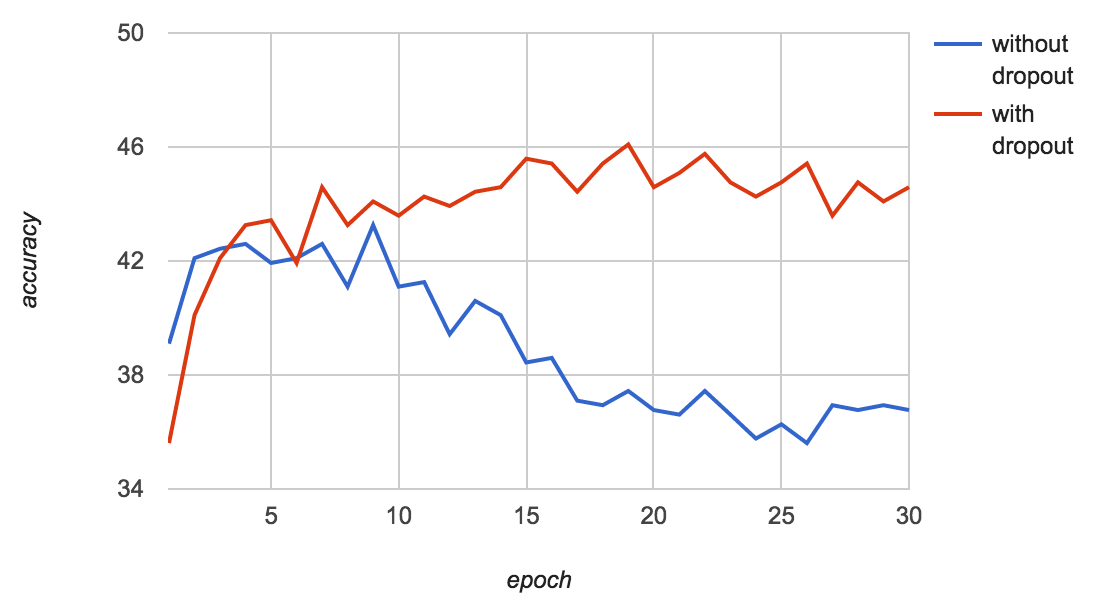
図を見るとDropoutなしの場合は3エポック目で学習が停滞し10エポック目から急激に精度が落ちていくのに対し、Dropoutありの場合は最初こそ学習が遅いものの3エポック後もゆるやかに上昇し続けてやがて飽和するのがわかります。どちらも訓練データは高い精度で変換できているので、Dropoutなしの場合は過学習を起こしていることになります。
誤変換の分析
以下に誤変換などでN-gramとRNNで異なる変換をした例を載せます。19 なおBCCWJは新聞記事や小説などを含む比較的小規模なコーパスなので、訓練データの分野に偏りがあることに留意してください。
| 読み仮名 | N-gram | RNN | 備考 |
|---|---|---|---|
| きょうのてんきは | 今日の転機は | 今日の天気は | 同音異義語の選択ミス |
| かんじをへんかん | 漢字を返還 | 漢字を変換 | 「領土を返還」はどちらも変換可能 |
| ほそくなりたい | 補足なりたい | 細くなりたい | 隠れ層が品詞を学習した? |
| はがいたい | 歯が遺体 | 歯が痛い | 単語の共起関係を学習した? |
| ほんをかいたい | 本を解体 | 本を買いたい | 単語の共起関係を学習した? |
| りえきなどこうちょう | 利益など校長 | 利益など好調 | トピック=経済を学習した? |
| きょじんにせんせい | 巨人に先生 | 巨人に先制 | トピック=野球を学習した? |
このようにRNNは単語の共起関係や品詞、トピックなどN-gramでは扱えない現象を捉えているらしいことがわかりました。
おわりに
RNN言語モデルを用いたニューラルかな漢字変換を実装し、N-gramと比べて精度が高いことを確認しました。今回実装したモデルは2016年現在においては基本的なもので、もっと精度の高いモデルは多く提案されています。20 一方でかな漢字変換はモバイル端末など制約の多い環境で高速に動作する必要があり、速度やメモリの点で工夫が必要になってきます。コーパスや辞書の地道な改善と合わせて、今後の研究・実用化が待たれるところです。
12月14日追記:今回の実装をオープンソースソフトウェアとして公開しました。
Neural IME: Neural Input Method Engine
-
多くの実用システムでは品詞の情報も使っていますが、複雑になるためここでは考慮しません。 ↩
-
「マグロを解体」は変換できました。 ↩
-
Tomas Mikolov, Recurrent neural network based language model, 2010. ↩
-
文頭と文末に特殊記号を導入することもあります。 ↩
-
単語ベクトルの表引きはone hot vectorを使って線形変換$W \bf{1}(w_t)$で表すことができます。 ↩
-
Haizhou et al., A Joint Source-Channel Model for Machine Transliteration, 2004. ↩
-
Noisy Channel Modelが使われることもありますが、精度は同程度かやや低いようです。 ↩
-
ビームサーチは機械翻訳や音声認識でもよく使われています。なおビームとは建築の梁のことです。 ↩
-
関数
model.predictの計算量は$O(DH)$で、探索のボトルネックになります。 ↩ -
BCCWJのコアデータははTSV形式とXML形式がありますが、TSV形式には音声認識用のよみがなしかないのでXML形式を使っています。TSV形式とXML形式で実験結果がかなり違うのですが理由は謎。 ↩
-
Zaremba et al., Recurrent Neural Network Regularization, 2014. ↩
-
Chung et al., Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling, 2014. ↩
-
Kingma et al., Adam: A Method for Stochastic Optimization, 2014. ↩
-
Srivastava et al., Dropout: A Simple Way to Prevent Neural Networks from Overfitting, 2014. ↩
-
Chen and Goodman, An Empirical Study of Smoothing Techniques for Language Modeling, 1996. ↩
-
このデータだとかな漢字変換はN=3以上にしても精度が上がらないことが実験により確かめられています。詳しくは私の論文17を参照ください。(ドヤァ ↩
-
Yoh Okuno and Shinsuke Mori, An Ensemble Model of Word-based and Character-based Models for Japanese and Chinese Input Method, 2012. ↩
-
実験時間を短縮するため検証データは小さめ(601文)にしました。 ↩
-
双方向RNN、ResNet、アンサンブル/モデル平均、文字/サブワードRNNなど。 ↩