はじめに
この度BigQueryを使う機会があり、その際調べたことをまとめてみました。
主に公式のドキュメントと、BigQuery Admin reference guideからの抜粋です。
RDSはある程度触っていて、これからBigQueryを使おうという方向けです。
【知識編】BigQueryの仕組みについて知っておきたいこと
筆者は多少のRDBの利用経験があったので「ふむふむ標準SQL使えるのね、RDBと似たような感じかな」くらいに思っていたのですが実際は全然違いました、すいません。
BigQueryはカラムストレージ
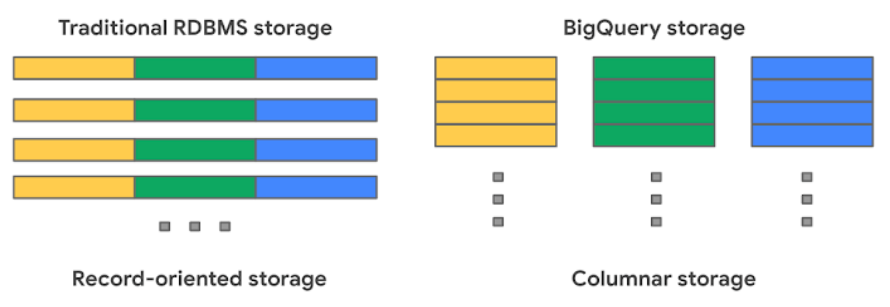
参考:BigQuery Admin reference guide: Storage internals
BigQueryを扱う上でまず押さえたいのはデータの保存方法です。上図の通り、
- 個々のカラムのデータは別々のファイルブロックに保存される
- クエリが参照するカラムの数が実行時に参照されるファイルの数に比例する
という特徴があります。これはクエリのパフォーマンス、コストを考えるうえでとても重要なことです。
Queryは分割され、並列処理される
JobとSlotという概念があります。SlotとはCPU、メモリ、ネットワークなどの演算に必要なリソースの単位です。
- BigQueryに対する操作(Load, Query, Copy, Export)が行われると、Jobが作成される
- Jobは非同期、並列に実行される
- 各Jobにはslotと呼ばれる演算単位が割り当てられる
- オンデマンド課金ではプロジェクトごとに 2,000 slot が割り当てられている
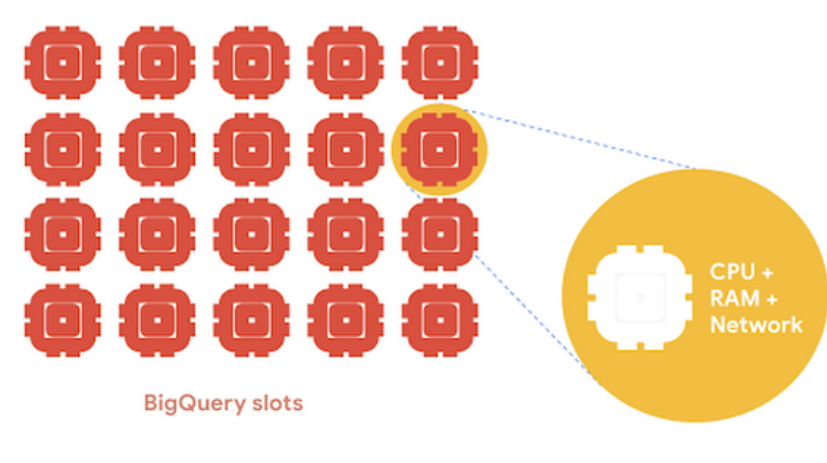
参考:BigQuery Admin reference guide: Jobs & reservation model
Jobはさらに小さいステージに分割されて処理されます。
- QueryはBigQueryのQuery Engin
Dremelによって処理される -
Dremelはワーカーのクラスター - Queryは小さなステージに分解されてワーカーによって並列に処理される
- ワーカーが作成する中間データは
memory shuffleに保持される - ステージ数に対してワーカー(Slot)数が不足するとクエリが遅くなる
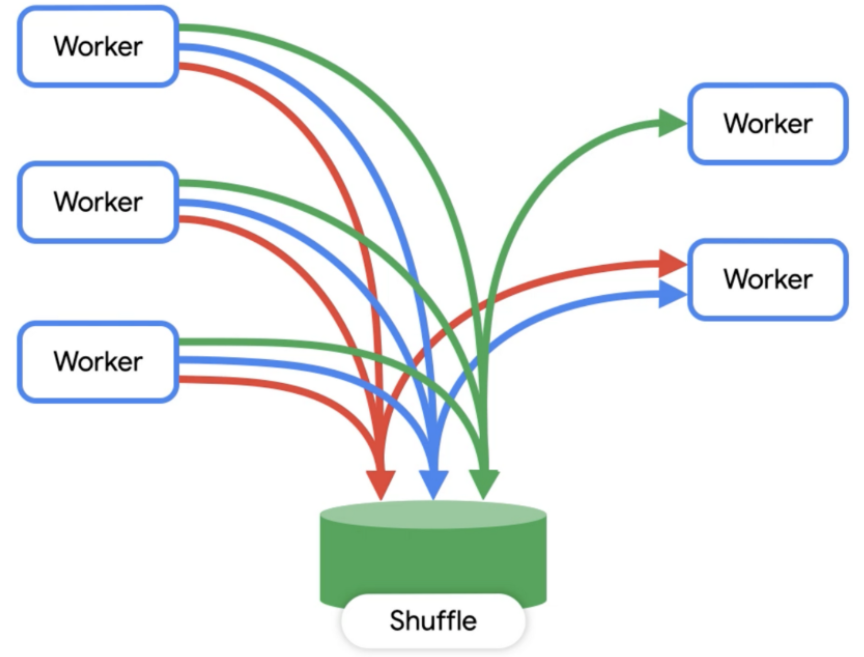
参考:BigQuery Admin reference guide: Query processing
date カラムを持つ sample_table テーブルから特定の期間のレコードの件数を取得する以下のクエリの実行結果を見てみます。
SELECT
count(date)
FROM
`test_dataset.sample_table`
WHERE
date BETWEEN '2021-01-01' AND '2021-08-30'
;
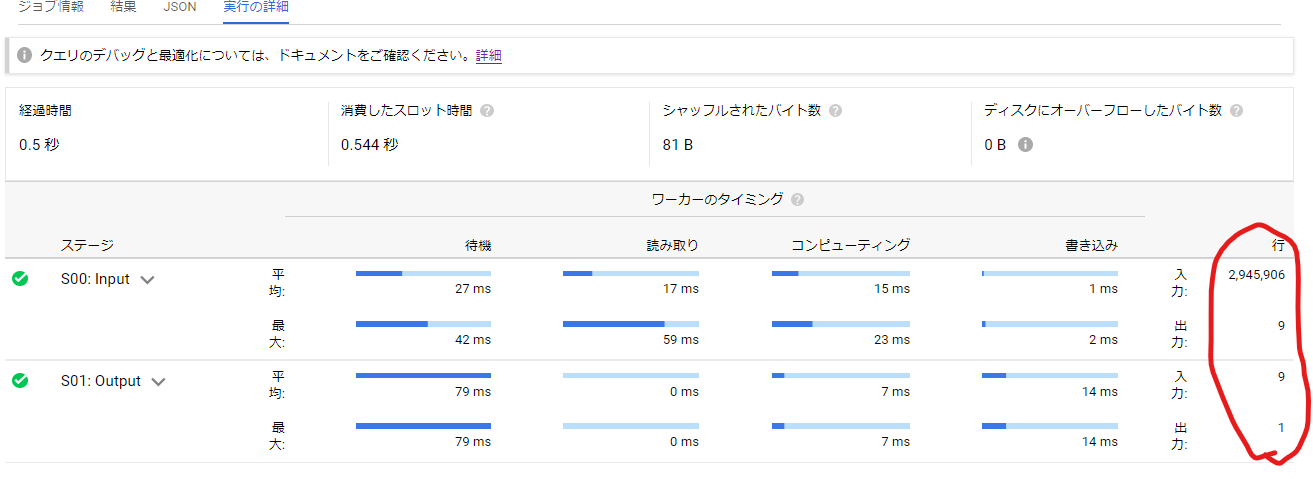
赤枠でマークしたところを確認してください。
最初のステージ (S00)では入力が約300万レコード、出力が「9」となっています。次のステージ (S01)では入力が「9」、出力が「1」となっていますね。先ほどの説明と照らし合わせると以下のことが起こっています。
- WHERE句の絞り込み条件に該当する約300万レコードのファイルが、9個のワーカーによって並行にreadされる(おそらく9つの別々のファイルブロックに格納されているのでしょう)。
- それぞれのワーカーが自分がreadしたレコードの数をcountして、memory shufullにwtire(
S00の出力9) - すべてのワーカーの書き込みが終わったら次のステージ(
S01)が開始して、(S00)でwriteされた結果をmemory shufullからread(S01の入力9) - 前のステージで独自に計算された9つのcountをすべて合計して、最終結果としてwrite(
S01の出力1)
実行の詳細と統計情報を見よう
前項でも触れた実行の詳細では各ステージが何にどのくらい時間を使ったかを確認でき、スロークエリを分析するときにヒントになりそうです。
- Wait
- ワーカーが空くのを待っている
- 依存関係がある他のステージが終わるのを待っている
- → Slot数を増やす
- Read
- 参照先のテーブル、もしくは前のステージで書き込まれたmemory shufullからデータを読み込んでいる
- → limit や 絞り込みで読み込むファイルの数を減らす(参照するデータを減らす)
- 参照先のテーブル、もしくは前のステージで書き込まれたmemory shufullからデータを読み込んでいる
- Compute Phase
- 演算している
- → 近似関数を利用する、コストが高い文字列操作などを調整する
- 演算している
- Write
- memory shufull化永続ストレージ(ユーザに結果を返すために書き込むストレージ)に書き込んでいる
- → クエリで取得するデータを減らす
- memory shufull化永続ストレージ(ユーザに結果を返すために書き込むストレージ)に書き込んでいる
また、INFORMATION SCHEMA を参照することでより詳細な実行の結果を確認できます。
たとえば JOBS_BY_PROJECT から特定のアカウントが実行したクエリの概要を取得する場合は以下のようになります。
(region は東京なら region-asia-northeast1 です。)
SELECT
job_id
,cache_hit
,creation_time
,start_time
,query
,referenced_tables
,total_bytes_processed
,total_slot_ms
,timeline
,job_stages
FROM
`your_project`.`project_region`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
user_email = 'your_account_mail'
ORDER BY
start_time DESC
;
【実践編】テーブルの設計やクエリ実行時に知っておきたいこと
BigQueryに対してQueryを実行した場合、読み込まれたデータの量に対して課金されます。また、読み込まれるデータが多くなると演算や途中の書き込みにかかる時間も多くなり結果的にクエリが遅くなります。UX的にもお財布的に もとにかく早い段階で取り扱うデータの量を絞ることが大事 と思われます。
参照するカラムを絞る
基本中の基本ですが効果が大きいです。最初にふれたとおりBigQueryはカラムごとに別々のファイルにデータを保存しているので、参照するカラムが増えると読み込むファイルが増えます。逆に、必要なカラムだけを読み込みことでデータ量を抑えることができます。
以下の2つのクエリは公開されているデータセット bigquery-public-data.covid19_open_data.covid19_open_data を参照しています。こちらのテーブルは記事執筆時点では700以上のカラムがありますので、実際にBiqQueryのコンソールにクエリを添付すると参照されるデータ量が大きく変わることが確認できると思います。
(※実際にクエリを実行する際はデータ使用量にご注意ください)
- 悪い例
SELECT * FROM `bigquery-public-data.covid19_open_data.covid19_open_data`
WHERE location_key = 'JP_13'
AND date BETWEEN '2021-01-01' AND '2021-08-30'
ORDER BY date DESC;
- 良い例
SELECT
location_key
,date
,country_name
,subregion1_name
,new_confirmed
,new_deceased
,cumulative_confirmed
,cumulative_deceased
,population
FROM `bigquery-public-data.covid19_open_data.covid19_open_data`
WHERE location_key = 'JP_13'
AND date BETWEEN '2021-01-01' AND '2021-08-30'
ORDER BY date DESC;
テーブル分割(Pertitioning)で絞る
BigQueryでもテーブル分割機能がサポートされています。
分割キーとして指定できるカラムのデータ型は以下の通りです。
- 時間単位の列: TIMESTAMP、DATE、または DATETIME 列による分割
- 日別、時間別、月別、年別
- 取り込み時間: BigQuery がデータを取り込む際のタイムスタンプに基づいた分割
- 整数範囲: 整数列
下図の右のテーブルではCreation_dateカラムによる分割が行われています。左右のテーブルにそれぞれ
WHERE Creation_date = '20180302'
の絞り込み条件を含む SELECT 文を実行した場合、左のテーブルでは全件がreadされますが右のテーブルでは薄緑の範囲のレコードしかreadされません。
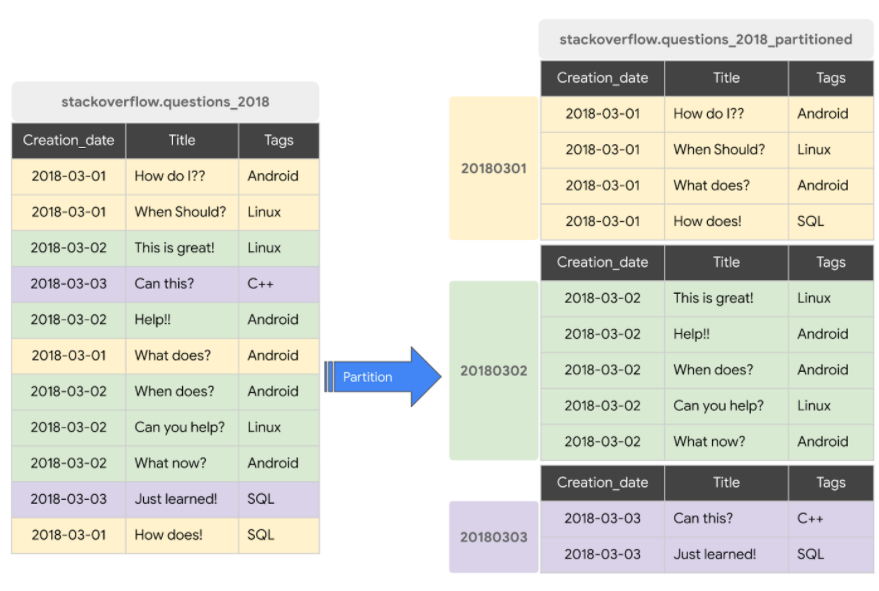
参考:BigQuery Admin reference guide: Storage internals
その他の以下のような特徴があります。
- Pertitionの有効期限を設定することで自動でデータを削除できる(オプション, 整数範囲以外)
- ユーザに対して、クエリでの分割キーの指定を強制できる(オプション)
- 分割テーブルは 4,000 個まで作成できる
- 分割によってできるテーブルのサイズがおおよそ1GBを下回ると、分割テーブルの管理コストがメリットを上回る
公開されているデータセットから分割テーブルを作成し、動きを確認するためのSQLを載せておきます。
(※実際にクエリを実行する際はデータ使用量にご注意ください)
テーブルを作成するとき、 AS SELECT を利用することで選択された結果を作成されたテーブルに INSERT できます。
もちろん、空のテーブルを作るだけの CREATE TABLE 文で分割を指定することもできます。
-- dateカラムを月ごとに分割するテーブルを作成する
CREATE TABLE
my_dataset_001.covid19_open_data_pertitioned_by_month (
location_key STRING
,date DATE
,country_name STRING
,subregion1_name STRING
,new_confirmed INTEGER
,new_deceased INTEGER
,cumulative_confirmed INTEGER
,cumulative_deceased INTEGER
,population INTEGER
)
PARTITION BY
DATE_TRUNC(date, MONTH)
AS SELECT
location_key
,date
,country_name
,subregion1_name
,new_confirmed
,new_deceased
,cumulative_confirmed
,cumulative_deceased
,population
FROM
`bigquery-public-data.covid19_open_data.covid19_open_data`
;
-- 分割テーブルから取得する
SELECT
location_key
,date
,country_name
,subregion1_name
,new_confirmed
,new_deceased
,cumulative_confirmed
,cumulative_deceased
,population
FROM `my_dataset_001.covid19_open_data_pertitioned_by_month`
WHERE location_key = 'JP_13'
AND date BETWEEN '2021-01-01' AND '2021-08-30'
ORDER BY date DESC;
クラスタリング(Clustering)で行を絞る
指定したカラムでデータをあらかじめソートしておく機能です。
BigQueryにはRDSのindexに相当する概念がありませし、前項の Partitioning では利用できるカラムのデータ型に制限がありました。
RDSでいうところの「主キーを使って高速にデータにアクセスしたい」というときにはクラスタリングを利用できそうです。
下図の右のテーブルではCreation_dateカラムによる分割に加えて、 Tags カラムによるクラスタリングが行われています。左右のテーブルにそれぞれ
WHERE Creation_date = '20180302' AND Tags = 'Android'
の絞り込み条件を含む SELECT 文を実行した場合、左のテーブルでは全件がreadされますが右のテーブルでは薄緑の範囲の最初の3レコードしかreadされません。
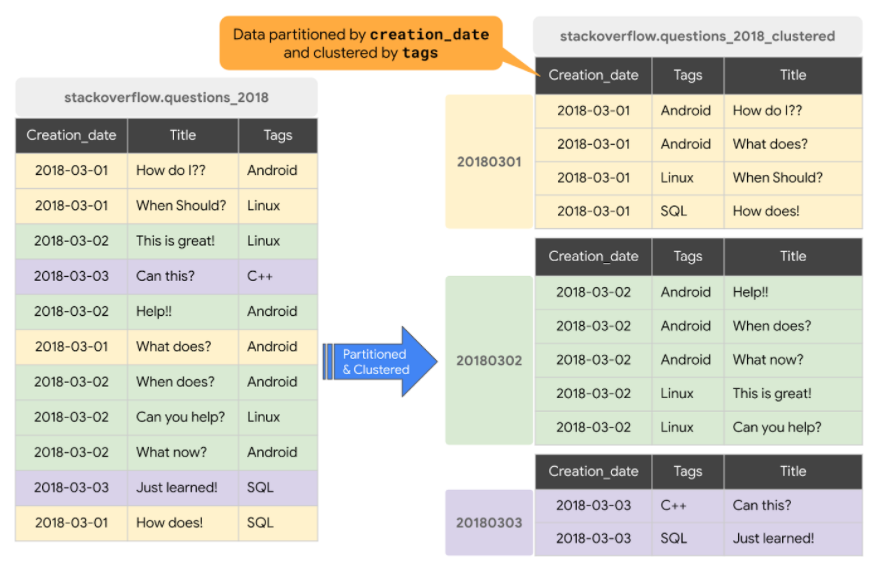
参考:BigQuery Admin reference guide: Storage internals
その他の以下のような特徴があります。
- フィルター条件にクラスター化されたカラムを指定することで捜査対象を絞ることができる
- カーディナリティが大きいカラム(群)に特に有効
- Sortは自動で行われる
- カラムの指定の順序がソートの順番を決める
- クラスタ化されたテーブルに対するクエリはプレビューが効かなくなる
- パーティションと併用可能
- 既存のテーブルのカラムに後からクラスター化を設定できるが、それまであったデータはSortされない
公開されているデータセットからクラスター化したテーブルを作成し、動きを確認するためのSQLを載せておきます。
(※実際にクエリを実行する際はデータ使用量にご注意ください)
-- クラスター化テーブルを作成する
CREATE TABLE
my_dataset_001.covid19_open_data_cluster_by_key_date (
location_key STRING
,date DATE
,country_name STRING
,subregion1_name STRING
,new_confirmed INTEGER
,new_deceased INTEGER
,cumulative_confirmed INTEGER
,cumulative_deceased INTEGER
,population INTEGER
)
CLUSTER BY
location_key
,date
AS SELECT
location_key
,date
,country_name
,subregion1_name
,new_confirmed
,new_deceased
,cumulative_confirmed
,cumulative_deceased
,population
FROM
`bigquery-public-data.covid19_open_data.covid19_open_data`
;
複数のカラムを指定してクラスター化する場合、絞り込み条件を指定するときには注意が必要です。
上記のクエリでは CLUSTER BY 句の中で location_key -> date の順番でカラムを指定しています。
この場合、2つ目のカラム( date )だけを指定するとクラスター化が効きません。
-- クラスター化が効く(読み込まれるデータ:25.5MB)
SELECT * FROM `my-project-1562073507650.my_dataset_001.covid19_open_data_cluster_by_key_date`
WHERE location_key = 'JP_13'
;
-- クラスター化が効かない(読み込まれるデータ:880.1 MB)
SELECT * FROM `my-project-1562073507650.my_dataset_001.covid19_open_data_cluster_by_key_date`
WHERE date = '2021-04-01'
;
ワイルドカードテーブルで絞る
BigQueryのドキュメントによると、テーブル分割はシャーディングよりも効果的で、シャーディングは控えるべきとあります。
しかし、テーブル分割で指定できるカラムの型には制限があり、たとえばPostgreSQLではできた文字列カラムによる分割ができません。
そのような場合には sample_table_hoge, sample_table_fuga といったシャーディングも選択肢に入りますが、この2つのテーブルのどちらか、あるいは両方を参照したいときに少し困ります。シャーディングテーブルの数が決まっていて名前が既知であればすべて列挙してUNIONする方法がありますが、この手のテーブルは動的に増えていく場合が多いと思います。
そういう場合にはワイルドカードテーブルが利用できます。
以下のクエリはsample_table_hoge, sample_table_fugaの全件を返します。
(sample_table_hoge, sample_table_fugaは同じdataset内にある必要があります)。
SELECT
*
FROM
sample_table_*
;
また、以下のクエリはsample_table_hogeの全件を返します。
SELECT
*
FROM
sample_table_*
WHERE
_TABLE_SUFFIX = 'hoge'
;
_TABLE_SUFFIX を利用して各テーブル名の * に該当する部分を利用してフィルターをかけることが可能です。
_TABLE_SUFFIX はワイルドカードテーブルを利用したクエリの中で利用可能で、あらかじめテーブルにこのようなカラムを作る必要はありません。
1点注意なのはワイルドカードテーブルでヒットする各テーブルは スキーマが共通である 必要があり、これを満たしていないとクエリがエラーになります。user_hoge, user_fugaといったシャーディングとワイルドカードテーブルクエリを利用ているときに user_detail みたいな別スキーマのテーブルを同じデータセットに追加してしまうとクエリが通らなくなります。