前提条件
背景
自分なりに噛み砕いた用語集がほしかったので記載
環境
Elasticsearch 7.8
この記事を読んだ方がいい人
・MySQLの経験がある程度あってSQLってこんな感じだよねー、な感覚がある人。
・RDBでは遅くなってしまう検索を解決してくれるイケイケな道具があることを知りつつ、それがなんなのかよくわからない人。
この記事を読まない方がいい人
・Elasticsearchの実務経験がすでにあって全文検索エンジンとマブダチな人。
・日本人ならGroongaにしろよ、って人。
論理概念
用語一覧
| 用語 | 意味 | 補足 | |
|---|---|---|---|
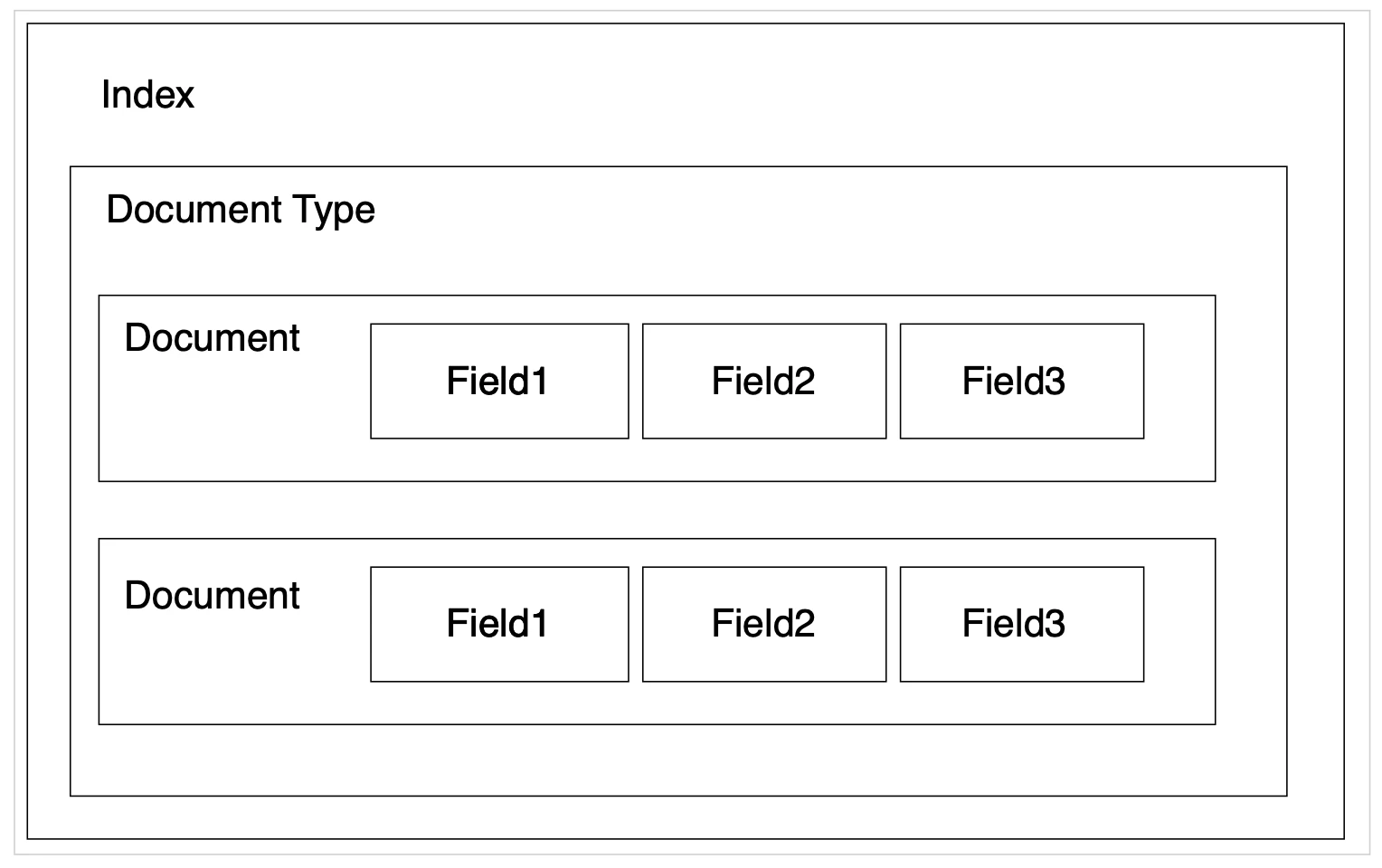
| ドキュメント | Document | RDBでいうところのレコード | json形式 |
| フィールド | Field | RDBでいうところのカラム。ドキュメント内のkey-valueを言い表す | |
| インデックス | Index | RDBでいうところのテーブル | 実際にはアナライザによる単語分割などが行われてから保存される。kuromojiとかはアナライザの一種 |
| ドキュメントタイプ | Document Type | RDBでいうところのテーブル定義 | Elasticsearch7.x系では1つのインデックスに複数のドキュメントタイプを定義できない |
| マッピング | Mapping | Document Typeとほぼ同義?Document Typeの具体的な内容のことを指している | 下記マッピング定義のリクエストを参照。 my_index:インデックス名 tweet:ドキュメントタイプ ドキュメントに名前がつけられるこれがない場合はElasticsearchが自動的にマッピングを定義してからドキュメントを格納してくれる。scoutは多分これを利用している。 |
cur
l -XPUT http://elasticsearch:9200/my_index/_mapping/tweet -H 'Content-Type:application/json' -d '
{
"properties": {
"user_name": {"type": "text"},
"message": {"type": "text"}
} }
イメージ
物理概念
用語一覧
| 用語 | 意味 | 補足 | |
|---|---|---|---|
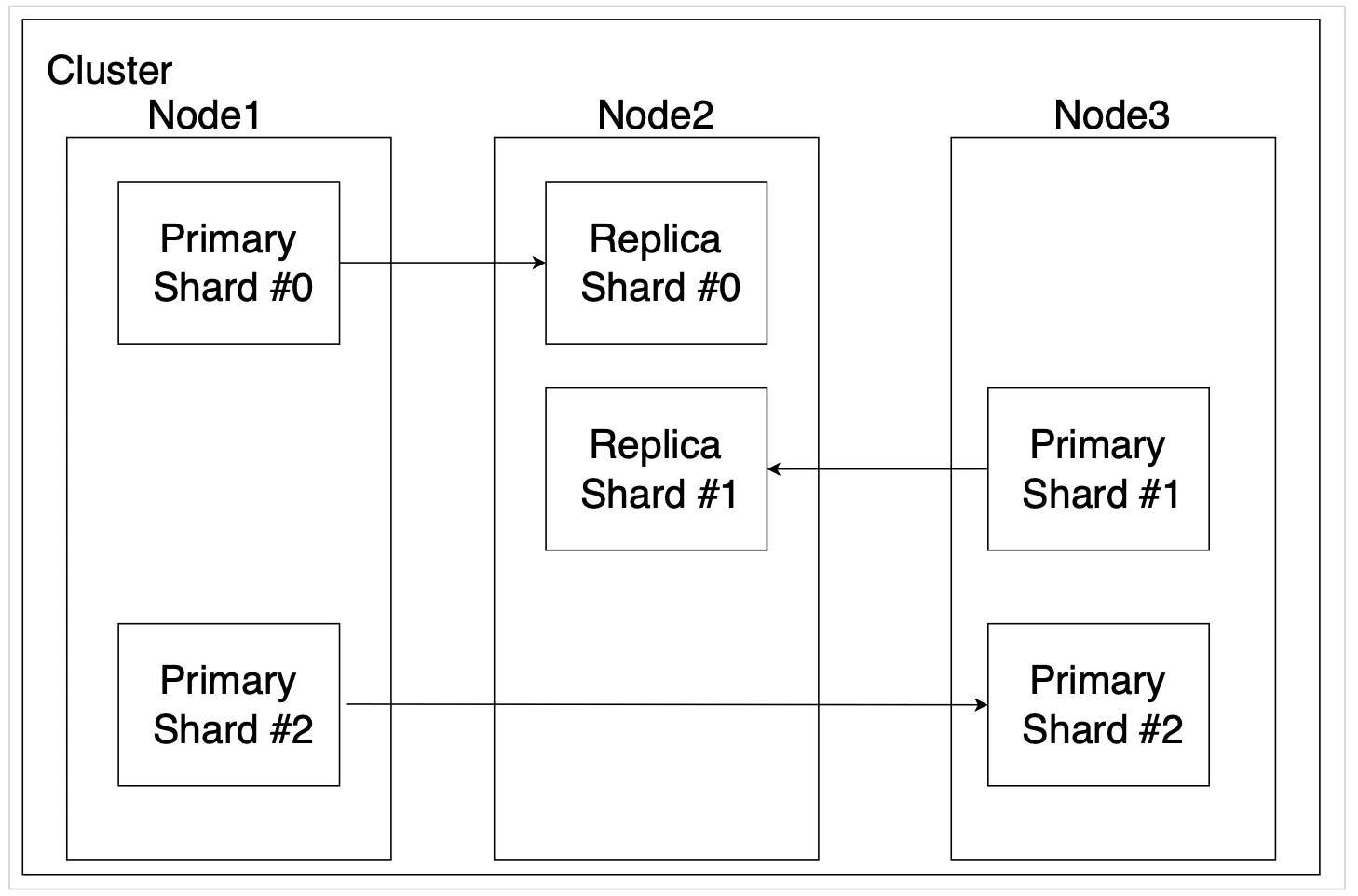
| ノード | node | Elasticsearchが動作する各サーバ | |
| クラスタ | Cluster | 複数ノードで構成するグループ | |
| シャード | Shard | インデックスデータを分割した部分のこと | 複数ノードで分割して、サーバのリソースが足りなくならないようにする。インデックス作成後にはシャードは増やせない。 |
| レプリカ | Replica | シャードやノードの冗長化 |
イメージ
補足
ElasticsearchのクエリはHTTPのボディにJson形式で指定する方式になっている。
REST APIでのインターフェースを提供しているので、なかなか直感的に操作を理解できる。
ただ、GETとPOST、どっちも参照系として使用されるみたい。全部かどうかはわかんないけど。
GETのリクエスト時にはHTTPボディを指定できないクライアントがいるんじゃない?っていう配慮らしい。
やさすてぃっく。