はじめに
BigQueryだけで自然言語系の処理をしたいケースがあって、その最小限の方法を調べました。一般的な形態素解析というののちょっと手前の、分かち書きまでです。品詞の特定とか、単語の原型を出さない。
品詞を特定するのは、辞書ファイルが必要で、BigQueryではライブラリから外部のファイルを読むことができなさそうだったので、ひとまず分かち書きまで。
TinySegmenterというライブラリを使用しました。
最初に結果
分かち書きの結果
入力:明日は天気が良さそうなので買い物に行きたい
TinySegmenterの結果:明日 / は / 天気 / が / 良さ / そう / な / の / で / 買い物 / に / 行き / たい
学校ではこの分野は超絶 嫌い 苦手だったので正解はわかりませんw
ただ以前、こちらの記事(kuromojiを使ったJavaScriptだけの形態素解析)で、kuromojiというライブラリで品詞分解を試せる環境を作ったので、そこに入れてみました。その結果がこれ。
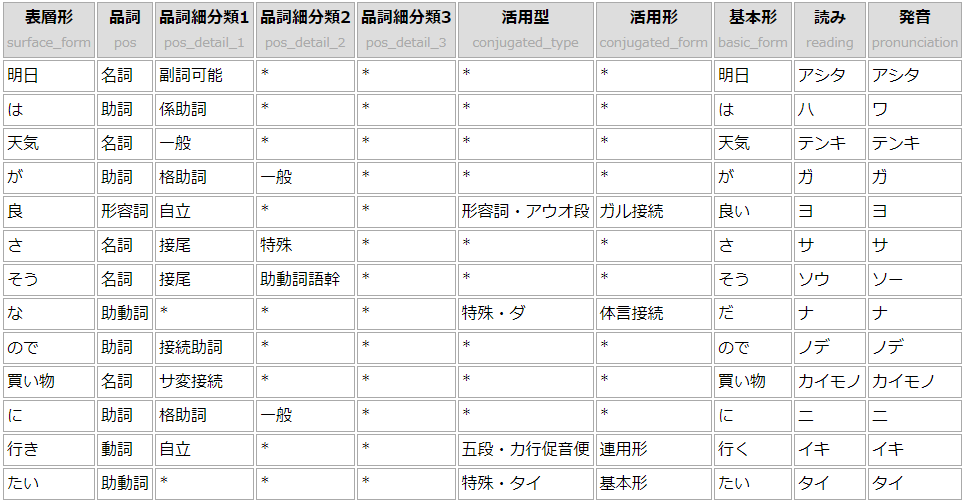
分かち書きだけで比較すると、これ↓。まぁまぁいいんじゃないですかね。やっぱ基本形はほしくなるけど。
入力:明日は天気が良さそうなので買い物に行きたい
TinySegmenter:明日 / は / 天気 / が / 良さ / そう / な / の / で / 買い物 / に / 行き / たい
kuromoji:明日 / は / 天気 / が / 良 / さ / そう / な / ので / 買い物 / に / 行き / たい
方法
概要はこうです。
- BigQueryのユーザー定義関数(UDF)をJavaScriptで定義で実施したユーザー定義関数で、分かち書きする。
- そのとき、外部のライブラリ(TinySegmenter)を使う。
1. GCSにJavaScriptファイルを置く
TinySegmenterはダウンロードしておきます。
自分のユーザー定義関数として、下記を作ります。
const tinySegmenter = new TinySegmenter();
function wakachigaki(sentence){
return tinySegmenter.segment(sentence);
}
グローバルな領域でTinySegmenterをインスタンス化しておいて、wakachigaki()関数が呼ばれたらそれを使う、というだけ。
この2つのファイルを、GCSへ格納します。
2. BigQueryで使う
BigQueryのいつものクエリの画面に入力します。
create temporary function keitaiso1(x string)
returns array<string>
language js as """
return wakachigaki(x);
"""
options(
library=["gs://for_bq/tiny_segmenter-0.2.js", "gs://for_bq/mol_ana.js"]
);
select keitaiso1(val)
from UNNEST(['明日は天気が良さそうなので買い物に行きたい']) as val;
以前の記事(BigQueryのユーザー定義関数(UDF)をJavaScriptで定義)では、ちらっとしか書きませんでしたが、options()で、分かち書きライブラリと、自分のコードの2つを呼び出してます。
これだけで、いつもの画面に出ます。
おわりに
コードも多くないし、作業量も少なくてさらっとできます。
TinySegmenterは、機械学習で品詞分解をやっているそうで、その再学習をすることもできるようです。