はじめに
現状ではジョブ管理システム(JP1 等)+EC2で実装しているバッチ処理を、サーバレスにしてリソースコストや運用コストを抑えたいと思い、勉強のためECSやStep Functionsを触ってみました。
ECSのドキュメントや各種記事等を読んで調べた結果、メインのバッチ処理はJavaアプリをECS(Fargate)上でコンテナ実行することとし、Step Functionsで定期実行や並列実行を制御する構成を試すことにしました。主な理由は以下となります。
- 既存バッチ処理のJava資材をなるべく流用したい → Javaアプリ
- 入力1ファイルあたりのデータ量がそれなりに大きい想定のため、Lambdaでは15分タイムアウトに引っかかる可能性がある → ECS
- 長くて数時間の日次ジョブの想定であり、実行中以外のリソース利用料金発生を避けたい(EC2のメンテナンスも面倒) → Fargate
- ECS単体だとリトライや並列化の制御は難しそう → Step Functions
ぶっちゃけ今回試した程度の処理内容なら、Sparkで書いてEMRで実行した方がよっぽど簡単な気もするのですが、勉強のため敢えてのECSです。ただ、要件に応じて並列分散のロジックを個別に作り込む必要がある場合などは、こういう構成もありうるかなと思います。
バッチ処理アプリの実装
コンテナ実行するJavaアプリは、サンプルとして以下のような単純な処理内容としました。
- S3上のテキストファイルを読み出す
- ファイル内の各レコードを加工する(今回は各レコードに固定値を付与するだけ)
- 加工後データをS3上に書き出す
入力ファイルが複数あり、ファイル単位に並列で処理できるようにすることを想定して、1回の実行内では引数指定された1ファイルのみを処理するようにしています。
build.gradle
intellijでgradleプロジェクト作成時に自動生成されたものに対して、以下の追加とメインクラス指定のみ追記しています。
- Gradle Shadow Plugin
- Dockerイメージ作成時に単一JARで配置・実行できるように Fat JAR作成するため。
- AWS SDK for Java
- S3入出力のため。
plugins {
id 'java'
id 'com.github.johnrengelman.shadow' version '7.1.0'
}
group 'com.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
jar {
manifest {
attributes 'Main-Class': "com.example.ecssample.Main"
}
}
dependencies {
implementation 'com.amazonaws:aws-java-sdk-s3:1.12.122'
}
test {
useJUnitPlatform()
}
settings.gradle
rootProject.name = 'ecs-sample'
最初にこれを忘れたせいでJARファイル名がgradle-1.0-SNAPSHOT-all.jarになってしまっていることに気づかず、Dockerイメージ作成時にファイルが見つからなくて少しハマりました。。。
Main.java
package com.example.ecssample;
import com.amazonaws.services.s3.AmazonS3;
import com.amazonaws.services.s3.AmazonS3ClientBuilder;
import com.amazonaws.services.s3.model.*;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
public class Main {
public static void main(String[] args) {
System.out.println("start");
String bucket = args[0];
String inputKey = args[1];
String outputKey = args[2];
System.out.println(bucket + "," + inputKey + "," + outputKey);
AmazonS3 s3Client = AmazonS3ClientBuilder.defaultClient();
S3Object s3Object = s3Client.getObject(bucket, inputKey);
InputStream is = s3Object.getObjectContent();
try (BufferedReader br = new BufferedReader(new InputStreamReader(is, StandardCharsets.UTF_8))) {
MultipartUploader uploader = new MultipartUploader(s3Client);
uploader.init(bucket, outputKey);
String line;
while ((line = br.readLine()) != null) {
// 加工内容はレコード先頭に固定値カラム追加するだけ
String out = "out," + line + "\n";
uploader.put(out);
}
uploader.complete();
System.out.println("end");
} catch (IOException e) {
e.printStackTrace();
}
}
}
出力ファイルサイズもそこそこ大きい想定なので、マルチパートアップロードができるようにしています。以下の記事を大いに参考にさせていただきました。(というかほぼパクらせていただきました。)
package com.example.ecssample;
import com.amazonaws.services.s3.AmazonS3;
import com.amazonaws.services.s3.model.*;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.List;
public class MultipartUploader {
private final AmazonS3 s3Client;
private String bucket;
private String key;
private ByteBuffer buffer;
private int partNumber;
private List<PartETag> eTags;
private InitiateMultipartUploadResult initResult;
public MultipartUploader(AmazonS3 s3Client) {
this.s3Client = s3Client;
}
public void init(String bucket, String key) {
this.bucket = bucket;
this.key = key;
this.eTags = new ArrayList<>();
InitiateMultipartUploadRequest initRequest = new InitiateMultipartUploadRequest(bucket, key);
this.initResult = s3Client.initiateMultipartUpload(initRequest);
this.buffer = ByteBuffer.allocate(10 * 1024 * 1024);
this.partNumber = 0;
}
public void put(String output) throws IOException {
byte[] bytes = output.getBytes(StandardCharsets.UTF_8);
buffer.put(bytes);
if (buffer.position() > 5 * 1024 * 1024) {
flush();
}
}
private void flush() throws IOException {
System.out.println("Flushing...");
Path path = Files.createTempFile("temp-", ".csv");
FileChannel ch = new FileOutputStream(path.toString()).getChannel();
try (ch) {
buffer.flip();
int writtenBytes = ch.write(buffer);
partNumber++;
UploadPartRequest request =
new UploadPartRequest()
.withBucketName(bucket)
.withKey(key)
.withFile(path.toFile())
.withFileOffset(0)
.withUploadId(initResult.getUploadId())
.withPartNumber(partNumber)
.withPartSize(writtenBytes)
.withGeneralProgressListener(
event -> {
System.out.println(
"progress: " + event.getBytesTransferred() + "/" + event.getBytes());
});
UploadPartResult result = s3Client.uploadPart(request);
System.out.println(result.getPartETag());
eTags.add(result.getPartETag());
buffer.clear();
} finally {
Files.deleteIfExists(path);
}
}
public void complete() throws IOException {
if (buffer.position() > 0) {
Path path = Files.createTempFile("temp-", ".csv");
FileChannel ch = new FileOutputStream(path.toString()).getChannel();
try (ch) {
buffer.flip();
int writtenBytes = ch.write(buffer);
partNumber++;
UploadPartRequest request =
new UploadPartRequest()
.withBucketName(bucket)
.withKey(key)
.withFile(path.toFile())
.withFileOffset(0)
.withUploadId(initResult.getUploadId())
.withPartNumber(partNumber)
.withPartSize(writtenBytes);
UploadPartResult result = s3Client.uploadPart(request);
eTags.add(result.getPartETag());
buffer.clear();
} finally {
Files.deleteIfExists(path);
}
}
CompleteMultipartUploadRequest completeRequest =
new CompleteMultipartUploadRequest(bucket, key, initResult.getUploadId(), eTags);
s3Client.completeMultipartUpload(completeRequest);
System.out.println("done");
}
}
実行コマンド例
$ ./gradlew clean shadowJar
$ java -cp build/libs/ecs-sample-1.0-SNAPSHOT-all.jar \
com.example.ecssample.Main \
<バケット名> \
path/to/input/hoge.csv \
path/to/output/hoge.csv
ECSでバッチ処理アプリを実行
Dockerイメージ作成
上記のJavaアプリをコンテナ実行可能とするため、Dockerfileを用意してDockerイメージを作成します。
FROM gradle:jdk11-alpine as builder
WORKDIR /home/gradle
COPY --chown=gradle:gradle build.gradle .
COPY --chown=gradle:gradle settings.gradle .
COPY --chown=gradle:gradle src src
RUN gradle shadowJar
FROM adoptopenjdk/openjdk11:alpine as runner
RUN addgroup -S app && adduser -S app -G app
USER app:app
WORKDIR /home/app
COPY --from=builder --chown=app:app /home/gradle/build/libs/ecs-sample-1.0-SNAPSHOT-all.jar /home/app/app.jar
ENTRYPOINT ["java","-jar","app.jar"]
まずはローカルで実行してみます。dockerコマンドでも十分ですが、一応docker-composeでも実行できるようにdocker-compose.ymlも用意しています。
version: '3'
services:
app:
build: .
volumes:
- ~/.aws/:/home/app/.aws/
command: ["<バケット名>", "path/to/input/hoge.csv", "path/to/output/hoge.csv"]
実行コマンド
$ docker-compose up
ECR登録
AWS CLIでECRにリポジトリ作成し、上記のDockerイメージを登録します。
# ECRリポジトリ作成
$ aws ecr create-repository --repository-name javatest --region ap-northeast-1
# ローカルでDockerイメージ作成
$ docker build -t javatest .
# Dockerイメージにタグ付け
$ docker tag javatest <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/javatest
# リポジトリ認証
$ aws ecr get-login-password | docker login --username AWS --password-stdin <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com
# DockerイメージをECR登録
$ docker push <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/javatest
ECSタスク定義
上記のDockerイメージを使用して実行するタスク定義を用意します。
マネジメントコンソール上で以下のとおり設定しました。
なお、本節以降も含め、マネジメントコンソールでの設定の記述で特に記載のない部分はデフォルトのままです。
- 起動タイプ:「FARGATE」
- タスク定義名:
javatest(任意の値) - タスクロール:事前作成したS3アクセス可能なロール(とりあえず
AmazonS3FullAccessポリシーを付与)のARNを設定 - オペレーティングシステムファミリー:「Linux」
- タスク実行ロール:「新しいロールの作成」
-
ecsTaskExecutionRoleが既に作成済であればそれを使用
-
- タスクメモリ:「0.5GB」(最小)
- タスクCPU:「0.25vCPU」(最小)
- コンテナ追加
- コンテナ名:
javatest-container(任意の値) - イメージ:
<アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/javatest(上記でECR登録したリポジトリ)
- コンテナ名:
タスクロールとタスク実行ロールの違いについては以下の記事を参照しました。
ECSクラスター作成
こちらもマネジメントコンソールで作成しています。
- クラスターテンプレートの選択:「ネットワーキングのみ」
- クラスター名:
test(任意の値)
Fargateだとタスク実行中以外は料金が発生しないので、料金発生を避けるためにマメにクラスター削除したりしなくてもよいのが嬉しいところです。
ECSタスク実行
作成したECSクラスター上でタスクを実行します。
マネジメントコンソールから実行する場合
- 上記で作成した
testクラスターを選択 - 「タスク」タブで「新しいタスクの実行」
- 起動タイプ:「FARGATE」
- オペレーティングシステムファミリー:「Linux」
- タスク定義
- ファミリー:
javatest(上記で作成したタスク定義) - リビジョン:latestのものを選択
- ファミリー:
- プラットフォームのバージョン:「LATEST」(執筆時点では1.4.0)
- クラスター:
test(上記で作成したクラスター) - タスクの数:
1 - クラスターVPC:とりあえずデフォルトVPCを指定
- サブネット:とりあえずデフォルトVPCのPublicサブネットを指定
- セキュリティグループ:とりあえずデフォルトVPCのdefault(フルオープン)を指定
- パブリック IP の自動割り当て:「ENABLED」
- DISABLEDだとECRアクセスができず以下のエラーが発生してしまいました。
ResourceInitializationError: unable to pull secrets or registry auth: pull command failed: : signal: killed
- DISABLEDだとECRアクセスができず以下のエラーが発生してしまいました。
- コンテナの上書き
-
javatest-container(上記のタスク定義作成時に設定したコンテナ名)- コマンドの上書き
- 設定例:
<バケット名>,path/to/input/hoge.csv,path/to/output/hoge.csv- Javaアプリに渡す引数を記述します。
DockerfileのCMDや前述のdocker-compose.ymlのcommandで設定する値に相当します。 - カンマ区切り、ダブルクォート囲み無しです。カンマの前後に半角スペース等を入れると、それも値に含まれてしまうので要注意です。
- Javaアプリに渡す引数を記述します。
- 設定例:
- コマンドの上書き
-
AWS CLIから実行する場合
$ aws ecs run-task \
--cluster test \
--task-definition javatest \
--overrides '{"containerOverrides": [{"name":"javatest-container","command": ["<バケット名>", "path/to/input/hoge.csv", "path/to/output/hoge.csv"]}]}' \
--launch-type FARGATE \
--network-configuration "awsvpcConfiguration={subnets=[<サブネットID>],securityGroups=[<セキュリティグループID>],assignPublicIp=ENABLED}"
{
"tasks": [
{
"attachments": [
{
"id": "571d11ab-c6b7-460a-b342-4bf44a4e2989",
"type": "ElasticNetworkInterface",
"status": "PRECREATED",
"details": [
{
"name": "subnetId",
"value": "<サブネットID>"
}
]
}
],
"attributes": [
{
"name": "ecs.cpu-architecture",
"value": "x86_64"
}
],
"availabilityZone": "ap-northeast-1a",
"clusterArn": "arn:aws:ecs:ap-northeast-1:<アカウントID>:cluster/test",
"containers": [
{
"containerArn": "arn:aws:ecs:ap-northeast-1:< アカウントID>:container/test/109676de48254eab81ff86ed86c30369/acc808d8-299a-4397-bd58-b02629116227",
"taskArn": "arn:aws:ecs:ap-northeast-1:<アカウントID>:task/test/109676de48254eab81ff86ed86c30369",
"name": "javatest-container",
"image": "<アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/javatest",
"lastStatus": "PENDING",
"networkInterfaces": [],
"cpu": "0"
}
],
"cpu": "256",
"createdAt": "YYYY-MM-DDTHH:MM:SS.sss000+09:00",
"desiredStatus": "RUNNING",
"group": "family:javatest",
"lastStatus": "PROVISIONING",
"launchType": "FARGATE",
"memory": "512",
"overrides": {
"containerOverrides": [
{
"name": "javatest-container",
"command": [
"<バケット名>",
"path/to/input/hoge.csv",
"path/to/output/hoge.csv"
]
}
],
"inferenceAcceleratorOverrides": []
},
"platformVersion": "1.4.0",
"tags": [],
"taskArn": "arn:aws:ecs:ap-northeast-1:<アカウントID>:task/test/109676de48254eab81ff86ed86c30369",
"taskDefinitionArn": "arn:aws:ecs:ap-northeast-1:<アカウントID>:task-definition/javatest:2",
"version": 1
}
],
"failures": []
}
このコマンドはあくまでタスクの起動指示のみで、タスクは非同期で実行されるようです。
そのため、ジョブ管理システム等からコマンドで直接ECSタスク実行しつつ完了後に後続ジョブを続けたいようなケースでは、完了まで結果確認をポーリングし続けるような処理を加える必要がありそうです。
run-taskのコマンドリファレンスをざっと見た限りは、同期実行できるようなオプションや類似コマンドは見つかられませんでしたが、waitというコマンドならありました。
以下のように書けば、完了まで待って結果出力することも一応できました。(出力は長いので割愛します。)
$ task_arn=$(aws ecs run-task \
--cluster test \
--task-definition javatest \
--overrides '{"containerOverrides": [{"name":"javatest-container","command": ["<バケット名>", "path/to/input/hoge.csv", "path/to/output/hoge.csv"]}]}' \
--launch-type FARGATE \
--network-configuration "awsvpcConfiguration={subnets=[<サブネットID>],securityGroups=[<セキュリティグループID>],assignPublicIp=ENABLED}" \
--query "tasks[0].taskArn" \
--output text) ; \
aws ecs wait tasks-stopped --cluster test --tasks ${task_arn} ; \
aws ecs describe-tasks --cluster test --tasks ${task_arn}
Step FunctionsからECSタスク実行
次に、上記のECSタスクを、複数の入力ファイルに対して、ファイル単位で並列実行したいと思います。
ECS単体でも、タスク数を増やして並列実行することはできそうですが、APIサーバ等のように全く同じ動作をするプロセスを複数並べてLB等で分散するような例が多い印象です。
バッチ処理で入力ファイルごとにパラメータを変えながら複数のタスクを並列実行する方法は見つけられなかったのですが、Step Functionsを併用すればできそうだったので試してみました。
ECSタスクを実行するワークフローの作成
まずはECSタスクを単発で実行するワークフローを作成します。
下記ドキュメントや、サンプルプロジェクトの「コンテナタスクの管理」を参考にしました。
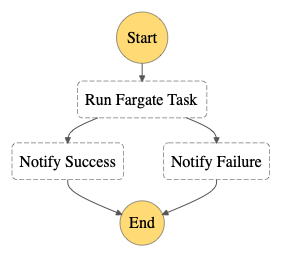
{
"StartAt": "Run Fargate Task",
"States": {
"Run Fargate Task": {
"Type": "Task",
"Resource": "arn:aws:states:::ecs:runTask.sync",
"TimeoutSeconds": 300,
"Parameters": {
"LaunchType": "FARGATE",
"Cluster": "arn:aws:ecs:ap-northeast-1:<アカウントID>:cluster/test",
"TaskDefinition": "arn:aws:ecs:ap-northeast-1:<アカウントID>:task-definition/javatest:<リビジョン>",
"NetworkConfiguration": {
"AwsvpcConfiguration": {
"Subnets": [
"<サブネットID>"
],
"SecurityGroups": [
"<セキュリティID>"
],
"AssignPublicIp": "ENABLED"
}
},
"Overrides": {
"ContainerOverrides": [
{
"Name": "javatest-container",
"Command.$": "$.commands"
}
],
"TaskRoleArn": "arn:aws:iam::<アカウントID>:role/<S3アクセス可能なタスクロール名>"
}
},
"Next": "Notify Success",
"Retry": [ {
"ErrorEquals": [ "States.ALL" ],
"IntervalSeconds": 1,
"MaxAttempts": 2,
"BackoffRate": 2.0
} ],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Notify Failure"
}
]
},
"Notify Success": {
"Type": "Pass",
"Result": "Success",
"End": true
},
"Notify Failure": {
"Type": "Pass",
"Result": "Failure",
"End": true
}
}
}
タスク単位のリトライ処理であれば、Retryの設定で簡単に追加できて便利です。
このワークフローをマネジメントコンソールから「実行の開始」で実行します。入力例は以下となります。
{
"commands": [
"<バケット名>",
"path/to/input/hoge.csv",
"path/to/output/hoge.csv"
]
}
しかし、初めは以下のエラーが発生してしまいました。
{
"resourceType": "ecs",
"resource": "runTask.sync",
"error": "ECS.AccessDeniedException",
"cause": "User: arn:aws:sts::<アカウントID>:assumed-role/StepFunctions-ecs-javatest-role-c58e1f52/CNWMMRcOPPfWhRYSMDXDXuiYLWyPhJlh is not authorized to perform: iam:PassRole on resource: arn:aws:iam::<アカウントID>:role/ecsTaskExecutionRole because no identity-based policy allows the iam:PassRole action (Service: AmazonECS; Status Code: 400; Error Code: AccessDeniedException; Request ID: 605b8845-0e2b-452a-acec-4efa2ec24b37; Proxy: null)"
}
Step Functionsのロールに以下のポリシーを追加する必要があるようです。
{
"Effect": "Allow",
"Action": [
"iam:GetRole",
"iam:PassRole"
],
"Resource": [
"arn:aws:iam::<アカウントID>:role/<タスクロール名>",
"arn:aws:iam::<アカウントID>:role/<タスク実行ロール名>"
]
}
これで実行成功するようになりました。
ECSタスクを並列実行
ワークフロー内で別のワークフローを実行
上記のECSタスク実行のステートを複数並列で実行したいわけですが、単純に複数並べると、コードがかなり長く複雑になってしまいそうです。
Step Functionsのサンプルプロジェクトを見たところ、ワークフロー内で別のワークフローを呼び出すサンプルがありました。
これに倣って、並列実行を制御する親ワークフローを用意し、その中から上記のECSタスク実行のワークフローを呼ぶようにしてみます。
以下の記事も参考にさせていただきました。
まずは並列でなく単発で、親ワークフローからの呼び出しを試します。
{
"StartAt": "Run Container Task",
"States": {
"Run Container Task": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.sync",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:<ECSタスク実行ワークフロー名>",
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"commands": [
"<バケット名>",
"path/to/input/hoge.csv",
"path/to/output/hoge.csv"
]
}
},
"End": true
}
}
}
親ワークフローのロールには、子ワークフローの実行権限として下記ポリシーを追加しています。
{
"Effect": "Allow",
"Action": [
"states:StartExecution"
],
"Resource": [
"arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:<ECSタスク実行ワークフロー名>"
]
}
Parallel
次に、Parallelというタイプを使用し、ECSタスク実行ワークフローの呼び出しを並列化します。
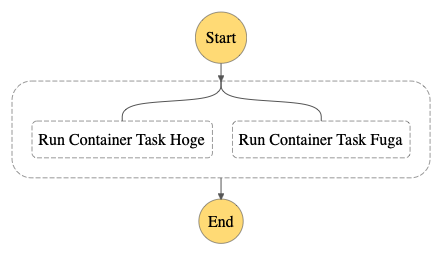
{
"StartAt": "Start in parallel",
"States": {
"Start in parallel": {
"Type": "Parallel",
"End": true,
"Branches": [
{
"StartAt": "Run Container Task Hoge",
"States": {
"Run Container Task Hoge": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.sync",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:ecs-javatest",
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"commands": [
"<バケット名>",
"path/to/input/hoge.csv",
"path/to/output/hoge.csv"
]
}
},
"End": true
}
}
},
{
"StartAt": "Run Container Task Fuga",
"States": {
"Run Container Task Fuga": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.sync",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:ecs-javatest",
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"commands": [
"<バケット名>",
"path/to/input/fuga.csv",
"path/to/output/fuga.csv"
]
}
},
"End": true
}
}
}
]
}
}
}
Branchesの中に前述と同じECSタスク実行ワークフローの呼び出し部分を2つ並べただけですが、commandsで渡す入力値でそれぞれ別ファイルを指定しています。
上記のcommandsはいったんハードコーディングですが、ワークフローの入力値として渡すこともできるので、Lambdaなどで入力値を生成する処理を手前に挟めば動的な値にすることも可能です。
ただしその場合、Branches内の各ステートには全て同じ入力値(Parallelのステートに渡された入力値)が渡されるため、例えば、入力値内に各ファイルの分担に関する情報を全て入れておき、各ステートがそこから自身が担当するファイルを抽出するような仕組みが必要となります。
Map
上記のParallelタイプを使用した方法は、入力ファイル数や並列度が固定のケースなら問題ないのですが、それでも並列度が多いとコードが冗長になったり、後から並列度だけ変更したいときもコード修正が必要になるので、今回想定しているユースケースには適していないと思われます。
他の並列処理の方法として、Mapタイプというものを見つけました。こちらは入力として配列を渡すと、配列の各要素を入力とするステートを並列実行してくれるようなので、今回のユースケースにより適していそうです。
初めに、LambdaでS3上のファイルリストを取得して、ECSタスクに渡すcommandsの配列を生成し、それをMapの入力として渡します。Lambdaのコードは以下となります。
const aws = require('aws-sdk');
aws.config.update({
region: 'ap-northeast-1',
});
const s3 = new aws.S3();
exports.handler = async (event) => {
console.log(event);
const { bucket, inputPrefix, outputPrefix } = event;
// S3ファイルリスト取得
const params = {
Bucket: bucket,
Prefix: inputPrefix,
};
const res = await s3.listObjectsV2(params).promise();
// 処理対象ファイル抽出
const regexp = new RegExp(inputPrefix + '[^/]*\.csv$', 'g');
const filenames = res.Contents
.map(object => object.Key) // S3オブジェクトのキー(ファイルパス)を取得
.filter(path => path.match(regexp)) // 指定プレフィクス直下のcsvファイルのみを抽出
.map(path => path.split('/').pop()); // プレフィクスを除いたファイル名のみを抽出
// ファイルごとのcommandsの配列を作成
const commandsList = filenames.map(filename => {
return [
bucket,
`${inputPrefix}${filename}`,
`${outputPrefix}${filename}`
];
});
const response = {
statusCode: 200,
commandsList: commandsList,
};
return response;
};
Lambdaの入力例は以下となります。これをそのまま後述のワークフローの入力として指定することになります。
{
"bucket": "<バケット名>",
"inputPrefix": "path/to/input/",
"outputPrefix": "path/to/output/"
}
次に、Lambda出力の配列の要素であるcommandsを入力として、要素の数だけ(つまり入力ファイルの数だけ)ECSタスクのワークフローを並列実行します。
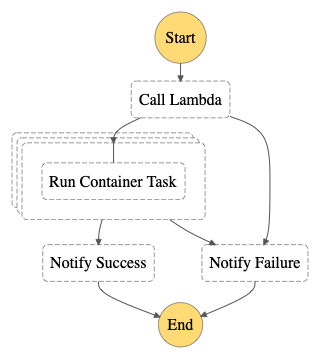
{
"StartAt": "Call Lambda",
"States": {
"Call Lambda":{
"Type":"Task",
"Resource":"arn:aws:lambda:ap-northeast-1:<アカウントID>:function:<関数名>",
"Next": "Run Continer Task Map",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Notify Failure"
}
]
},
"Run Continer Task Map": {
"Type": "Map",
"ItemsPath": "$.commandsList",
"MaxConcurrency": 2,
"Iterator": {
"StartAt": "Run Container Task",
"States": {
"Run Container Task": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.sync",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:<ECSタスク実行ワークフロー名>",
"Input": {
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"commands.$": "$"
}
},
"End": true
}
}
},
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Notify Failure"
}
],
"Next": "Notify Success"
},
"Notify Success": {
"Type": "Pass",
"Result": "Success",
"End": true
},
"Notify Failure": {
"Type": "Pass",
"Result": "Failure",
"End": true
}
}
}
ECSタスク実行ワークフロー呼び出し部分の記述が1つだけになり、Parallelの時よりスッキリしました。
MaxConcurrencyで同時実行数を指定できるので、例えば入力ファイル数が2つの場合、以下の動きになります。
-
"MaxConcurrency": 2の場合:2タスク(2ファイル)を同時に並列実行 -
"MaxConcurrency": 1の場合:2タスク(2ファイル)を1タスクずつシリアルに2つ実行
親ワークフローのロールには、Lambda関数実行権限として下記ポリシーを追加しています。
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": [
"arn:aws:lambda:ap-northeast-1:<アカウントID>:function:stepfunctions-test"
]
}
ワークフローからのLambdaの呼び出しについては以下のドキュメント・記事を参考にさせていただきました。
また、ステート間の入出力データの持ち回りについては、以下の記事を参考にさせていただきました。
ワークフローを定期実行
最後に、上記ワークフローを定期実行できるようにします。
EventBridgeから実行
Step Functionsのワークフローを定期実行する方法を調べてみると、CloudWatch Eventsの例とEventBridgeの例がよく出たので違いが気になりましたが、EventBridgeがCloudWatch Eventsの後継のようなので、最新と思われるEventBridgeで試しました。
マネジメントコンソールから以下を設定しました。特に問題なく実行されました。
- 名前:
sf-ecs-test(任意の値) - パターン
- 「スケジュール」
- 「Cron式」
-
00 6 * * ? *(日次 15:00(JST)実行の場合)
- 「スケジュール」
- ターゲット
- ターゲット:「Step Functions ステートマシン」
- ステートマシン:上記で作成した親ワークフローを選択
- 入力の設定:「定数(JSONテキスト)」
{ "bucket": "<バケット名>", "inputPrefix": "path/to/input/", "outputPrefix": "path/to/output/" }
- 「この特定のリソースに対して新しいロールを作成する」
以下の記事も参考にさせていただきました。
コマンド実行
ちなみに、現状の方式からの移行都合で、既存のジョブ管理システムからStep Functionsワークフローを起動したいケースも考えられるかと思い、コマンド実行方法についても確認しました。
こちらは以下の記事を参考にさせていただきました。
# ワークフロー一覧取得
$ aws stepfunctions list-state-machines
{
"stateMachines": [
{
"stateMachineArn": "arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:<親ワークフロー名>",
"name": "<親ワークフロー名>",
"type": "STANDARD",
"creationDate": "YYYY-MM-DDThh:mm:ss.sss000+09:00"
},
{
"stateMachineArn": "arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:<ECSタスク実行ワークフロー名>",
"name": "<ECSタスク実行ワークフロー名>",
"type": "STANDARD",
"creationDate": "YYYY-MM-DDThh:mm:ss.sss000+09:00"
}
]
}
# ワークフロー実行
$ aws stepfunctions start-execution \
--state-machine-arn arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:<親ワークフロー名> \
--input '{ "bucket": "<バケット名>", "inputPrefix": "path/to/input/", "outputPrefix": "path/to/output/" }'
{
"executionArn": "arn:aws:states:ap-northeast-1:<アカウントID>:execution:<親ワークフロー名>:a95bcc09-9669-42cc-a2b8-a01aa39f96dc",
"startDate": "YYYY-MM-DDThh:mm:ss.sss000+09:00"
}
# 結果確認
$ aws stepfunctions describe-execution \
--execution-arn arn:aws:states:ap-northeast-1:<アカウントID>:execution:<親ワークフロー名>:a95bcc09-9669-42cc-a2b8-a01aa39f96dc
{
"executionArn": "arn:aws:states:ap-northeast-1:<アカウントID>:execution:<親ワークフロー名>:a95bcc09-9669-42cc-a2b8-a01aa39f96dc",
"stateMachineArn": "arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:<親ワークフロー名>",
"name": "a95bcc09-9669-42cc-a2b8-a01aa39f96dc",
"status": "SUCCEEDED",
"startDate": "YYYY-MM-DDThh:mm:ss.sss000+09:00",
"stopDate": "YYYY-MM-DDThh:mm:ss.sss000+09:00",
"input": "{ \"bucket\": \"<バケット名>\", \"inputPrefix\": \"path/to/input/\", \"outputPrefix\": \"path/to/output/\" }",
"inputDetails": {
"included": true
},
"output": "\"Success\"",
"outputDetails": {
"included": true
}
}
start-executionで起動すると、やはりこちらも非同期実行になるようですが、ジョブ管理システムから起動する場合は同期実行の方が都合がよいです。
start-sync-executionという同期実行できそうなコマンドがあったので試してみました。
# 同期実行
$ aws stepfunctions start-sync-execution \
--state-machine-arn arn:aws:states:ap-northeast-1:<アカウントID>:stateMachine:<親ワークフロー名> \
--input '{ "bucket": "<バケット名>", "inputPrefix": "path/to/input/", "outputPrefix": "path/to/output/" }'
An error occurred (StateMachineTypeNotSupported) when calling the StartSyncExecution operation: This operation is not supported by this type of state machine
ダメでした。
上記ドキュメントをよく読んだら、Expressワークフロー用だと頭に書いてありましたね。このワークフローは標準ワークフローとして作成したものなので使用できません。
そして、Expressワークフローはオンライン処理やストリーム処理での使用を想定されているようで、最大期間が5分となっており、長時間のバッチ処理には適していないようです。
Step Functionsのワークフローはジョブ管理システムからでなく、素直にEventBridge等のAWSサービスから起動・管理した方がよさそうですね。
まとめ
EventBridge、Step Functions、ECS(Fargate)を使用して、並列分散処理を含む日次バッチジョブ相当の処理を組むことができました。
サーバレス構成とすることによりオンプレやEC2ベースの構成と比べリソースコスト削減が期待できますし、Cloud Formation/CDK等でIaC化したりCI/CDを組み合わせれば開発・運用の負担も下げられそうです。
ジョブ管理システムでのバッチジョブ管理から移行するとなると、監視や障害対応等の考え方・運用も合わせて見直す必要もありますが、その手間を上回るコストメリットがあると思われるので検討していきたいところです。