はじめに
最近はAmazon Kinesis Data Analytics for Apache Flink(以降、KDAと記述)を使用したストリームETL処理の開発をしているのですが、チューニングパラメータであるParallelismまわりの理解が不十分なまま来てしまったので、改めてドキュメント読み込みと動作確認を行いました。
なお、本記事の対象読者としては、KDAアプリケーションの基本的な実装方法(以下あたりの内容)を理解している前提とさせていただいています。
https://docs.aws.amazon.com/kinesisanalytics/latest/java/getting-started.html
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/overview/
サンプル処理の概要
動作確認を行うためのサンプル処理として、Kinesis Data Streams(以降、KDSと記述)を入出力とし、KDAでイベントのストリーム加工処理を行うような処理を想定しています。

ストリーム加工内容としては以下のような単純な処理とします。
- map
- イベント単位の軽微な加工(今回は処理時点のシステム時刻を付与するのみ)
- いわゆる軽い処理
- filter
- 全イベントのうち約1/10のイベントを破棄
- async
- Async I/Oを使用した外部ストレージ参照によるエンリッチを想定(実際のI/Oの代わりに1秒sleepで擬似)
- いわゆる重い処理
KDAができる処理の種類としては集計系など他にもいろいろありますが、ETL用途の場合はだいたい上記で済むことが多そうです。
KDAのParallelismとKPU
KDAアプリケーションで設定可能な主要なチューニングパラメータとして、ParallelismとParallelismPerKPUがあります。
- Parallelism — Use this property to set the default Apache Flink application parallelism. All operators, sources, and sinks execute with this parallelism unless they are overridden in the application code. The default is 1, and the default maximum is 256.
- ParallelismPerKPU — Use this property to set the number of parallel tasks that can be scheduled per Kinesis Processing Unit (KPU) of your application. The default is 1, and the maximum is 8. For applications that have blocking operations (for example, I/O), a higher value of ParallelismPerKPU leads to full utilization of KPU resources.
https://docs.aws.amazon.com/kinesisanalytics/latest/java/how-scaling.html
KPUというのが、KDAのプロビジョニングの最小単位であり課金の単位でもあります。
1つのKPUは、1つのvCPU、4GBのメモリ、50GBのストレージで構成され、この単位はKDAでは固定で変更できません。
KPUは上記の2つのパラメータ値に応じて以下の計算で決まります。
Allocated KPUs for the application = Parallelism/ParallelismPerKPU
例えば、Parallelismが4で、ParallelismPerKPUが2なら、KPUの数は2となります。
以前は、上記のパラメータの説明をざっと読んだだけで、処理の並列度とKPU数を増やせばそれだけスケールアウトできるんだな、という程度の認識でしたが、このパラメータが実際の動作にどう反映されるのかを、Flinkのアーキテクチャと照らし合わせて確認してみました。
FlinkクラスタのJobManager/TaskManagerとTaskSlot
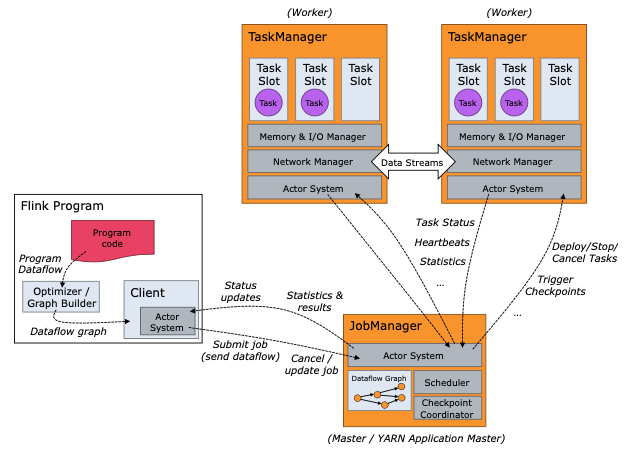
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/
Flinkクラスタは、主にJobManagerとTaskManagerという2つのコンポーネントから成っています。並列分散処理基盤でよく見るパターンで、Hadoop MapReduceのJobTrackerとTaskTrackerの関係に似てますね(名前も)。
実際にタスクが実行されるTaskManager上には、TaskSlotが用意され、TaskSlotにタスクが割り当てられて実行されます。
1つ1つのTaskManagerがそれぞれ1つのJVMプロセスであり、TaskSlot数は1つのTaskManagerプロセス上で同時実行可能なスレッド数というイメージのようです。(ここは厳密にはイメージと違っていたので詳細は「KDAのParallelismとTaskSlotの関係」で後述しています。)
1つのTaskManagerあたりのTaskSlot数はクラスタ構築時に決めるもので、例えば3スロットとした場合は、1つのTaskManagerのリソースが3つのスロットに1/3ずつ割り当てられます。と言っても、1/3ずつ均等に確保されるのはメモリだけで、CPU Isolation(適した日本語がわからない)はされないとのこと。
軽い処理を大量に並列実行したい場合はTaskManagerあたりのTaskSlotの数が多い方がリソース効率がよくなるが、メモリ消費の多い処理を実行したい場合はTaskSlotあたりのメモリ割当が不足しないようにスロット数を抑えた方がよい、という感じでしょうか。
ここまで調べると、KDAのパラメータとFlinkクラスタの構成はおそらく以下の関係になるのでは、という予想がたちました。
- KPUの数 = TaskManagerの数
- ParallelismPerKPU = TaskManagerあたりのTaskSlot数
少なくとも後者については、KDAのドキュメントをよく見たら書いてあったので正しそうです。
The Apache Flink environment allocates resources for your application using units called task slots. When Kinesis Data Analytics allocates resources for your application, it assigns one or more Apache Flink task slots to a single KPU. The number of slots assigned to a single KPU is equal to your application's
ParallelismPerKPUsetting.
https://docs.aws.amazon.com/kinesisanalytics/latest/java/how-resources.html
FlinkのTaskとSubtask
では、このTaskSlotに割り当てられるタスクとはどんなものなのか。
1つ1つのOperatorがそのままタスクの単位になるというのが、私の当初の安易な推測でした。そして、Operatorの結合やOperatorごとの並列度などの最適化はFlink様がよしなにやってくれると期待していました。。。
今回ちゃんと調べてみたところ、半分正解・半分間違いという感じです。
Operatorの結合については、Operator Chainsという仕組みがあり、続けて処理可能な隣接Operatorを結合し1つのタスクとして1スレッド内で処理することで、TaskSlotへのタスク割当やタスク間の通信に伴うオーバーヘッドを抑えてくれるようです。
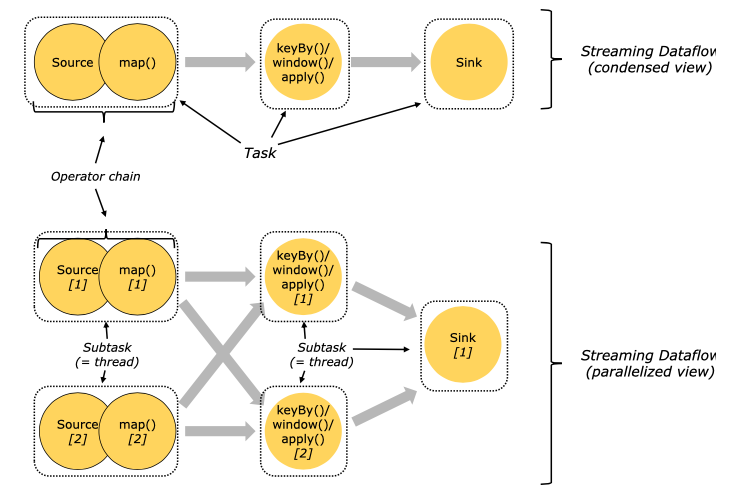
これも、HadoopのPigやHiveで、selectやfilter(where)などの処理を1つのMapタスクにまとめて最適化してくれる(逆にjoinやaggregateはShuffuleを挟んだReduceタスクに分かれる)のに近いですね。
なお、まだ試してはいませんが、Operator Chainsは自動の最適化に任せるだけでなく、どこを繋げてどこを分けるかをコード内で明示的に指定したり無効化することもできるようです。
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/operators/overview/#task-chaining-and-resource-groups
また、ここでSubtaskという用語が出てきており、Taskという用語と使い分けられています。
上記の図を含むドキュメントを読んで、以下だと理解しました。
- Task
- Operator Chainsを行ったうえで、論理的に1つのTaskSlotで実行される処理のまとまりを表す単位。
- Subtask
- 実際にTaskSlotで物理的に実行される処理単位。例えば、あるTaskの並列度が2であれば、2つのSubtaskが生成・実行される。
これまでは、「TaskSlotにタスクを割り当てて実行」と記述していましたが、「TaskSlotにSubtaskを割り当てて実行」と記述する方が正しいようです。
Operator Level のParallelism
では、Taskの並列度はどのように決まるのか。
Flinkには、前述のKDAのパラメータであるParallelismとは別に、Operator LevelのParallelismというものがあり、KDAのドキュメントでもPerformance Best Practicesとして、これを適切に設定することが推奨されています。
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/execution/parallel/#operator-level
https://docs.aws.amazon.com/kinesisanalytics/latest/java/performance-improving.html#performance-improving-scaling-op
軽い処理が多くのTaskSlotを使用したせいで、重い処理が使えるリソースが減って全体のボトルネックとなってしまう、というような事態を防ぐため、軽い処理の並列度は少なく、重い処理の並列度は多くなるよう、明示的に設定することができるようです。
前述のサンプル処理で、Operator LevelのParalellismの設定を試してみました。
サンプル処理内のsource、map、filter、async、sinkそれぞれにParallelismを設定し、FlinkクラスタのWebUIでjob graphを確認します。
最初のパターンは以下です。
| operator | parallelism | |
|---|---|---|
| source | 1 | 入力KDSシャード数が1のため、刈り取りの並列度を上げる意味はないと考えて1 |
| map | 1 | 軽い処理なので1 |
| filter | 1 | 軽い処理なので1 |
| async | 4 | 重い処理なので多めの4 |
| sink | 4 | asyncとの結合を期待して、asyncと同じ4 |
結果は以下となりました。
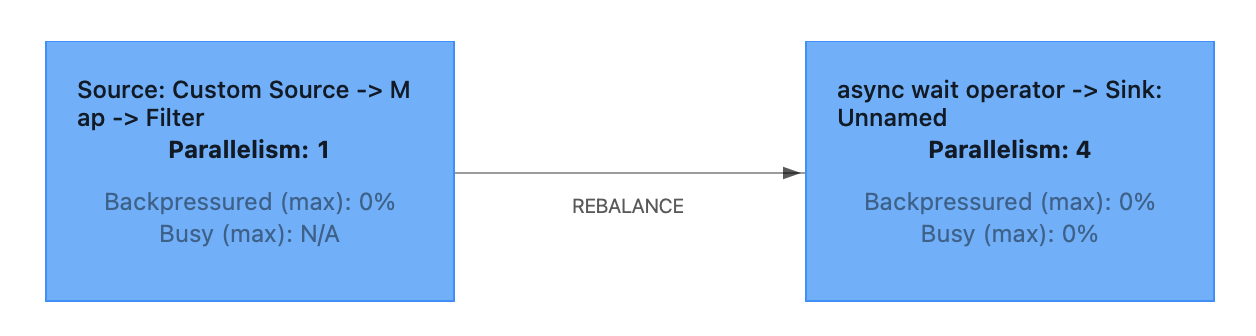
Operator ChainsによりOperatorが結合される条件として、KDAのドキュメントに以下のように記載されています。
Several sequential operators can be chained into a single task if they all operate on the same data. The following are some of the criteria needed for this to be true:
- The operators do 1-to-1 simple forwarding.
- The operators all have the same operator parallelism.
https://docs.aws.amazon.com/kinesisanalytics/latest/java/how-resources.html
このサンプル処理では、いずれのOperatorも入力と出力が1対1(filterは1対0のケースもあり)のため、隣接かつParallelismが同じOperatorが結合されました。
そして、結合された各OperatorのParallelismが、TaskごとのParallelismすなわちSubtaskの数となっています。
次に、mapとfilterのParallelismを変更してみました。
| operator | parallelism | |
|---|---|---|
| source | 1 | |
| map | 4 | 1 → 4 に変更 |
| filter | 4 | 1 → 4 に変更 |
| async | 4 | |
| sink | 4 |
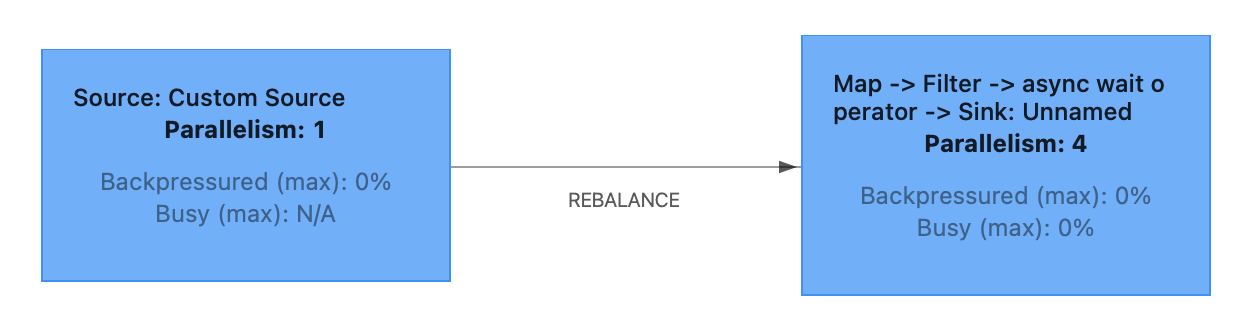
今度は、mapとfilterが、Parallelismが同じ4であるasync側のタスクに結合されています。
ちなみに、この2パターンではどちらの方が良いのでしょうか。
個人的には前者の方が良いと考えています。後者の場合は以下の問題があると考えています。
-
リソース使用が少なくボトルネックにもならないmapとfilterの処理も4並列で実行されるため、軽微とはいえリソースを4倍使用する割には、全体の性能向上には寄与しないと思われる。
-
1つ目のTask内でfilterまで行い、Subtask間の通信が必要となるイベント数を減らした方が、通信に伴うリソース使用を抑えられると思われる。
-
Async I/Oの処理はOperator Chainsの先頭とすべきというドキュメント記載がある。
The operator for AsyncFunction (AsyncWaitOperator) must currently be at the head of operator chains for consistency reasons
For the reasons given in issue FLINK-13063, we currently must break operator chains for the AsyncWaitOperator to prevent potential consistency problems. This is a change to the previous behavior that supported chaining. User that require the old behavior and accept potential violations of the consistency guarantees can instantiate and add the AsyncWaitOperator manually to the job graph and set the chaining strategy back to chaining via AsyncWaitOperator#setChainingStrategy(ChainingStrategy.ALWAYS).
KDAのParallelismとTaskSlotの関係
次に、以下は、Operator LevelのParallelismを設定せず、KDAのParallelismとParallelismPerKPUをそれぞれ5に設定した場合のjob graphです。
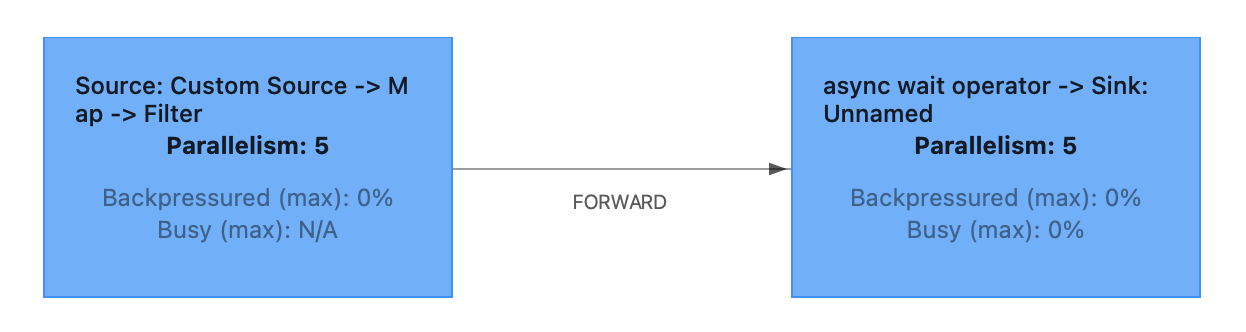
asyncの前でTaskが分かれており、2つのTaskのParallelismはそれぞれ5になっています。
Taskの間の矢印がREBALANCEでなくFORWARDになっているのは、2つのTaskのParallelismが同じのため、各Subtaskの間がShuffuleでなく1対1でデータ転送されるということでしょうか。
実はここで、KDAのParallelismとTaskSlotについて勘違いをしていることに気づきました。
当初の私の理解としては以下でした。
- KDAのParallelismはプロビジョニングするTaskSlotの総数である
- 1つのTaskSlotに割り当てられるSubtaskは1つであり、ストリーム処理で全てのSubtaskが常時動作するためには、Subtaskの総数分のTaskSlotが必要
- つまり、期待するSubtaskの総数をKDAのParallelismとして設定する必要がある
しかし、改めてドキュメントをちゃんと読むと、KDAのParallelismは、OperatorごとのParallelismのデフォルト値なんですね。つまり、Operator LevelのParallelismを以下のように設定した場合と同じ状態になるようです。
- Parallelism — Use this property to set the default Apache Flink application parallelism. All operators, sources, and sinks execute with this parallelism unless they are overridden in the application code. The default is 1, and the default maximum is 256.
| operator | parallelism |
|---|---|
| source | 5 |
| map | 5 |
| filter | 5 |
| async | 5 |
| sink | 5 |
ですが、これだと2つのTaskがそれぞれSubtaskが5なので、TaskSlotが計10個必要かと思いきや、Total Task Slotsは5となっています。なお、Subtaskの総数(下記のTasks)は想定通り10です。
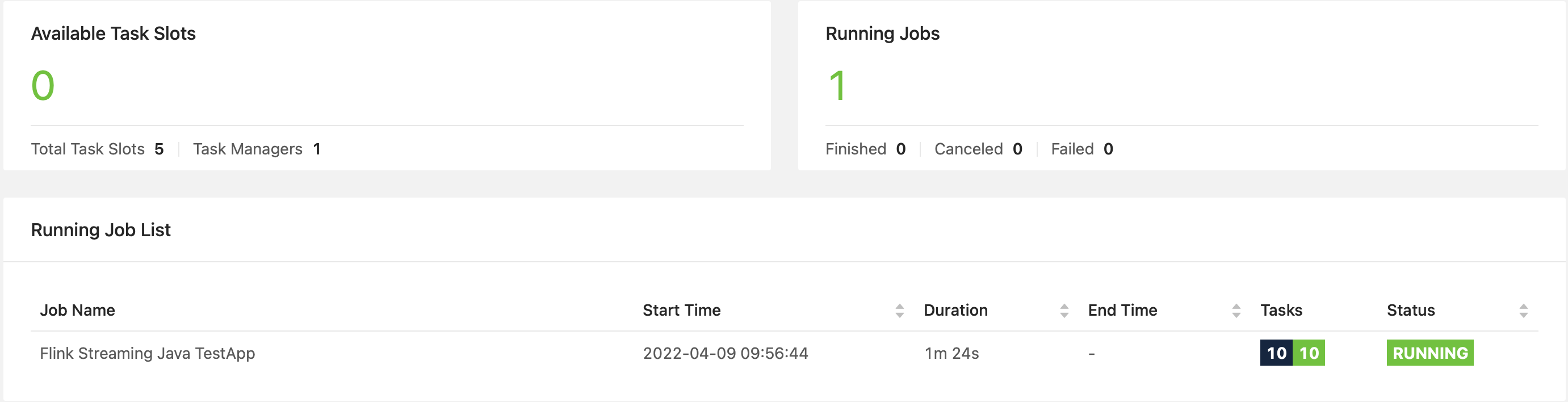
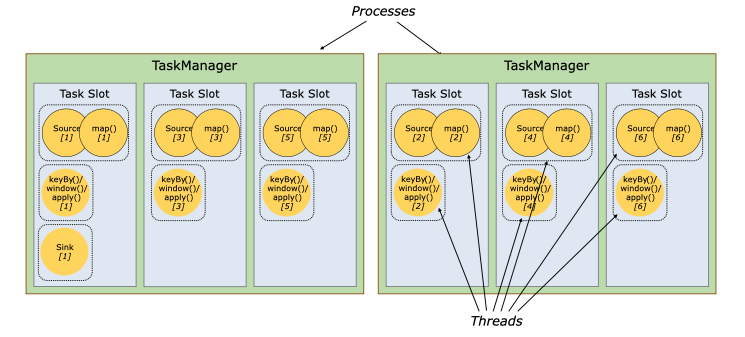
Flinkのドキュメントを見ると、確かに複数のSubtaskが1つのTaskSlotを共有するような記載があります。1つ1つのSubtaskはやはりスレッドのようなので、1つのTaskSlotが1つのスレッドなのではなく、1つのTaskSlot上で複数のスレッド(Subtask)が動作するようです。
By default, Flink allows subtasks to share slots even if they are subtasks of different tasks, so long as they are from the same job. The result is that one slot may hold an entire pipeline of the job. Allowing this slot sharing has two main benefits:
- A Flink cluster needs exactly as many task slots as the highest parallelism used in the job. No need to calculate how many tasks (with varying parallelism) a program contains in total.
- It is easier to get better resource utilization. Without slot sharing, the non-intensive source/map() subtasks would block as many resources as the resource intensive window subtasks. With slot sharing, increasing the base parallelism in our example from two to six yields full utilization of the slotted resources, while making sure that the heavy subtasks are fairly distributed among the TaskManagers.
KDAの動作を確認したところ、以下となることがわかりました。
- プロビジョニングされるTaskSlot数 = KDAのParallelism
- 使用されるTaskSlot数 = Operator LevelのParallelismの最大値
- 使用されないTaskSlot数 = KDAのParallelism - Operator LevelのParallelismの最大値
そのため、KDAのParallelismには、Operator LevelのParallelismの中で最も大きな値を設定すればよいことになります。
それより大きい場合は、Available Task Slotsとして余るTaskSlotが生まれ、使用されないメモリ領域ができてしまうことになります。
それより小さい場合は、以下のエラーが発生しました。
org.apache.flink.client.program.ProgramInvocationException: Maximum parallelism in Flink code is greater than provisioned parallelism
なお、このエラーの発生時は、KDAのステータスとしては「実行中」にも関わらず、FlinkクラスタのWebUIで見るとジョブが実行中となっておらず動作していない状態となってしまうため、注意が必要です。
負荷試験
Operator LevelのParallelismの設定のよる性能への影響の確認のため、ちょっとした負荷試験も行ってみました。
ただ、お金と時間をケチって、入出力KDS1シャード・1KPUに対し100tps × 5分間というさほど高くない負荷、かつパターンごとに1回ずつのみ測定のため、大きな差異は出ず精度も微妙であり、あくまで参考値となります。
構成
試験時の構成は以下となります。

- 入力KDSへの負荷投入にはKinesis Data Generator(以降、KDGと記述)を使用
- レコードテンプレート:
{{date.now("x")}},{{random.number(99)}},ping- 送信時刻のunixtime
- 0~99の任意の数値。下1桁が0のレコードはfilterで破棄(全体の約1/10のレコードが破棄される想定)
-
ping固定値(特に意味はない)
- レコードテンプレート:
- 出力KDSのレコードはLambdaで刈り取ってKinesis Data Firehose(以降、KDFと記述)にDirectPutし、S3に出力
- 以下の時刻を出力レコードに付与し、各処理間のレイテンシーを確認する
- input:入力KDSのデータ受信時刻。入力KDSのapproximateArrivalStampをKDAのsourceで取得して使用。
- source:KDAアプリケーション内のsourceからのデータ受信時刻。mapの処理開始直後の時刻を使用。
- sink:KDAアプリケーション内のsinkへのデータ送信時刻:asyncの処理終了直前の時刻を使用
- output:出力KDSのデータ受信時刻。出力KDSのapproximateArrivalTimestampをLambda刈り取り時に取得して使用。
コード
サンプル処理のコードの主要部分を抜粋して記載します。コード全体は以下のリポジトリをご参照ください。
https://github.com/ynstkt/flink-test
以下のサンプルコードをベースにしたものとなっています。
https://github.com/aws-samples/amazon-kinesis-data-analytics-java-examples/tree/master/GettingStarted
メイン処理(データフロー組み立て部分を抜粋)
boolean enableOperatorParallelism =
!this.applicationProperties.isEmpty()
&& parseBoolean(this.applicationProperties.getProperty("enableOperatorParallelism"));
SingleOutputStreamOperator<String> sourceStream =
see.addSource(this.source, TypeInformation.of(String.class));
if (enableOperatorParallelism) {
sourceStream.setParallelism(parseInt(this.applicationProperties.getProperty("sourceParallelism")));
}
SingleOutputStreamOperator<Tuple2<String, Long>> mappedStream =
sourceStream.map(new SimpleMapFunc());
if (enableOperatorParallelism) {
mappedStream.setParallelism(parseInt(this.applicationProperties.getProperty("mapParallelism")));
}
SingleOutputStreamOperator<Tuple2<String, Long>> filteredStream =
mappedStream.filter(new SimpleFilterFunc());
if (enableOperatorParallelism) {
filteredStream.setParallelism(parseInt(this.applicationProperties.getProperty("filterParallelism")));
}
SingleOutputStreamOperator<String> asyncStream =
AsyncDataStream.unorderedWait(
filteredStream,
new SimpleAsyncFunc(),
3000,
TimeUnit.MILLISECONDS,
100);
if (enableOperatorParallelism) {
asyncStream.setParallelism(parseInt(this.applicationProperties.getProperty("asyncParallelism")));
}
DataStreamSink<String> sinkStream = asyncStream
.addSink(this.sink);
if (enableOperatorParallelism) {
sinkStream.setParallelism(parseInt(this.applicationProperties.getProperty("sinkParallelism")));
}
メイン処理(sourceでapproximateArrivalTimeStampを付与する部分を抜粋)
private static SourceFunction<String> createSourceFromStaticConfig() {
Properties inputProperties = new Properties();
inputProperties.setProperty(ConsumerConfigConstants.AWS_REGION, region);
inputProperties.setProperty(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST");
return new FlinkKinesisConsumer<>(inputStreamName, new KinesisDeserializationSchema<String>() {
@Override
public String deserialize(byte[] recordValue,
String partitionKey,
String seqNum,
long approxArrivalTimestamp,
String stream,
String shardId) throws IOException {
String recordValueStr = new String(recordValue, StandardCharsets.UTF_8);
return approxArrivalTimestamp + "," + recordValueStr;
}
@Override
public TypeInformation<String> getProducedType() {
return null;
}
}, inputProperties);
}
Operator
package org.example.operators;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
public class SimpleMapFunc implements MapFunction<String, Tuple2<String, Long>> {
@Override
public Tuple2<String, Long> map(String value) {
Long sourceTime = System.currentTimeMillis();
return new Tuple2<>(value, sourceTime);
}
}
package org.example.operators;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.java.tuple.Tuple2;
public class SimpleFilterFunc implements FilterFunction<Tuple2<String, Long>> {
@Override
public boolean filter(Tuple2<String, Long> value) {
// フィルタ用番号を取得
String number = value.f0.split(",")[2];
// フィルタ用番号の下1桁
String last = number.substring(number.length() - 1);
// 下1桁が0のレコード(全体の約10分の1)は破棄
boolean result = !last.equals("0");
return result;
}
}
package org.example.operators;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Executors;
import java.util.function.Supplier;
public class SimpleAsyncFunc extends RichAsyncFunction<Tuple2<String, Long>, String> {
@Override
public final void asyncInvoke(Tuple2<String, Long> input, final ResultFuture<String> resultFuture) {
CompletableFuture<String> result = new CompletableFuture<>();
Executors.newCachedThreadPool().submit(() -> {
Thread.sleep(1000); // 1秒かかる重い処理を擬似
result.complete("");
return null;
});
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
}).thenAccept((String resultStr) -> {
String payload = input.f0;
long sendTime = Long.parseLong(payload.split(",")[1]);
long inputTime = Long.parseLong(payload.split(",")[0]);
long sendToInput = inputTime - sendTime;
long sourceTime = input.f1;
long inputToSource = sourceTime - inputTime;
long sinkTime = System.currentTimeMillis();
long sourceToSink = sinkTime - sourceTime;
String output = sinkTime
+ "," + sourceToSink
+ "," + sourceTime
+ "," + inputToSource
+ "," + sendToInput
+ "," + payload;
resultFuture.complete(Collections.singleton(output));
});
}
}
出力KDS刈り取りLambda
const aws = require('aws-sdk');
aws.config.update({
region: 'ap-northeast-1',
});
const firehose = new aws.Firehose();
exports.handler = async (event, context) => {
const processTime = new Date().getTime();
const results = [];
for (const record of event.Records) {
// Kinesis data is base64 encoded so decode here
const payload = Buffer.from(record.kinesis.data, 'base64').toString('utf-8');
const sinkTime = parseInt(payload.split(',')[0]);
const outputTime = record.kinesis.approximateArrivalTimestamp * 1000;
const sinkToOutput = outputTime - sinkTime;
const outputToProcess = processTime - outputTime;
const result = `${processTime},${outputToProcess},${outputTime},${sinkToOutput},${payload}`;
results.push(result);
}
await putToFirehose(results);
return `Successfully processed ${event.Records.length} records.`;
};
async function putToFirehose(records) {
const dataObj = records.map(record => {
return { Data: record }
});
const params = {
DeliveryStreamName: 'kds-consumer-to-s3',
Records: dataObj
};
try {
await firehose.putRecordBatch(params).promise();
} catch(e) {
console.log(e);
}
}
測定結果
測定結果のサマリが以下となります。

なお、入力KDSのIteratorAgeMillisecondsは測定中ずっと0で、処理遅延等は発生していません。
各パターンでのタスク構成(job graph)は前述のとおりです。
結果のうち気になった部分(赤字)の考察です。
-
mapとfilterのParallelismを4としてasync以降と結合したTaskとした場合(測定結果2行目)
- 他パターンと比べてCPU/MEM使用率が比較的高めになっています。これはmapとfilterの処理も4並列で実行された影響と思われます。それでも全体のレイテンシー(input〜output)は他パターンとほぼ同じなので、リソース効率が悪いと言えそうです。
- Subtask間の通信が発生する箇所がsourceとmapの間になるため、input~sourceのレイテンシーが他より100msほど長くなっており、逆にsource~sinkは1つのSubtask内で処理されるので他より100msほど短くなっています。全体のレイテンシーとしては変わっていません。
-
Operator LevelのParallelismを設定しない場合(測定結果3行目)
- source、map、filterを含むTaskが5並列となるため、上記同様にリソース使用率が上がるかと思いきや、そうはなっていません。これは、入力KDSシャード数が1のため、sourceを含むSubtaskが5つあっても実質1つしか動作していないためと思われます。
Note that the configured parallelism of the Flink Kinesis Consumer source can be completely independent of the total number of shards in the Kinesis streams. When the number of shards is larger than the parallelism of the consumer, then each consumer subtask can subscribe to multiple shards; otherwise if the number of shards is smaller than the parallelism of the consumer, then some consumer subtasks will simply be idle and wait until it gets assigned new shards (i.e., when the streams are resharded to increase the number of shards for higher provisioned Kinesis service throughput).
駄文
本記事内では負荷試験については最後に記載してますが、実際には先に負荷試験をやってから、なんでこうなるんだろ?とドキュメントを調べはじめて、だんだん理解できてきた感じです。
蛇足ですが、実施時にハマった部分があったので、備忘のため記載しておきます。
1つ目のパターンを最初に実施した際、レイテンシーが徐々に遅くなる(5分継続すると最終的に10秒近くまで延びる)という事象が起きていました。
そのため、最初はKDG送信〜Lambda受信で大まかにレイテンシー取得していたのですが、処理間のレイテンシーを細かく取得するように変えました。
すると、input〜sourceの部分が徐々に遅くなっていることがわかりました。実は最初はmapの処理中に(あまり深く考えず)Thread.sleep(10)を入れており、それが原因でした。source、map、filterがOperator Chainsで1つのTaskとなり、1つのSubtask(スレッド)内で動作していたため、mapだけでなくsourceも含めてスレッドごとsleepしてしまったせいだと思われます。
Operator Chainsについてもまだよくわかっていない状態だったので、原因特定までに無駄に時間がかかってしまいましたが、今回の勉強をするための良い機会になりました。
まとめ
- KDAのParallelismとKPU
- KDAの主要なチューニングパラメータとしてParallelismとParallelismPerKPUがある
- KPUはKDAでプロビジョニングされる最小単位であり、1vCPU、4GBメモリ、50GBストレージから成る
- KPU数=Parallelism/ParallelismPerKPU(小数切り上げ)
- FlinkクラスタのJobManager/TaskManagerとTaskSlot
- FlinkクラスタはJobManagerとTaskManagerで構成される
- 1つ1つのTaskManagerはそれぞれ1つのJVMプロセス
- 1つのTaskManagerには複数のTaskSlotが用意され、各TaskSlotにはTaskManagerのメモリが均等に割り当てられる
- Operatorの処理はTaskSlotに割り当てられて実行される
- KDAのParallelismはプロビジョニングされるTaskSlotの総数
- ParallelismPerKPUは1KPUあたりのTaskSlot数
- FlinkのTaskとSubtask
- Taskは、TaskSlot上で1つのスレッドで実行される処理のまとまりを表す論理的な単位
- Operator Chainsにより、隣接するOperatorは、最適化によって適宜1つのTaskに結合される
- Subtaskは、実際にTaskSlotで実行される物理的な処理単位であり、TaskごとにParallelismの数だけ生成される
- Operator Level のParallelism
- アプリケーションコード内で、Operatorごとの並列実行数を指定できる
- Operator Chainsでは、隣接するOperatorで入力と出力が1対1かつParallelismが同じものが1つのTaskに結合される
- 1つのTaskに結合されたOperatorのParallelismが、そのTaskのParallelismすなわちSubtaskの数となる
- KDAのParallelismとTaskSlotの関係
- KDAのParallelismは、Operator LevelのParallelismのデフォルト値となり、Operator LevelのParallelismが指定されていないOperatorで採用される
- 各TaskのSubtaskはそれぞれ別のTaskSlotに割り当てられる
- 1つのTaskSlotには、異なるTaskのSubtaskが複数割り当てられ、1つのSubtaskは1つのスレッドとして動くため、1つのTaskSlot上では複数スレッドが同時実行されうる
- 1つのジョブで使用されるTaskSlotの総数は、そのジョブに含まれるOperator LevelのParallelism(=TaskのParallelism)の最大値となる
- KDAのParallelismには、Operator LevelのParallelismの最大値を設定すればよい