D3.js によるデータの可視化はインタラクション、探索的データ可視化といったメリットをもたらします。見た目にも動的で派手、かっこいいといった特徴があります。
以前に D3.js について書いた記事を振り返って見ます。
D3.js + NVD3 + Sinatra + Heroku で作るインタラクティブなデータ可視化デモ
http://qiita.com/ynakayama/items/f661b493751370ee6568
これと対照的なのが説明的データ可視化であり、これは「一目でわかること」において優れています。延々とアニメーションを見る、ポインティングデバイスを動かすなどのインタラクションをおこなわなければならないといった可視化は、一目で素早く全貌を理解するといった説明的データ可視化には不向きです。
説明的データ可視化の例を挙げてみましょう。次の例は以前にもいくつかの例を挙げた matplotlib による複雑な金融データのプロットの例です。
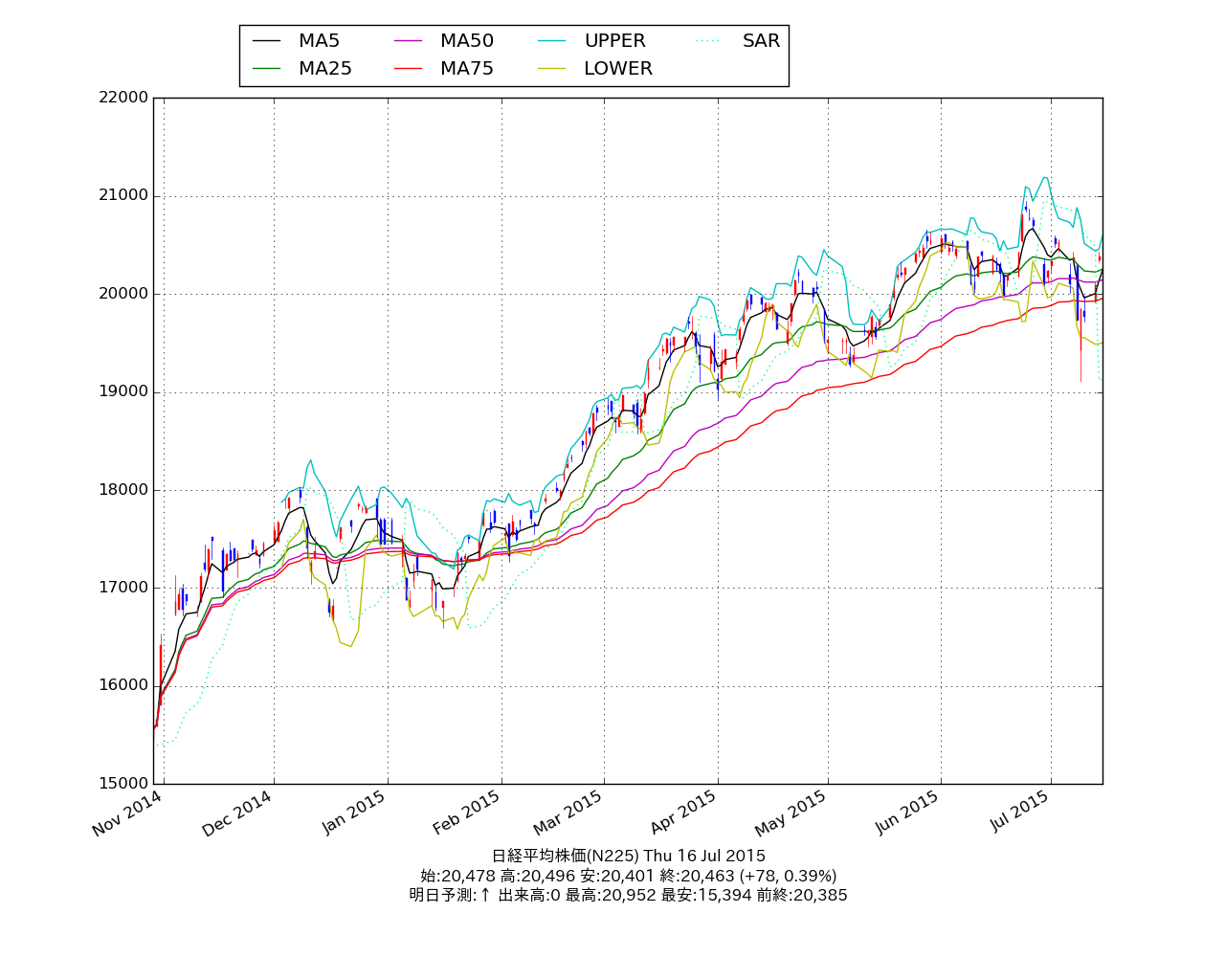
上の画像を見ると、最近ズドンと下げた場面はあるものの、大きなトレンドとしては方向性を失っていない、一時的なものである可能性が高いといったことがひと目で読み取れるのではないかと思います。
このように複数の指標を同時に掲載するきめ細やかな複合チャートを作成するといった場面では matplotlib による説明的データ可視化は非常に優れています。 pandas によるデータ分析の例や scikit-learn といった機械学習ライブラリでの分析の例など今までも過去の記事でたくさん取り上げてきましたが、これらと同じ Python という言語で一貫して記述することができるのも多いに強みです。 matplotlib というその名前の通り、数学的なデータの可視化において強力です。
それでは D3.js を利用してインタラクションを実現するメリットは何でしょうか。まず豊かな表現力です。たとえばこちらを見るとグラフ描画ツールとしてインパクトのあるビジュアルを実現できることがわかるでしょう。このように、より見られる可視化、継続的な可視化を実現します。また時間に変数を割り当てる、すなわち時間とともに変化していくアニメーションによって可視化を実現することもできます。
すなわち、使いどころをまちがえず、適切な可視化をすることを前提に考えていく必要があります。
pandas のデータフレームから D3.js にデータを渡す
さてここからが本題です。
D3.js は基本的には JSON を元データとして可視化を提供します。データの形式は大雑把には次のようになっています。
[
{
"label":"a",
"value":10
},
{
"label":"b",
"value":20
},
]
データ構造についての入門としては以下の情報も参考になります。
Data Structures D3.js Accepts
https://www.dashingd3js.com/data-structures-d3js-accepts
D3.js でデータを読み込むには次のようにします。
// JSON のファイルを指定
d3.json("d3.json", function(error, data){
// サンプルのための簡単な計算
var text = "";
for(var i=0; i<data.length; i++){
text += data[i].label + " = " + data[i].value + "<br>";
}
// 要素を選択
d3.select("#result").html(text);
});
HTML に要素を用意しておきます。
<div id="result"></div>
さて、いっぽうデータの分析には pandas を使います。
したがって可視化のためには pandas のデータセットから D3.js で使えるように渡す必要があるわけです。いくつかの案を挙げてみます。
- D3js から直接 csv ファイルを読み込む
- pandas のデータセットを直接 JSON にして保存する
- 一度 csv に吐き出してから JSON に変換する
直接 csv からデータを読み込む例としては次のようなやり方があります。
http://dataisfun.org/2014/05/20/?p=299
この例では csv に保存された株価から終値を取り出してチャートを作っています。 JavaScript 側で色々と調整するのが得意なのであれば D3.js は csv ファイルを読めますのでこのようにすると良いでしょう。
また pandas 側にも JSON でデータを吐き出すメソッドが用意されています。
df.head(3).to_json()
# => '{"Open":{"1262563200000":878.0,"1262649600000":878.0,"1262736000000":887.0},"High":{"1262563200000":878.0,"1262649600000":886.0,"1262736000000":887.0},"Low":{"1262563200000":855.0,"1262649600000":864.0,"1262736000000":872.0},"Close":{"1262563200000":866.0,"1262649600000":883.0,"1262736000000":885.0},"Volume":{"1262563200000":45000.0,"1262649600000":67300.0,"1262736000000":48300.0},"Adj Close":{"1262563200000":866.0,"1262649600000":883.0,"1262736000000":885.0}}'
D3.js には強力なデータハンドリング機能もありますが、柔軟なのは csv を json に書き換える方法です。途中に変換のステップをもうけることで、必要に応じたデータの形式にあらかじめ書き換えておくことができます。
最終的に Sinatra + D3.js によるアプリで表示することを想定し Ruby で変換をしてみます。
# ファイルの形式変換
def transform_file(filename)
array = []
# CSV ファイルを読み込む
table = CSV.table(File.expand_path(filename), encoding: "UTF-8")
keys = table.headers # 先頭行をキーを取り出す
# CSV ファイル全体を一行ずつ処理
CSV.foreach(File.expand_path(filename), encoding: "UTF-8" ) do |row|
# キーで列にアクセスできるようにするためにハッシュに変換する
hashed_row = Hash[*keys.zip(row).flatten]
#=> {:date=>"2015-05-08",
# :open=>"19315.63086",
# :high=>"19458.75",
# :low=>"19302.71094",
# :close=>"19379.18945",
# :volume=>"176200.0"}
# 日付を主キーにする
pri_key = hashed_row[:date]
# 先頭行を処理対象にしない
unless pri_key == "Date"
# JSON の UNIXTIME に変換するとき 1,000 倍するのに注意
unixtime = Time.parse(pri_key).to_i
array.push([unixtime * 1000, hashed_row[:ret_index].to_f])
end
end
hash = {"key" => filename, "values" => array}
return hash
end
# ハッシュを JSON に書き出すメソッド
def write_file(filename, array)
# pretty_generate メソッドを利用すると整形された JSON にできる
File.write(
File.join(@out_dir, File.basename(filename)),
JSON.pretty_generate(array)
)
end
まとめ
pandas のデータを D3.js で表示するとき、データをどう渡すかというのは地味で面倒ですが重要なステップです。
あらかじめ D3.js で取扱いやすいように柔軟な方法を採用すればあとで細かな調整変更ができて便利です。