今回の記事は一応前回の続きなのですが、 scikit-learn による機械学習を利用して、実際に未来を予測する話を書いていきたいと思います。
なにはともあれ、まずは以下の図をみてください。
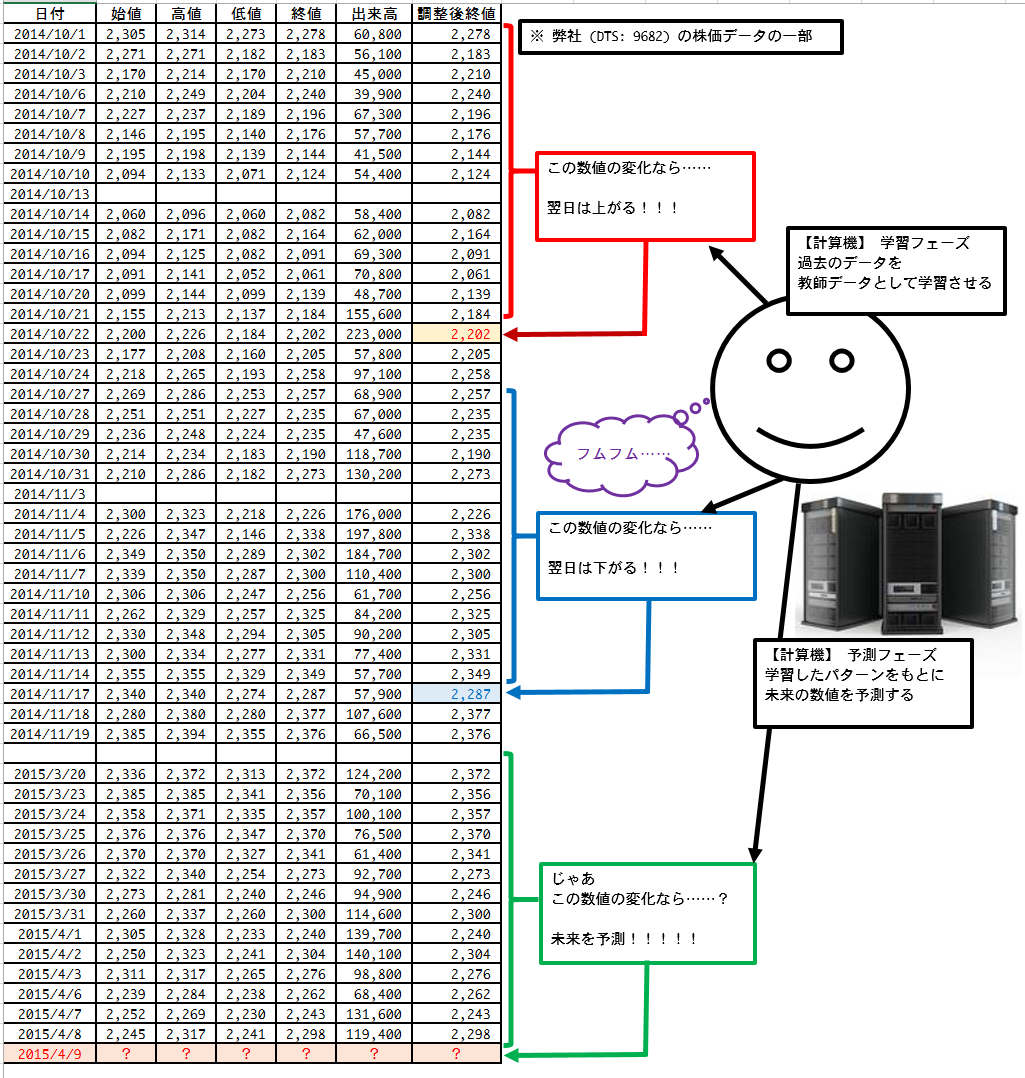
今回も実験対象のデータとして株価データを利用します。
上の図に挙げたのは弊社 (DTS) の株価であり、本物のデータです。
図にあるように「過去の株価の変化から結果どうなったのか」という情報を、機械学習を利用して計算機に学習させ、それをもとに将来の株価を予測してみます。
決定木アルゴリズム
今回は数ある分類の手法の中から決定木 (デジジョン・ツリー) を利用します。手法の選択理由は以前に書いた記事を参考にしてください。
決定木自体の説明は Wikipedia あたりを読んでいただくと早いかと思います。
また scikit-learn に実装されている決定木についての説明は公式ドキュメントにあります。
ドキュメントを読むと英語でなにやら難しいことが書いてあるように見えますが、 scikit-learn の使い方はひとことで言うと要は教師データの数値の配列 (train_X) と結果の配列 (train_y) を学習させ、テストデータの数値の配列 (test_X) を与えると予測結果 (test_y) が帰ってくるというそれだけです。
今回は使い方に焦点を当てているので詳しい理論は省略し、さっそく試してみることにしましょう。
執筆時点での株価データは次の通りです。
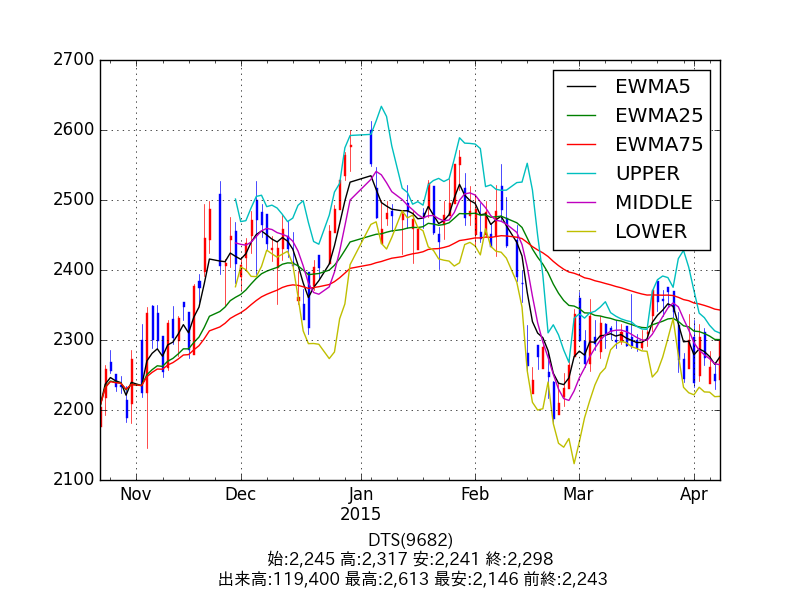
これは DTS(9682) の 4/8 から過去 120 営業日のデータを matplotlib でプロットしたものです。
なお日足チャートの赤は陽線、青は陰線、 EWMA は指数平滑移動平均、残りの 3 本はボリンジャーバンドです。
教師データをつくる
まずは一番面倒な株価の調整後終値から教師データを作るまでのコードを用意します。これは終値のリストを渡すと train_X と train_y が返るようにすれば良いでしょう。
def train_data(arr):
train_X = []
train_y = []
# 30 日間のデータを学習、 1 日ずつ後ろにずらしていく
for i in np.arange(-30, -15):
s = i + 14 # 14 日間の変化を素性にする
feature = arr.ix[i:s]
if feature[-1] < arr[s]: # その翌日、株価は上がったか?
train_y.append(1) # YES なら 1 を
else:
train_y.append(0) # NO なら 0 を
train_X.append(feature.values)
# 上げ下げの結果と教師データのセットを返す
return np.array(train_X), np.array(train_y)
これで train_X (教師データの配列) と train_y (それに対する 1 か 0 かのラベル) が返ってきます。
リターンインデックスを算出する
さて、生の株価データそのままですと、会社ごとに価格帯も全然ちがいますから教師データとしてはちょっと使いづらいです。正規化しても良いのですが、ここは資産価値の変化をあらわすリターンインデックスに注目しましょう。算出方法は前回も書きましたがこのように pandas で求まります。
returns = pd.Series(close).pct_change() # 騰落率を求める
ret_index = (1 + returns).cumprod() # 累積積を求める
ret_index[0] = 1 # 最初の値を 1.0 にする
リターンインデックスの変化を決定木に学習させる
さてここからがキモです。
こうして求まったリターンインデックスから教師データを抽出し分類器に学習させます。
# リターンインデックスを教師データを取り出す
train_X, train_y = train_data(ret_index)
# 決定木のインスタンスを生成
clf = tree.DecisionTreeClassifier()
# 学習させる
clf.fit(train_X, train_y)
これであとは clf.predict() 関数にテストデータを渡すことで予測結果が返ってくるようになります。
1 が返ってくれば株価は「上がる」
0 が返ってくれば株価は「下がる」
と予測されたことになります。
うまく学習したかどうか分類器を試す
さっそく試してみましょう。
まずはテストとして、教師データとまったく同じデータをテストデータとして流してみます。
test_y = []
# 過去 30 日間のデータでテストをする
for i in np.arange(-30, -15):
s = i + 14
# リターンインデックスのt全く同じ期間をテストとして分類させてみる
test_X = ret_index.ix[i:s].values
# 結果を格納して返す
result = clf.predict(test_X)
test_y.append(result[0])
print(train_y) # 期待すべき答え
# => [1 1 1 0 1 1 0 0 0 1 0 1 0 0 0]
print(np.array(test_y)) # 分類器が出した予測
# => [1 1 1 0 1 1 0 0 0 1 0 1 0 0 0]
おや、まったく同じ。すなわち全問正解のようですね。
4/9 の終値を予測する
では執筆時点 4/9 の株価を予測してみましょう。
4/8 までの 90 営業日のデータをもとに予測するとこうなりました。
[ 1.00834065 1.01492537 1.04126427 1.03424056 1.03467954 1.0403863
1.02765584 0.99780509 0.98595259 1.00965759 0.9833187 1.01141352
0.99912204 0.99297629] # 4/8 までの 14 日間のリターンインデックス
[0] # そこから導かれる予測
答えは 0 、つまり株価は下がることになります。
さて、案の定 4/9 の市場終了後に Yahoo! ファイナンスのページを見てみますと
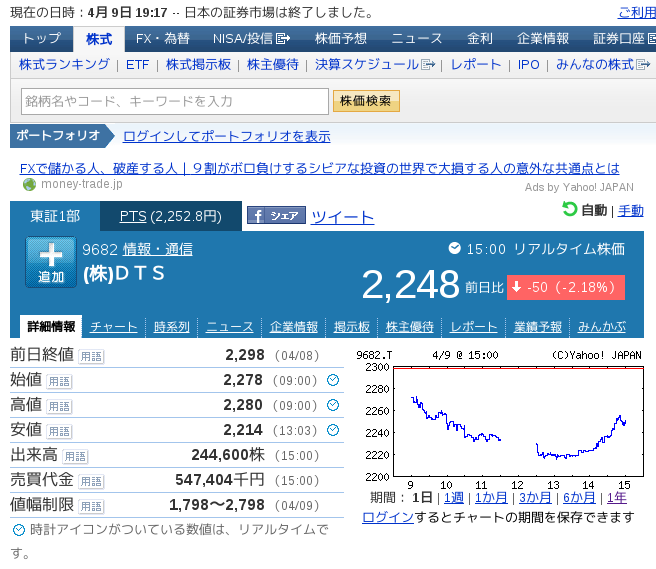
50 円安、つまり決定木の予測通り、株価は下がったことになります。正解です。
4/10 の終値を予測する
では最後に未来の予測にチャレンジしてみましょう。 4/10 の終値を予測します。
なお、しつこいようですがこの記事の執筆日は 4/9 です。ご確認ください。
[ 1.01492537 1.04126427 1.03424056 1.03467954 1.0403863 1.02765584
0.99780509 0.98595259 1.00965759 0.9833187 1.01141352 0.99912204
0.99297629 0.98463565] # 4/9 までの 14 日間のリターンインデックス
[1] # 決定木は 1 と予測
答えは 1 、つまり、明日は株価が上がると予測されました。
まとめ
いかがでしたでしょうか。なかなか興味深い予測ができたのではないかと思います。
これが百発百中の的中率であるなら、今日買って明日売れば利益を上げることができますね。
もしかしたら予測が外れて、明日の今頃は我ながら残念な記事を書いてしまったと頭を抱えているかもしれません。
投資家は株価チャートを目で必死にながめて、明日上がるか下がるかと頭の中で予測をしていることかと思います。
今回書いたのは、機械学習の手法である決定木を用いて、これを計算機にやらせてみるということを試しました。
いわゆる人工知能ですね。
もちろんここに書いてあることを参考に実際にみなさまが本物の取引をされましても一切保証致しませんし、損害が発生したとしても筆者は一切の責任を負えません。その点はあらかじめご了承ください。