前回は scikit-learn に実装されている機械学習の手法をざっくりと書いてみたのですけれども、それなりに需要がありそうなので今日から scikit-learn を使った機械学習のサンプルコードを書きつつ、その手法の理解と実践に迫ってみたいと思います。
まずは以前にもやった K 平均法によってクラスタリングをする例を挙げていきます。
K 平均法はクラスタリングの中でも基本的な手法で、シンプルで高速に動作しますし、入門にも最適です。動作についての説明は毎回おすすめしているのですがこのあたりがわかりやすいです。
クラスタリングする対象としてはやはり株価データを利用します。
株価のデータは
- 無料で誰でも入手することができる
- 企業の「業績」を示す指標となるリアルなデータである
- 定量的なデータであるため分析しやすい
といった特長があるため扱いやすいのです。
企業の業績と株価は密接な関係にあります。この 2 つには、実際には半年から 3 年程度のズレがあると言われています。それは投資家たちが将来の業績に対して投資をするからです。
つまりは株価には将来の業績が織り込み済みであるわけです。たとえば IT 投資やその需要を予測するにあたり、業績の伸びている分野に対しては IT 需要も見込まれるであろうというシンプルな営業戦略を考えることができます。
今回は以下の会社のデータを分析してみます。いずれも弊社 (DTS) と近い会社です。
| 銘柄 | 会社名 |
|---|---|
| 9682 | DTS |
| 9742 | アイネス |
| 9613 | NTTデータ |
| 2327 | 新日鉄住金ソリューションズ |
| 9640 | セゾン情報システムズ |
| 3626 | ITホールディングス |
| 2317 | システナ |
| 4684 | オービック |
| 9739 | NSW |
| 4726 | ソフトバンク・テクノロジー |
| 4307 | 野村総合研究所 |
| 9719 | SCSK |
| 4793 | 富士通ビー・エス・シー |
| 4812 | 電通国際情報サービス |
| 8056 | 日本ユニシス |
リターンインデックス
金融の世界におけるリターンとは通常はある日を起算日とした資産価格のパーセント変化を指します。単純なリターンインデックスは pandas を利用して次のように求まります。
returns = pd.Series(close).pct_change() # 騰落率を求める
ret_index = (1 + returns).cumprod() # 累積積を求める
ret_index[0] = 1 # 最初の値を 1.0 にする
複数の企業に注目したとき、ある日の価格を基準に 1 とし、資産の価値がどのように変化するかをリターンインデックスで測ります。
たとえばこの記事の執筆日からさかのぼって直近の 30 日間のリターンインデックスを求めてみましょう。
# csv ファイルからの時系列データ読み込み
df = pd.read_csv(csvfile,
index_col=0, parse_dates=True)
df = df[-30:] # 直近の 30 日間
# リターンインデックスを求めてリストにする
indexes = get_ret_index(df)['ret_index'].values.tolist()
# DTS を表示
if stock == "9682":
ts = df.index.values
for t, v in zip(ts, indexes):
print(t,v)
# =>
# 2015-02-23 1.0
# 2015-02-24 1.010054844606947
# 2015-02-25 1.020109689213894
# 2015-02-26 1.0351919561243146
# 2015-02-27 1.0680987202925045
# ...
# 2015-04-01 1.0237659963436931
# 2015-04-02 1.0530164533820843
# 2015-04-03 1.040219378427788
というわけです。
今回は直近 30 日分の値を素性としてクラスタリングをしてみましょう。すなわち上記がそのまま 30 次元のベクトルになります。
K-Means クラスタリング
ここでは仮に k=4 とします。
kmeans_model = KMeans(n_clusters=4, random_state=30).fit(features)
labels = kmeans_model.labels_
for label, name, feature in zip(labels, names, data):
print(label, name)
# =>
# 2 9742
# 1 9682
# 2 9613
# 1 2327
# 3 9640
# 1 3626
# 1 2317
# 2 4684
# 0 9739
# 0 4726
# 2 4307
# 1 9719
# 0 4793
# 0 4812
# 1 8056
このように所属するクラスタの番号と銘柄コードが表示されました。
可視化
これだけだと分かり辛いので可視化してみましょう。
df = pd.DataFrame(df, index=ts)
plt.figure()
df.plot()
plt.subplots_adjust(bottom=0.20)
plt.legend(loc="best")
plt.savefig("cluster.png")
plt.close()
まずこれがクラスタ 0 番です。
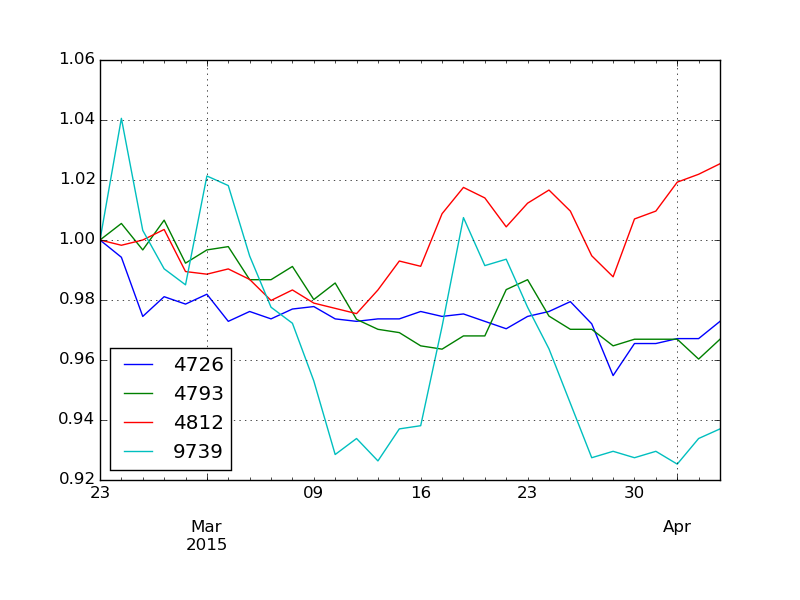
可視化してみると 3 月に下方への振れ幅がけっこうあった銘柄が固まっていることがわかります。
次にクラスタ 1 番。
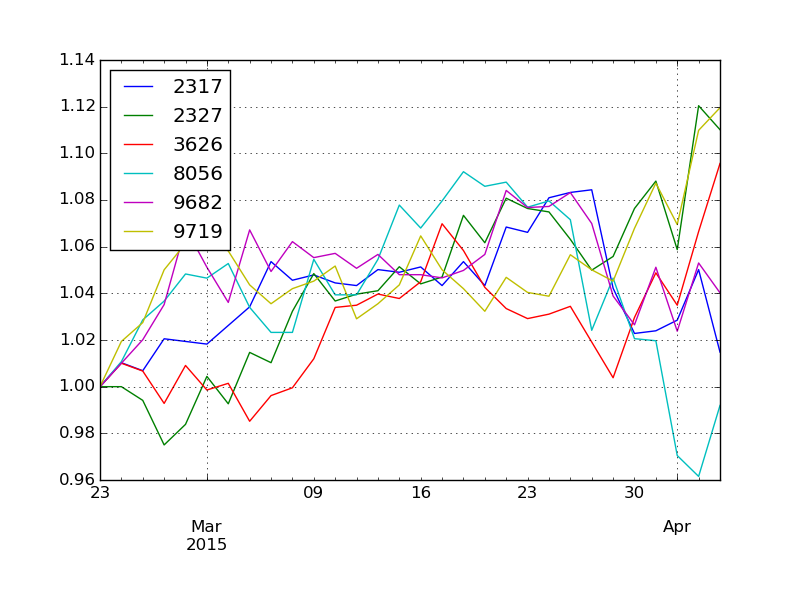
こちらは多少の値動きの幅を伴いつつも、期末の決算へ向けて価格を上げていった銘柄が集まっています。
クラスタ 2 番。
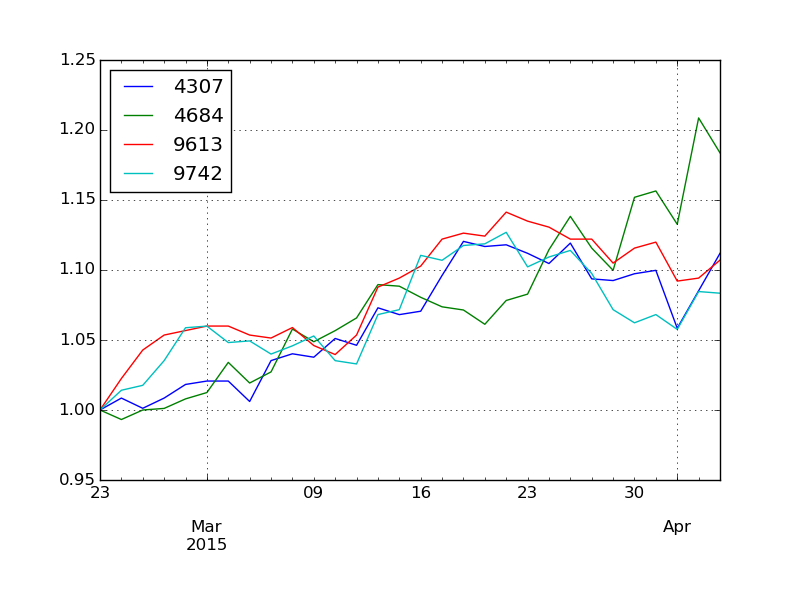
右肩上がりに価値を上げていった会社が集まっています。この 4 社の業績は順調だったと言えるでしょう。
クラスタ 3 番はややイレギュラーな動きをした会社が選ばれたようです。
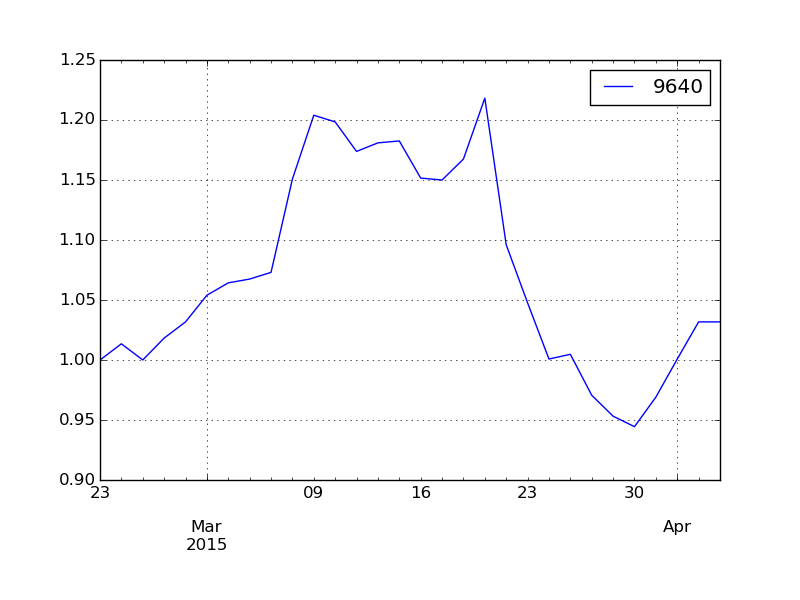
このように似た値動きをした会社ごとにクラスタが形成されました。銘柄と会社名の関連は上の表を参照してください。
今回は SIer の銘柄のみを対象としましたが、やろうと思えばそれ以外の上場企業全銘柄のデータから似た銘柄を導き出すといったこともできます。
日本取引所 - その他統計資料
http://www.jpx.co.jp/markets/statistics-equities/misc/01.html
上場企業全銘柄の一覧は上記からダウンロードすることができます。株式データの取得については以前に書きましたので省略します。
まとめ
このような分析から何がわかるのでしょう。
ひとつには、幅広い業種のデータから似たような指標を示す会社を抽出し、たとえばトレードをするなら循環物色したり、あるいは業務戦略であれば隠れた IT 投資の需要を推測するといったことが考えられます。全業種に対して機械的にクラスタリングができれば、人間が判断してピックアップする手間が省けますね。
あるいは、今回は単純にリターンインデックスのみを指標としましたが、原理としてはどのような指標を用いることもできます。たとえば日経平均株価は 225 社の平均から算出されますが、これに近似したインデックスをたった 20 社から構築したいと思ったときに、機械学習を利用するといったことが考えられます。
いずれにせよ、勘や経験に頼った分析ほどアテにならないものはありません。人間は認知の歪みをそなえており、感情的な判断を下すものです。このあたりは行動経済学の話に通じますが、人間は必ずしも合理的な判断を下すというわけではないということです。金融データ分析において人間的な感情を排し、合理的な判断を下すために、機械的な分析によるサポートは欠かせません。