はじめに
みなさん,コロナの渦中でいかがお過ごしでしょうか?不要不急の外出がなくなり持て余した時間を普段できない勉強や検証に当てようと,今回は最近勉強を始めた Go と Rust で faiss を使ってみることにしました.なお,faiss は faiss のちょっとニッチな機能紹介 でも紹介した Facebook Resarch が提供するお気に入りの近傍探索ライブラリです.
実装
それでは早速 python, Go, Rust の順で実装していきたいと思います.
python
まずは環境構築です.本家のインストールガイドに従えば基本的に問題なくモジュールがインストールされます.なお,conda でインストールする方法も書かれていますが,個人的に conda 環境には苦い思い出があるのでソースからビルドしました.
次にソースコードです.Go, Rust でも同様ですが,後からパフォーマンス計測をしたかったので,ログは json で出力するようにしています.また,各イテレーションでメモリを解放しないと,イテレーションごとにどんどんメモリが増え続けてしまったので,del 変数 と gc.collect() を最後に入れて強制的にメモリを解放するようにしています.
import gc
import logging
import sys
from time import time
import faiss
import numpy as np
from pythonjsonlogger import jsonlogger
def elapsed(f, *args, **kwargs):
start = time()
f(*args, **kwargs)
elapsed_time = time() - start
return elapsed_time
if __name__ == '__main__':
# Prepare log.
logger = logging.getLogger()
formatter = jsonlogger.JsonFormatter('(levelname) (asctime) (pathname) (lineno) (message)')
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.setLevel(logging.INFO)
# Define basic information.
d = 512
N = 1e6
nd = 10
nbs = np.arange(N / nd, N + 1, N / nd).astype(int)
nq = 10
k = 5
# Start measuring performance.
for i in range(100):
for nb in nbs:
# Prepare data.
xb = np.random.rand(nb, 512).astype(np.float32)
xq = np.random.rand(nq, 512).astype(np.float32)
# Construct index.
index = faiss.IndexFlatL2(d)
# Evaluate performance.
elapsed_add = elapsed(index.add, xb)
elapsed_search = elapsed(index.search, xq, k)
# Log performance.
logger.info('end one iteration.', extra={
'i': i,
'nb': nb,
'elapsed_add': elapsed_add,
'elapsed_search': elapsed_search
})
# Force to free memory.
del xb
del xq
del index
gc.collect()
Go
続いて Go です.こちらも環境構築から始めます.Go については,これだ!という faiss wrapper がなかったので,最もシンプルに wrap していそうな zhyon404/faiss を使うことにしました.このレポジトリでは Docker で環境が提供されている ので,README に従い docker build して環境を作りました.
次にソースコードです.Go でもログを json 出力にするために logrus.JSONFormatter を使い,各イテレーションでのメモリ解放も実施しています.特に faiss の index は C の領域でメモリ確保しているので,なかなか解放されず,faiss_go.FaissIndexFree というメソッドを見つけるまでは苦労しました.
package main
import (
"github.com/facebookresearch/faiss/faiss_go"
log "github.com/sirupsen/logrus"
"math/rand"
"os"
"runtime"
"runtime/debug"
"time"
)
func main() {
// Prepare log.
log.SetFormatter(&log.JSONFormatter{})
log.SetOutput(os.Stdout)
// Define basic information.
d := 512
nbs := []int{1e5, 2e5, 3e5, 4e5, 5e5, 6e5, 7e5, 8e5, 9e5, 1e6}
nq := 10
k := 5
// Start measuring performance.
for i := 0; i < 100; i++ {
for _, nb := range nbs {
// Prepare data.
xb := make([]float32, d*nb)
xq := make([]float32, d*nq)
for i := 0; i < nb; i++ {
for j := 0; j < d; j++ {
xb[d*i+j] = rand.Float32()
}
}
for i := 0; i < nq; i++ {
for j := 0; j < d; j++ {
xq[d*i+j] = rand.Float32()
}
}
// Construct index.
v := new(faiss_go.Faissindexflatl2)
faiss_go.FaissIndexflatl2NewWith(&v, d)
index := (*faiss_go.Faissindex)(v)
// Evaluate performance.
add_start := time.Now()
faiss_go.FaissIndexAdd(index, nb, xb)
add_end := time.Now()
I := make([]int, k*nq)
D := make([]float32, k*nq)
search_start := time.Now()
faiss_go.FaissIndexSearch(index, nq, xq, k, D, I)
search_end := time.Now()
// Log performance.
log.WithFields(log.Fields{
"i": i,
"nb": nb,
"elapsed_add": add_end.Sub(add_start).Seconds(),
"elapsed_search": search_end.Sub(search_start).Seconds(),
}).Info("end one iteration.")
// Force to free memory.
faiss_go.FaissIndexFree(index)
runtime.GC()
debug.FreeOSMemory()
}
}
}
Rust
最後に Rust です.ここでも環境構築からです.faiss の wrapper は Docs.rs にも公開されている Enet4/faiss-rs を使うことにしました.基本的には README に従っていけばインストールできるのですが,
This will result in the dynamic library faiss_c ("libfaiss_c.so" in Linux), which needs to be installed in a place where your system will pick up. In Linux, try somewhere in the LD_LIBRARY_PATH environment variable, such as "/usr/lib", or try adding a new path to this variable.
とライブラリへのパス追加を忘れないことが重要です.また,環境によっては LIBRARY_PATH にも追加しないと動かないようです.
次にソースコードです.こちらも同様にログを json 出力するために json_logger を使っています.サンプルに従い struct を定義していますが,もっとよい方法があるんじゃないかな?と考えています.また Rust の乱数生成が遅くパフォーマンス計測がしんどかったので Rustで乱数生成するときの処理速度の違い を参考に rand_xorshift を使うようにしました.面白かったのは,python, Go とは異なり C 領域でのメモリ確保が絡んでくるにも関わらず,特にメモリ解放を意識することなく実装できたことです.
[package]
name = "rust"
version = "0.1.0"
authors = []
edition = "2018"
[dependencies]
faiss = "0.8.0"
json_logger = "0.1"
log = "0.4"
rand = "0.7"
rand_xorshift = "0.2"
rustc-serialize = "0.3"
use faiss::{Index, index_factory, MetricType};
use log::{info, LevelFilter};
use rand::{RngCore, SeedableRng};
use rand_xorshift::XorShiftRng;
use rustc_serialize::json;
use std::time::Instant;
# [derive(RustcEncodable)]
struct LogMessage<'a> {
msg: &'a str,
i: i32,
nb: i32,
elapsed_add: f32,
elapsed_search: f32
}
fn main() {
// Prepare log.
json_logger::init("faiss", LevelFilter::Info).unwrap();
// Define basic information.
let d: i32 = 512;
const N: i32 = 1_000_000;
let nd: i32 = 10;
let nbs: Vec<i32> = (N/nd..N+1).step_by((N/nd) as usize).collect();
let nq: i32 = 10;
let k: usize = 5;
let mut rng: XorShiftRng = SeedableRng::from_entropy();
// Start measuring performance.
for i in 0..100 {
for &nb in nbs.iter() {
// Prepare data.
let xb: Vec<f32> = (0..nb*d).map(|_| rng.next_u32() as f32 / u32::max_value() as f32).collect();
let xq: Vec<f32> = (0..nq*d).map(|_| rng.next_u32() as f32 / u32::max_value() as f32).collect();
// Construct index.
let mut index = index_factory(d as u32, "Flat", MetricType::L2).unwrap();
// Evaluate performance.
let start = Instant::now();
index.add(&xb).unwrap();
let elapsed_add = start.elapsed().as_micros() as f32 / 1e6;
let start = Instant::now();
index.search(&xq, k).unwrap();
let elapsed_search = start.elapsed().as_micros() as f32 / 1e6;
// Log performance.
info!("{}", json::encode(&LogMessage {
msg: "end one iteration.", i, nb, elapsed_add, elapsed_search
}).unwrap());
}
}
}
性能検証
まぁ python, GO, Rust のいずれを取っても faiss の C API を wrap しているだけなので,そこまで性能差は出ないだろうとは思いつつ,せっかく実装したのでパフォーマンス計測を実施することにしました.なお,行列演算ライブラリには OpenBLAS を用いて,環境は AWS EC2 の m5.large を用いて,AMI は Canonical, Ubuntu, 18.04 LTS, amd64 bionic image build on 2020-01-12 で計測しました.
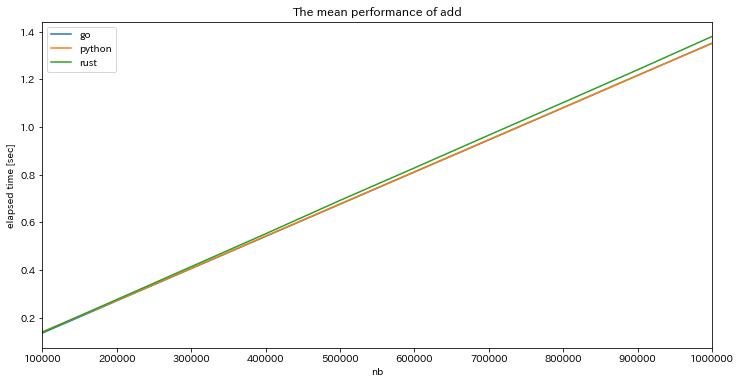
search と add について対象のデータ数を $10^5$ 〜 $10^6$ の間で動かす施行を100回ずつ行い,処理時間をデータ数ごとに平均したグラフが以下です.
add
search
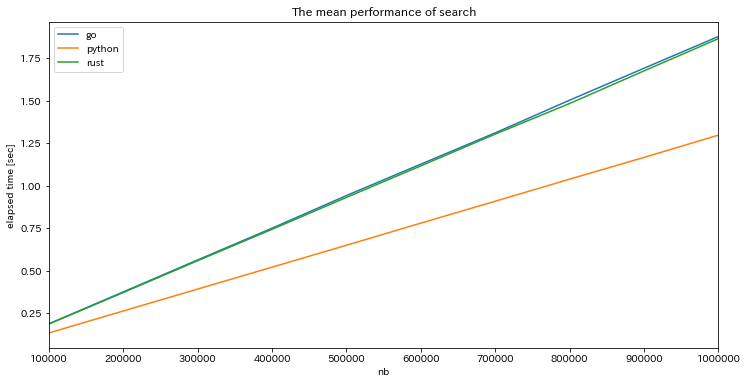
どの言語でもデータ数の増加に対して線形に処理時間が長くなっています.add では3言語間でほぼ性能差はありませんでしたが,search では python だけ性能がよいという結果になりました.同じような wrapper なのだから性能差は出ないかなと思っていただけにちょっと意外でした.さらに,この性能差がデータ数に応じてどう変わるかを見るために Go の処理時間 / python の処理時間 をプロットすると
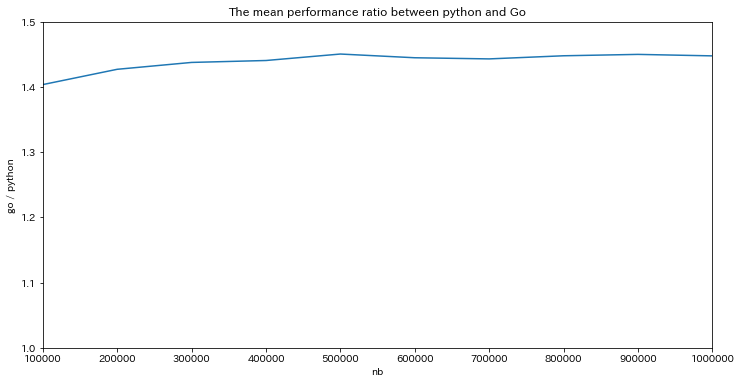
でデータ数によらず平均1.44倍程度,Go, Rust の方が python よりも遅いようです.
まとめ
Facebook Research の近傍探索ライブラリである faiss を python, Go, Rust で使ってみて性能計測を行いました.同じライブラリを異なった言語で使ってみると,各言語のクセみたいなものが見えて面白かったです.特に Rust は C 領域で確保されたメモリでさえもちゃんと解放してくれるのは心強いなぁと感じました.C でゴリゴリ実装していた時代からはだいぶ言語も進化したんだなぁ.
また,性能に関しては,Go と Rust はほぼ同程度,python だけ 1.44 倍程度高速という結果を得ました.3言語とも C で書かれた faiss の wrapper であるという点で性能は同じだろうと想定していただけに驚きました.python だけ公式でサポートしていたり,python と Go/Rust ではコンパイル方法が違っていたりするので,そこら辺が関わってくるのかなぁと考えています.今度はそこを深堀したら面白そうですね!