はじめに
この記事はCreate a natural language classifier that identifies spamにチャレンジするついでに翻訳してみたものです。
(ついでにUIが古いので更新する)
とはいうものの、全文翻訳するわけでもないので、足りないところは元記事を参照してください。
必要なもの
1. Watson Natural Language Classifier をトレーニングする
スパムとそうでないものをそれぞれラベル付けして分類していきます。
1.1 サービスを立ち上げる
IBM Cloudアカウントにログインしたら、右上から「カタログ」を選択し、左側のメニューからWatsonカテゴリーを選んで、「Natural Language Classifier」を選択します。
現れた画面の右下の「作成」をクリックしてサービスを立ち上げます。
現れた画面の左側の「サービス資格情報」をクリックします。
(サービスを作成後に現れる画面を操作すれば良いのですが、もし他のページに移動してしまっていたら、左上の3本線をクリックして「ダッシュボード」をクリックして先ほど立ち上げたサービスを選択しましょう)
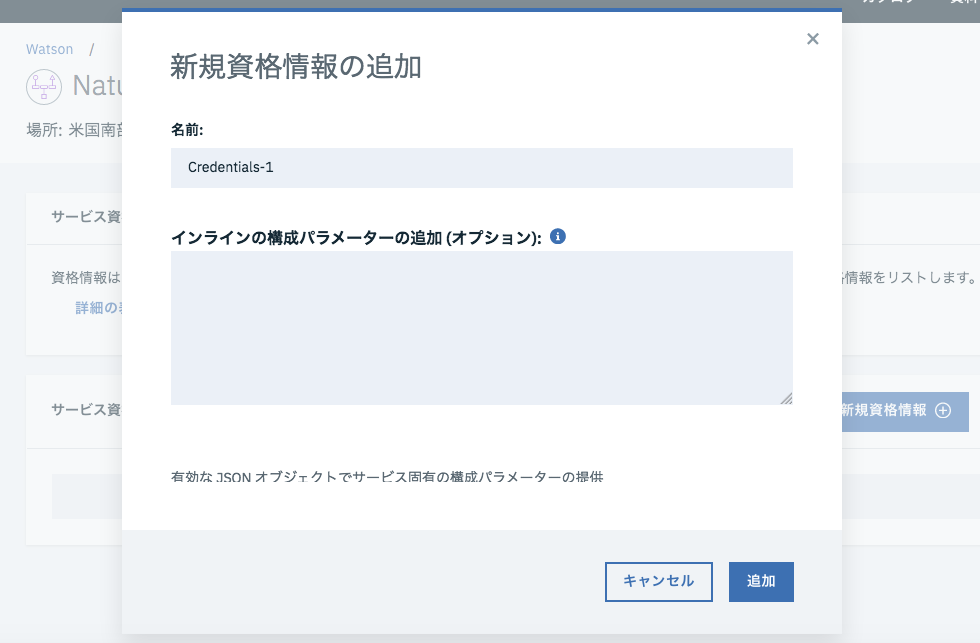
「新規資格情報」をクリックし、現れた画面の「追加」ボタンをクリックして、資格情報を取得しましょう。
ここで取得した資格情報は後ほど使うので、メモをしておくか、後ほどこの画面を開く準備をしておきましょう。
1-2 開発環境を準備する
(Macの場合)ターミナルを立ち上げ、作業ディレクトリに移動した後、Gitリポジトリをクローンします。
git clone https://github.com/cdimascio/watson-nlc-spam
内容物のうち、SpamHam-Train.csvは訓練用データで、CSV形式で作成されています。テキストとラベルが1セットになっています。
ラベルは「spam(スパム)」と「ham(非スパム)」の2種です。
テスト用データには訓練用データには入っていないオリジナルのテキストが収録されており、これを使って分類の正確さを確認します。訓練用データとテスト用データは重複させないというのは正確性を確認するのに重要なこととなってきます。
1-3 訓練を開始する。
それではWatson Natural Language Classifierを使って分類を行いましょう。
下のコマンドを実行して訓練を開始します。{username}と{password}を先ほど得た資格情報を元に書き換える必要があります。また、{path_to_file}もご自身の環境に合わせて書き換えましょう。
curl -i -u "{username}":"{password}" -F training_data=@{path_to_file}/SpamHam-Train.csv -F training_metadata="{\"language\":\"en\",\"name\":\"TutorialClassifier\"}" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers"
コマンドが通ると、例として以下のように帰ってきます。
{
"name": "TutorialClassifier",
"language": "en",
"status": "Training",
"url": "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/10D41B-nlc-1",
"classifier_id": "10D41B-nlc-1",
"created": "2015-05-28T18:01:57.393Z",
"status_description": "The classifier instance is in its training phase, not yet ready to accept classify requests"
}
1-4 訓練状況の確認
訓練の完了状況を確認したいときは上で得た情報に書き換えて下のコマンドを実行します。
curl -u "{username}":"{password}" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/{classifier_id}"
訓練の開始状況はブラウザ上のIBM CloudのWatson Natural Language Classifierの「管理」タブにあるtoolkitからも確認できます。

1-5 訓練結果の確認
分類子がうまくできたかを確認します。
以下のコマンドを投げてみましょう。
(username、password、url、classifier_idをご自身のものに書き換えます)
curl -X POST -u <username>:<password> -H "Content-Type:application/json" -d "{\"text\":\"I love you mom\"}" <uri>/v1/classifiers/<classifier_id>/classify
すると以下のような確信度を伴った結果を得られます。
上のI love you mom(ママ大好き)はham(非spam)に分類されたことがわかります。
"class_name" : "ham",
"confidence" : 0.9961904016607206
"class_name" : "spam",
"confidence" : 0.0038095983392794517
1-6 訓練結果の正確性を確認する。
最初にクローンしたリポジトリから、spam.pyをエディタで開き、「YOUR_CLASSIFIER_ID」「YOUR_CLASSIFIER_USERNAME」「YOUR_CLASSIFIER_PASSWORD」(記事作成時は14行目と16行目)を自らの情報に書き換えます。
32行目
accuracy = 1.0 * len(filter(lambda x: x[0]['top_class'] == x[1], predictionsAndLabels)) / len(test)
-> accuracy = 1.0 * len(list(filter(lambda x: x[0]['top_class'] == x[1], predictionsAndLabels))) / len(test)
33行目
print "accuracy: %s" % accuracy
-> print("accuracy: %s" % accuracy)
元のファイルはPython2なので、Python3を使う場合は以下の箇所を書き換えます。
時間はかかりましたが、以下の結果が得られました。
訓練はうまくいったようです!
accuracy: 0.9948096885813149
おわりに
こんな感じで、Watson Natural Language Classifierを使うことで、素早く訓練・テストを行い、データを分析するための分類を行うことができます。
ぜひ挑戦してみてください。
また、上でも少し紹介しましたが、分類子作成にはGUIも使えるので、ぜひそちらにも挑戦して見てください。
