Public Previewが開始!Read API v3.2 で「日本語の手書きテキスト」を読み取る
2022年2月14日に、Azure Cognitive Services の Vision API(画像認識)で提供されているOCR機能(Read API v3.2)に、「日本語の手書きテキスト」 を認識する機能が、Public Preview版として追加されました。
この記事では、「日本語の手書きテキスト」機能の使い方と、実際に試した認識精度をご紹介します。
【マイクロソフト社公式情報 - Public Preview の開始】
- Public preview: OCR supports 164 languages in the Cognitive Services Computer Vision | Published date: February 14, 2022
-
What's new in Computer Vision | February 2022 | OCR (Read) API Public Preview supports 164 languages
- Computer Vision のOCR (Read) APIは、最新のプレビューで対応言語を164言語に拡大。
- 手書きテキストの OCR サポートが、英語、中国語簡体字、フランス語、ドイツ語、イタリア語、 ポルトガル語、スペイン語に加え、日本語、韓国語に拡大。
- 手書きの日付、金額、名前などを抽出する機能を強化。
気になる認識精度は?
まずはこちらをご覧ください。

お分かり頂けるだろうか…
上段の画像データは、あの有名なセリフを日本語で手書きしたもの。
下段左が旧Read API v3.2 で読み取った結果の抜粋、せっかくのカッコイイセリフが台無しです。
そして右が新Read API v3.2 Public Preview で読み取った結果の抜粋。バッチリですね。
驚くべき事に、わざと略字で書いた「時間」の「間」の文字も、正しく読み取っています。これは想定以上。
もともと手書き文字のサポートは英語のみだったので、[旧] Read API v3.2 のほうは「精度が悪い」というよりも、「手書き文字の認識は想定されていない」と言うべきでしょうか。
これまで、ある程度「綺麗な」手書き文字は日本語でも何となく(無理矢理に)認識されていましたが、それと比べると精度が爆上がりしている印象です。
Read APIの使い方
それでは、この新しい機能をさっそく試してみましょう。Read API v3.2 のAPI仕様書は次の通り。
- Cognitive Servies API Reference - Computer Vision API (v3.2) - Read API
- Cognitive Servies API Reference - Computer Vision API (v3.2) - Get Read Result API
Read API と Get Read Result API の呼び出し方法を図解するとこんな感じ。
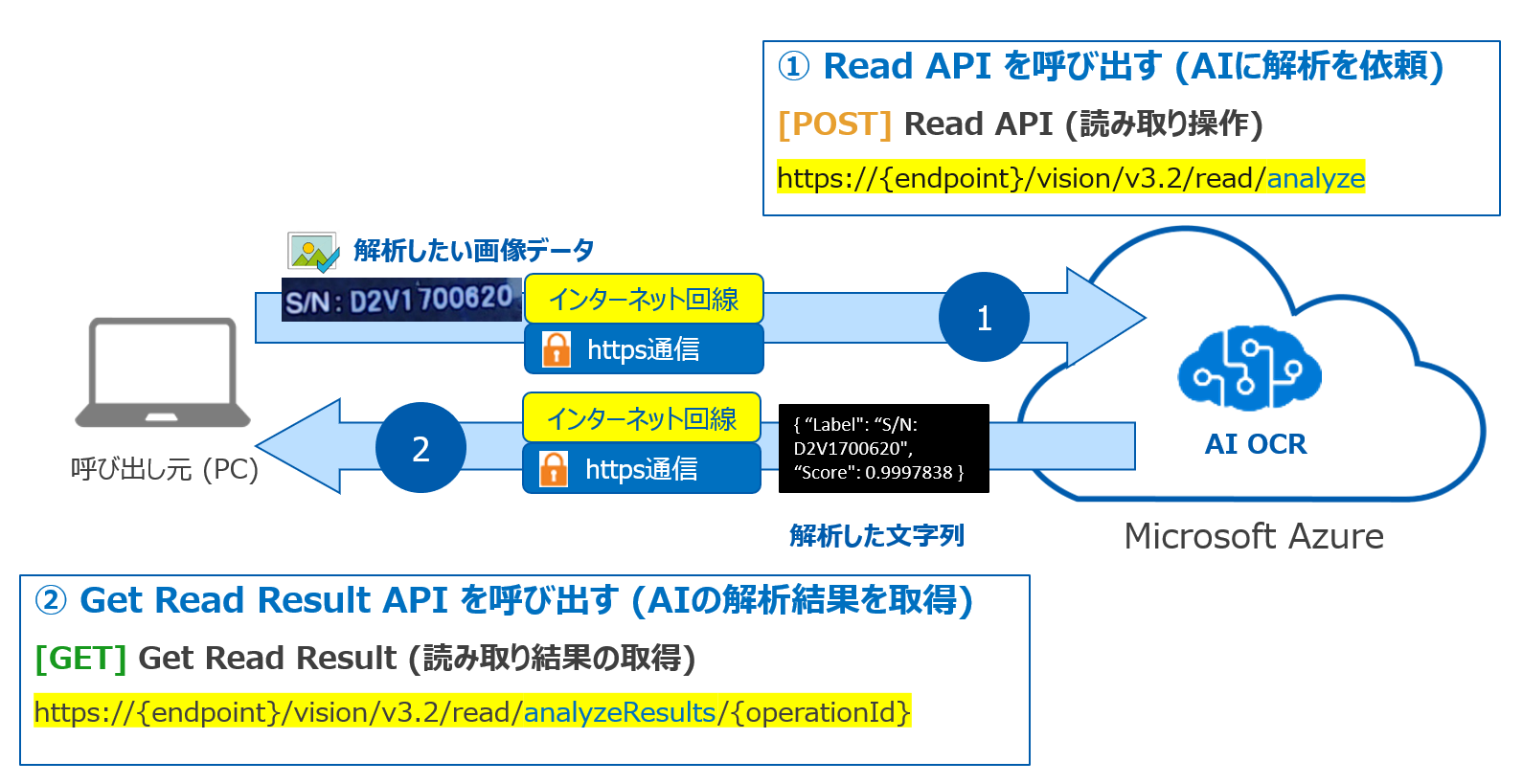

そして、今回Public Previewで追加された 「日本語の手書きテキスト」 の認識を試す際に必要な情報は次の通り。
-
Language support for Computer Vision
- handwritten text (手書きテキスト) の Japanese (preview) → Language code は "ja"
-
Specify the OCR model
- Read APIを呼び出す時に、"model-version"のパラメータで"2022-01-30-preview"を指定する
ポイントとして、Read API(/vision/v3.2/read/analyze)を呼び出す際に、 「model-version=2022-01-30-preview」 をパラメータに追加すれば良いだけ。
こんな感じ。
https://{endpoint}/vision/v3.2/read/analyze?model-version=2022-01-30-preview
これで Get Read Result のJSON応答に"appearance"フィールドが出現し、"style" が "name": "handwriting" になっているので、手書きテキストで認識している事が分かります。
{
"status": "succeeded",
"createdDateTime": "2022-02-24T02:02:19Z",
"lastUpdatedDateTime": "2022-02-24T02:02:20Z",
"analyzeResult": {
"version": "3.2.0",
"modelVersion": "2022-01-30-preview",
"readResults": [
{
"page": 1,
"angle": -0.8383,
"width": 4032,
"height": 3024,
"unit": "pixel",
"lines": [
{
"boundingBox": [
660,
1210,
2644,
1191,
2646,
1471,
665,
1510
],
"text": "3分間待ってやる。",
"appearance": {
"style": {
"name": "handwriting",
"confidence": 1
}
},
"words": [
{
...(略)
注意点(調査中)
最初、Read API 呼び出し時に、model-version 以外に、"language=ja" の指定も必要かと思ったが、これだと上手く機能しない。
逆に、上記のように "language=ja" を指定しないと上手く行く(指定しないと自動認識で日本語になる模様)
https://{endpoint}/vision/v3.2/read/analyze?language=ja&model-version=2022-01-30-preview
こうすると、JSONの応答が "name": "handwriting" にならずに、"name": "other" になってしまう。
そもそも、language=ja は必要なパラメータだと思っていたので、これが正しい挙動なのかどうか疑問。
(私の環境だけかも。調査中)
まとめ
今回はRead API v3.2 で「日本語の手書きテキスト」を読み取る仕組みを説明しました。
次回は、このAI-OCRを簡単に(=コードを書かずに)試してみる方法をご紹介します。