Redshiftへ取り込みたいデータがWeb APIでしか提供されていない場合にLambdaでAPIを叩いて取得したデータをRedshiftに取り込むということになると思います。今回はそのような実装したので紹介します。細い説明は省きます。
1. Redshiftのデータベースとテーブルを作成する
2. LambdaでRedshift Data APIを使ってS3にあるJSONデータをRedshiftに取り込む
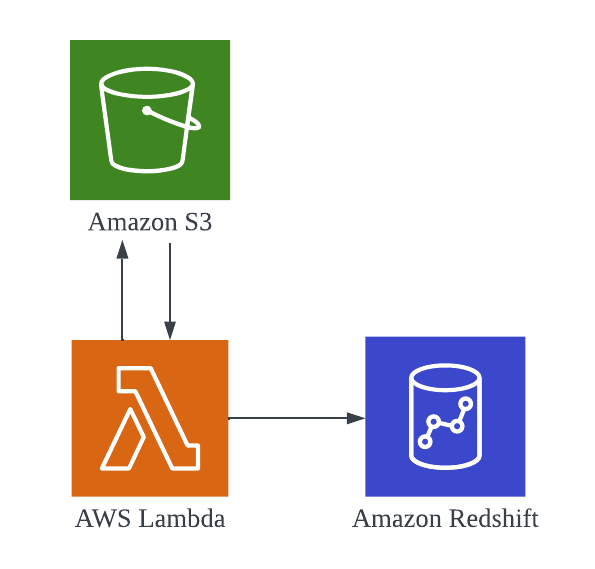
今回のアーキテクチャは以下の通りです
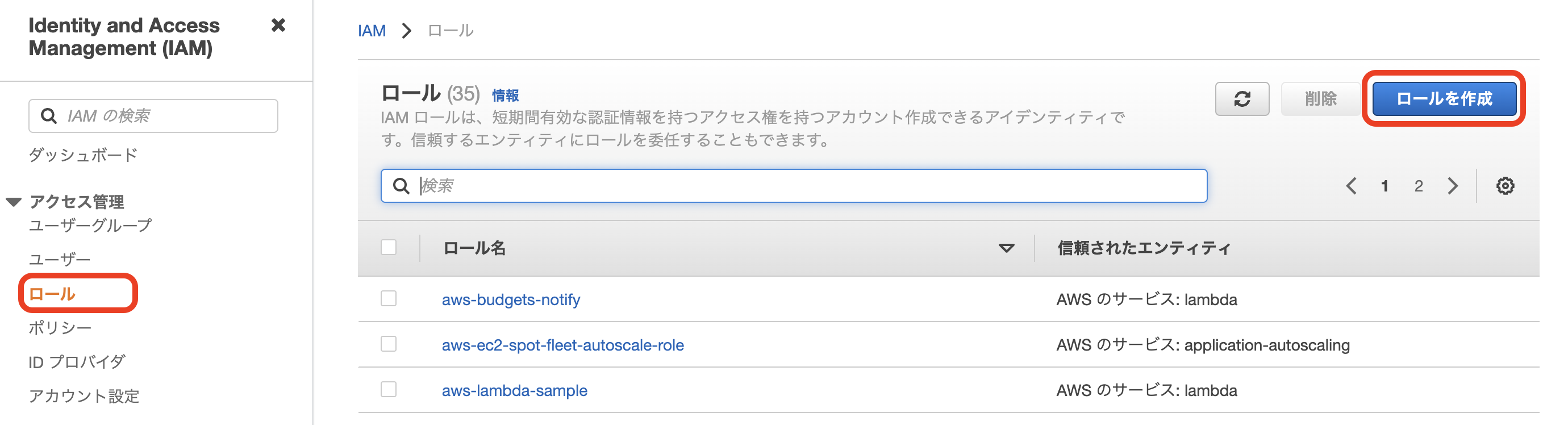
IAM周りのセットアップ
1. LambdaのIAMロールに「AmazonRedshiftFullAccess」ポリシーをアタッチする
2. Redshift用のIAMロールを作成 & 「AmazonS3ReadOnlyAccess」をポリシーをアタッチする
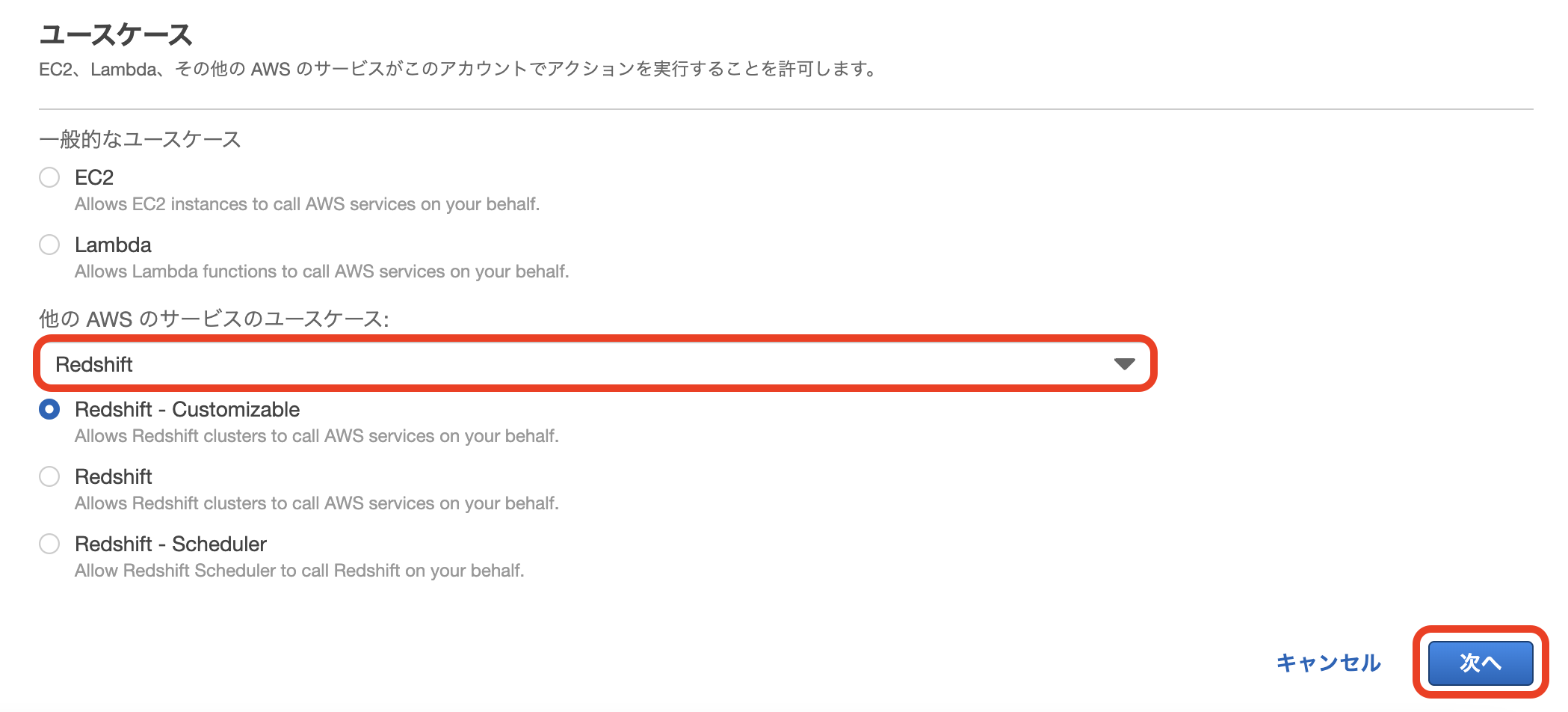
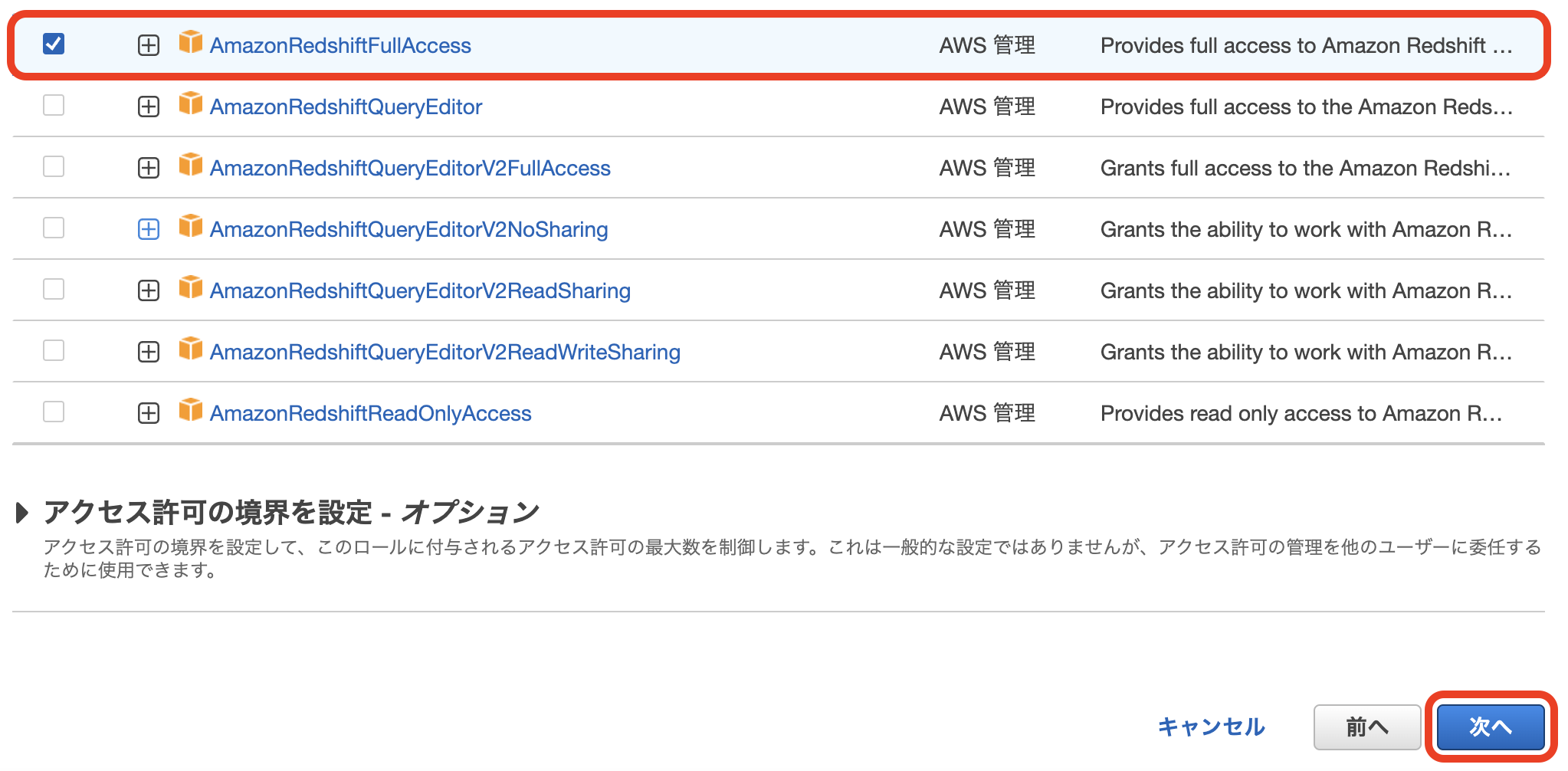
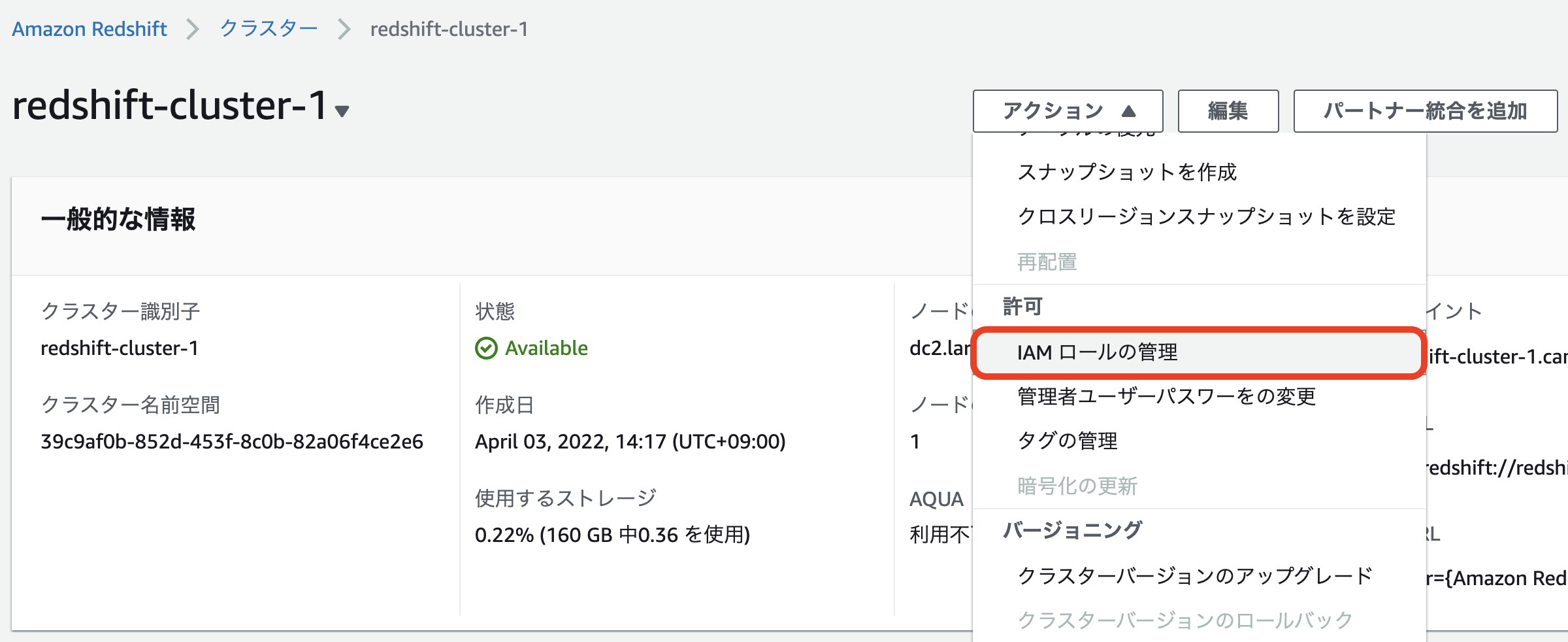
3. 作成したIAMロールを割り当てる
コードの実装
Redshift Data APIを使ってRedshiftのデータに簡単にアクセスできます。COPYコマンドを実行し、S3のJSONファイルに記述されているデータをRedshiftに取り込みます。転送元のファイルの書き方をコツがあって以下の記事を参考にしました ↓↓↓
import json
import boto3
import time
CLUSTER_NAME='redshift-cluster-1'
DATABASE_NAME='json_database'
DB_USER='awsuser'
sql="COPY public.users FROM 's3://s3-backet-redshift/test_2022-04-04-16-24-56.json' " + \
"iam_role 'arn:aws:iam::009554248005:role/RedshiftAccessS3' " + \
"FORMAT AS JSON 'auto' " + \
"REGION AS 'ap-northeast-1';"
client = boto3.client('redshift-data')
def lambda_handler(event, context):
result = client.execute_statement(
ClusterIdentifier=CLUSTER_NAME,
Database=DATABASE_NAME,
DbUser=DB_USER,
Sql=sql,
)
# 実行IDを取得
id = result['Id']
# クエリが終わるのを待つ & フラグ管理
statement = ''
status = ''
# ステータスが変わるまで無限ループ
while status != 'FINISHED' and status != 'FAILED' and status != 'ABORTED':
statement = client.describe_statement(Id=id)
status = statement['Status']
print("Status:", status)
time.sleep(1)
# 成功したら Status: FINISHED と出力される
print("Status:", status)
参考文献