はじめに
Pysparkを勉強するにあたって、Dataframeの操作がPandasとどう違うのかを一覧できるものがあるといいなと思い作りました。
UdemyのPySpark Essentials for Data Scientists (Big Data + Python)という講座のDataframe Essentialsというセクションで学んだことのアウトプットとして、Pandasとの操作の比較をTitanicのデータセットを使用して行います。
こちらの講座はセール時であれば1900円ほどで購入できたので、もしご興味があれば、、(本だとあまり良い教材が見つからず、Udemyにしました)
※全ての記法を網羅しているわけではありませんのでご了承ください。また、厳密にはPandasのみに限定される記法ではない箇所もあるかと思いますが、Pysparkとの比較の分かりやすさのためこのように表記しています。
Dataframeの操作
前準備
必要なライブラリなどをインポートします(一部は後程)。
import findspark
findspark.init()
import pandas as pd
import pyspark # only run after findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Practice").getOrCreate()
データ読み込み
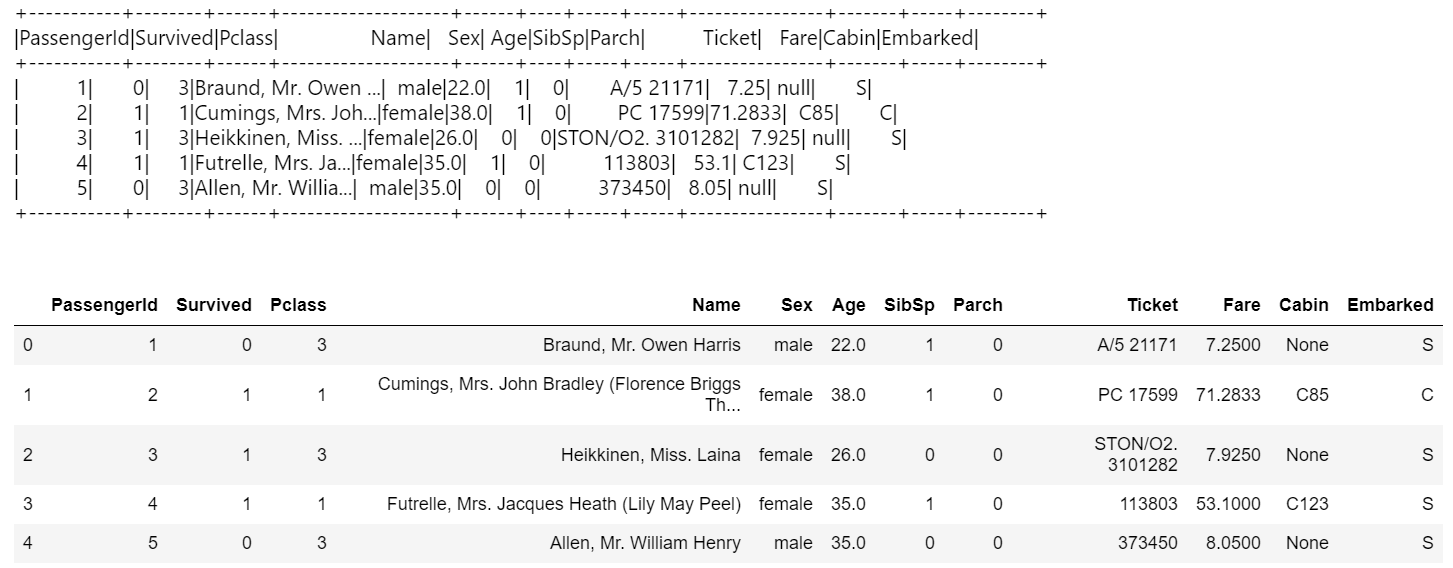
https://3pysci.com/kaggle-titanic-2/ からTitanicのTrain.csvをダウンロードし、Notebookと同じフォルダに置いたうえで先頭5行表示
## pyspark
pys_df = spark.read.csv('train.csv',inferSchema=True,header=True)
pys_df.limit(5).show()
# pandasっぽく表示したい場合
pys_df.limit(5).toPandas()
## pandas
pd_df = pd.read_csv('train.csv')
pd_df.head()

カラムの型確認および変換
Age列の型をIntに変換
## pyspark
print(pys_df.printSchema())
from pyspark.sql.types import IntegerType
pys_df = pys_df.withColumn('Age', pys_df['Age'].cast(IntegerType()))
pys_df.printSchema()

## pandas
print(pd_df.dtypes)
pd_df = pd_df.dropna(subset=["Age"]) #欠損値が含まれるとエラーになるので今回は除去
pd_df = pd_df.astype({"Age": "int64"})
pd_df.dtypes

統計量の要約の表示
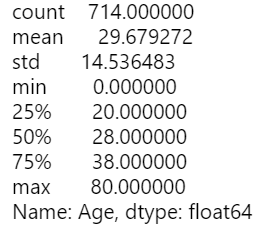
指定のカラムに対して統計量を表示
## pyspark
print(pys_df.describe(['Age']).show())
# または
print(pys_df.select('Age').summary('count', 'mean', 'stddev', 'min', 'max').show())

## pandas
print(pd_df.describe()['Age'])
並び替えて表示
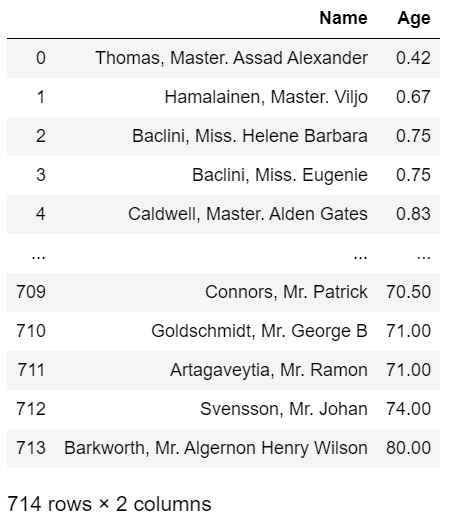
各カラムの順序に沿って並び替え
## pyspark
from pyspark.sql.functions import *
pys_df = pys_df.dropna(subset=["Age"]) #pandasの方と同じく欠損値除去
pys_df.select(['Name', 'Age']).orderBy('Age').toPandas()
# Spark SQLの場合
pys_df.createOrReplaceTempView("tempview")
spark.sql("SELECT Name, Age FROM tempview ORDER BY Age ASC").toPandas()
## pandas
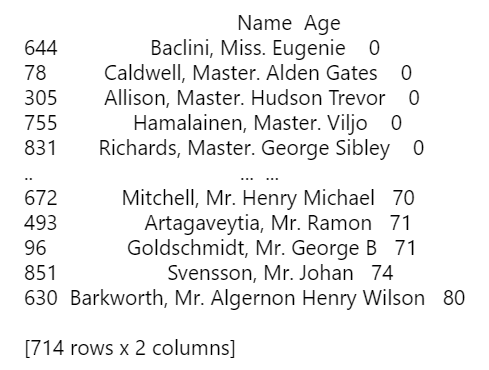
print(pd_df[['Name', 'Age']].sort_values(by='Age', ascending=True))
条件を指定して抽出
Age列が30以上の行のみを抽出
## pyspark
pys_df.filter('Age >= 30').toPandas()
# Spark SQLの場合
pys_df.createOrReplaceTempView("tempview")
spark.sql("SELECT * FROM tempview WHERE Age >= 30").toPandas()
## pandas
pd_df_edited = pd_df.query('Age >= 30')
pd_df_edited
Nameが"Miss"を含む行のみ抽出
## pyspark
pys_df.filter(pys_df.Name.contains('Miss')).toPandas()
# Spark SQLの場合
pys_df.createOrReplaceTempView("tempview")
spark.sql("SELECT * FROM tempview WHERE Name LIKE '%Miss%'").toPandas()
## pandas
pd_df[pd_df['Name'].str.contains('Miss')]
Sexがmaleの行数を表示
## pyspark
pys_df.filter(col('Sex') == ('male')).count()
# SQLTransformerの場合
from pyspark.ml.feature import SQLTransformer
pys_df.createOrReplaceTempView("tempview")
sqlTrans = SQLTransformer(
statement="SELECT count(*) FROM __THIS__ WHERE Sex = 'male'")
sqlTrans.transform(pys_df).show()

## pandas
pd_df_count = pd_df['Sex'] == 'male'
pd_df_count.sum()
DataframeのTransformation
Sexごとに行数表示
## pyspark
print(pys_df.groupBy("Sex").count().sort("count", ascending=True).toPandas())
# SQLTransformerの場合
sqlTrans = SQLTransformer(
statement="SELECT Sex, count(*) as Count FROM __THIS__ GROUP BY Sex ORDER BY Count ASC")
sqlTrans.transform(pys_df).toPandas()

## pandas
pd_df.groupby('Sex').size()

Embarkedカラムが’C’とそれ以外のもので区別してGroup by
## pyspark
from pyspark.sql.functions import when
clean = pys_df.withColumn('Embarked', when(pys_df.Embarked == 'C', 'C').otherwise('Other'))
counts = clean.groupBy("Embarked").count()
counts.orderBy(desc("count")).toPandas()

## pandas
pd_df_hoge = pd_df.copy()
pd_df_hoge['Embarked_edited'] = pd_df_hoge['Embarked'].apply(lambda x: 'C' if x == 'C' else 'Other')
pd_df_hoge.groupby('Embarked_edited').size()

カラムの名前変更
## pyspark
renamed_pys_df = pys_df.withColumnRenamed('PassengerId', 'ID')
renamed_pys_df.limit(5).toPandas()

## pandas
renamed_pd_df = pd_df.rename(columns={'PassengerId': 'ID'})
renamed_pd_df.head()

カラムの結合
## pyspark
from pyspark.sql.functions import *
pys_df.select(pys_df.Sex, pys_df.Age, concat_ws(' _', pys_df.Sex, pys_df.Age).alias('concatenated')).limit(5).toPandas()
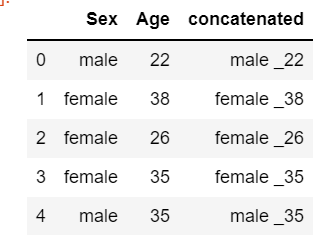
## pandas
pd_df_hoge['concatenated'] = pd_df_hoge['Sex'].str.cat(pd_df['Age'].astype(str), sep='_')
pd_df_hoge[['Sex', 'Age', 'concatenated']].head()
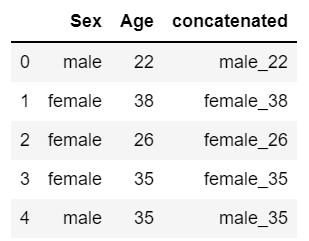
共通キーを使った複数Dataframeの結合
Dataframeの作成
## Pyspark
values_1 = [('Phil',1,'A'),('Alan',2,'A'),('Doug',3,'B'),('Stu',4,'C'),('Chow',5,'D')]
name_pys = spark.createDataFrame(values_1,['name','id','class'])
values_2 = [(1,'baseball'),(2,'tennis'),(3, 'tennis'),(5,'basketball')]
club_pys = spark.createDataFrame(values_2,['student_id','club'])
print(name_pys.toPandas())
print(club_pys.toPandas())

## pandas
name_pd = pd.DataFrame({
'name': ['Phil', 'Alan', 'Doug', 'Stu', 'Chow'],
'id': [1, 2, 3, 4, 5],
'class': ['A', 'A', 'B', 'C', 'D']
})
club_pd = pd.DataFrame({
'student_id': [1, 2, 3, 5],
'club': ['baseball', 'tennis', 'tennis', 'basketball' ]
})
print(name_pd.head())
print(club_pd.head())

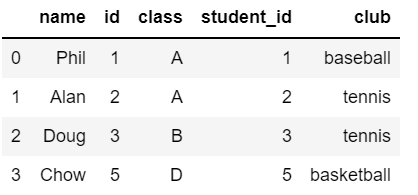
内部結合(inner join)
## pyspark
inner_join = name_pys.join(club_pys, name_pys.id == club_pys.student_id, 'inner').sort(asc('id'))
inner_join.toPandas()
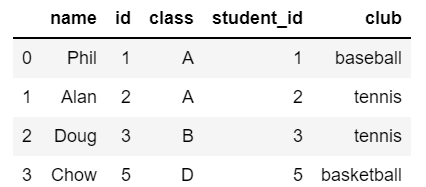
## pandas
pd.merge(name_pd, club_pd, left_on='id', right_on='student_id', how="inner")
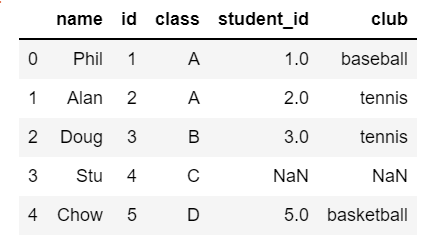
左外部結合(left join)
## pyspark
left_join = name_pys.join(club_pys, name_pys.id == club_pys.student_id, 'left').sort(asc('id'))
left_join.toPandas()
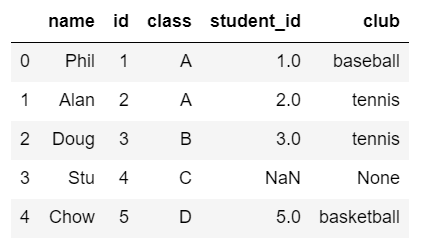
## pandas
pd.merge(name_pd, club_pd, left_on='id', right_on='student_id', how="left")
右外部結合(right join)
## pyspark
right_join = name_pys.join(club_pys, name_pys.id == club_pys.student_id, 'right').sort(asc('student_id'))
right_join.toPandas()
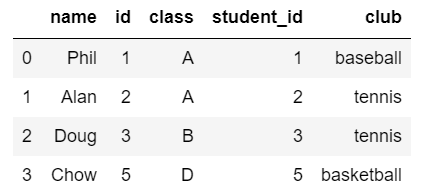
## pandas
pd.merge(name_pd, club_pd, left_on='id', right_on='student_id', how="right")
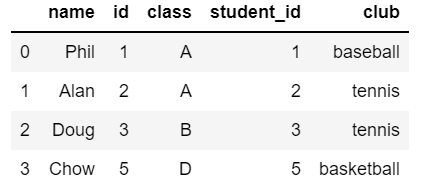
完全外部結合(Full outer join)
## pyspark
full_outer_join = name_pys.join(club_pys, name_pys.id == club_pys.student_id, 'full').sort(asc('id'))
full_outer_join.toPandas()
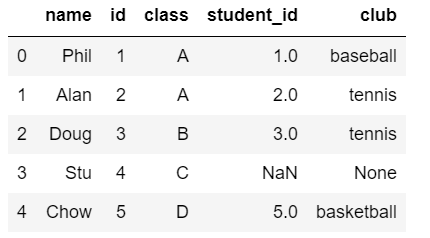
## pandas
pd.merge(name_pd, club_pd, left_on='id', right_on='student_id', how="outer")
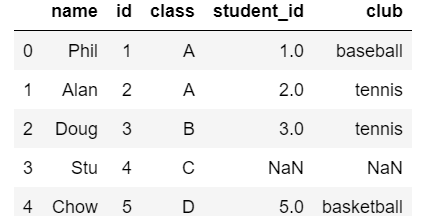
欠損値のハンドリング
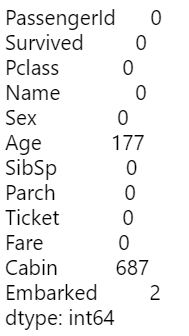
欠損値の確認
## psypark
from pyspark.sql.functions import *
def null_value_calc(df):
null_columns_counts = []
numRows = df.count()
for k in df.columns:
nullRows = df.where(col(k).isNull()).count()
if(nullRows > 0):
temp = k,nullRows,(nullRows/numRows)*100
null_columns_counts.append(temp)
return(null_columns_counts)
# 以前の操作でAgeの欠損値を含む行は消していたので、改めて読み込む
pys_df = spark.read.csv('train.csv',inferSchema=True,header=True)
null_columns_calc_list = null_value_calc(pys_df)
spark.createDataFrame(null_columns_calc_list, ['Column_Name', 'Null_Values_Count','Null_Value_Percent']).toPandas()

## pandas
# 以前の操作でAgeの欠損値を含む行は消していたので、改めて読み込む
pd_df = pd.read_csv('train.csv')
pd_df.isnull().sum()
いずれかの列が欠損している行を削除
## pyspark
dropped_pys = pys_df.na.drop()
dropped_pys.toPandas()
## pandas
dropped_pd = pd_df.dropna(how='any').dropna(how='any', axis=1)
dropped_pd
Ageカラムが欠損した行を削除
## pysparkとPandas共通
drop_Age = pys_df.na.drop(subset=["Age"])
drop_Age.toPandas()
Ageカラムが欠損した部分をAgeの平均値で補完
## pyspark
def fill_with_mean(df, include=set()):
stats = df.agg(*(avg(c).alias(c) for c in df.columns if c in include))
return df.na.fill(stats.first().asDict())
updated_pys_df = fill_with_mean(pys_df, ["Age"])
updated_pys_df.toPandas()
## pandas
updated_pd_df = pd_df.copy()
updated_pd_df['Age'] = pd_df['Age'].fillna(pd_df['Age'].mean())
updated_pd_df
さいごに
一部自分で関数を定義する必要がある箇所もありましたが、基本的には普段Pandasでやっているような操作は問題なくPysparkでもできますね。