はじめに
SpotifyAPIでは、楽曲ごとの解析した音楽的なパラメータを返却してくれます。
それらのデータを含む楽曲リストを取得し、2020年に聴いた曲の傾向を分析してみましょう。
(年明けてしまった...)
動作環境
- Google Colaboratory
- Python 3.6
- Exploratory Public 6.3.3
事前に準備するもの
- spotifyプレイリストのCSV - Part1記事を参照ください
- Exploratory のインストール - 無料でインストール
できます
やること
- EDA - データ理解
- データ前処理① - ラベル値として新規カラムを追加
- データ前処理② - 型変換(時間項目 m秒 → h:M:Sに)
EDAとは
探索的データ分析。Explanatory Data Analysisの略です。
EDAはデータ分析の一番最初のフェーズで、まずはデータに触れてみて、データを視覚化し、パターンを探したり、特徴量やターゲットの関係性/相関性の有無をくみとるのが目的です。
なんで必要なの?
分析をはじめる前に、まずは ”どのようなデータセットを扱っているのか” を、理解することが重要です。
より高度な機械学習のモデルの構築をしたり、難解な問題を解決する際には、特徴量エンジニアリングを必要することが多々あり、その際に深いデータの知識と理解が求められます。
また、この段階で前処理が必要なカラムを把握しておきます。
どうやってやるか
次ステップのことを考えるとpandasを使用してもよいですが、python初学者だったりするとコードを書くつまづく可能性もあります。
ここではまずは"ビジュアルから"イメージを掴んでもらえるとよいかなーと思い、ノーコードでできる方法を紹介します。
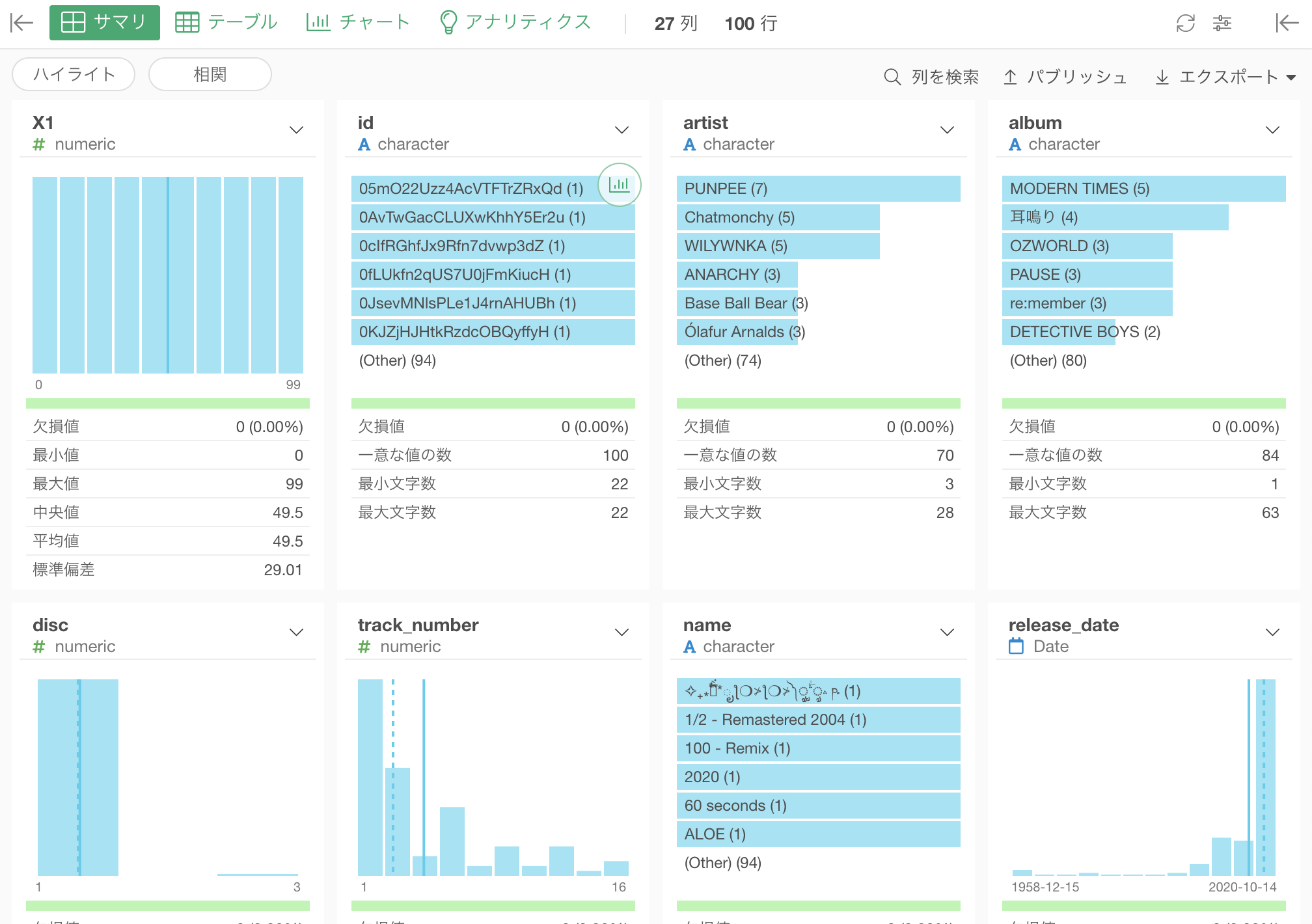
データを取り込んでみる
使用するツールは、Exploratoryです。
CSVデータを取り込むだけで、以下のように各項目の欠損値の有無など、各列の要約統計量が表示されます。
便利ですね!
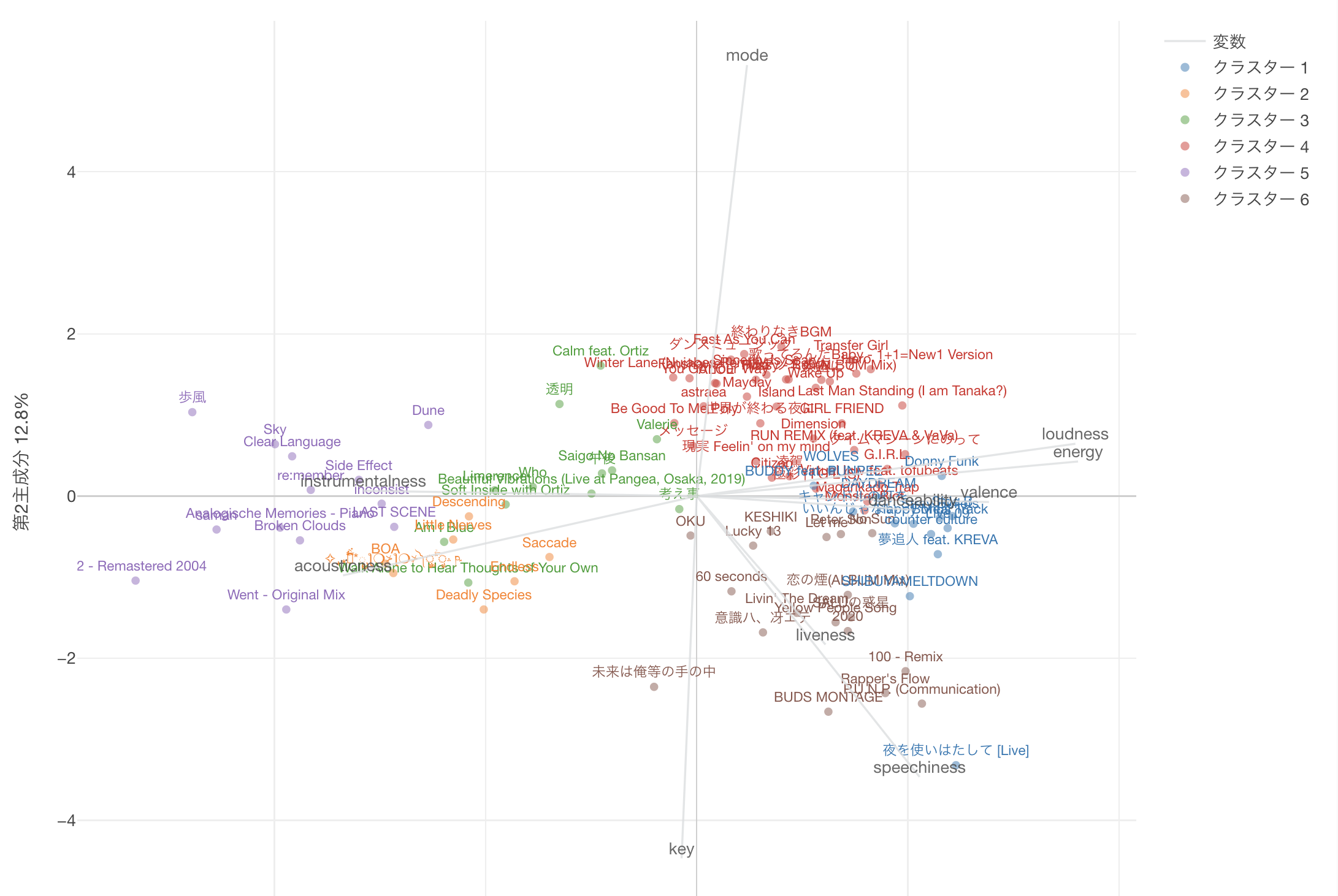
カラム値の相関もGUI操作で可視化できます。
loudnessとenergyの正の相関がみてとれますね。

前処理とは
前処理が必要な理由は以下のようなことが挙げられます。
- 機械学習のモデルは文字列データではなく数値データで渡す必要があるため
- 上記同様、欠損値(null)があるデータも変換しないと機械学習のモデルに渡せないため
- 精度を向上させるため、外れ値のレコードを除く などなど
例えばどんなもの?
-
機械学習のモデルは文字列データではなく数値データで渡す
-
例. 文字列データ(曜日:Mon,Tue,Wed...)ではなく数値データ(0,1,2...)に
-
精度を向上させるため、外れ値のレコードを除く
-
例. シークレットトラックで無音で秒数が長いtrackの有無を確認
-
例. tempo(BPM)が倍になっている曲がないかをチェック
とはいえ
提供APIで取得できるデータは、欠損値はありませんし、機械が取り込みやすい形になっています。
ですので、前処理のお勉強教材としては、あまり適していません。
またtempo(BPM)や、key(調)、time_signitune(拍子)については、一曲で1意に決まるものとは限らず、
そもそも分析対象の項目とすべきかなどの考慮が必要になります。
このあたりは、EDA時に確認するポイントになります。
前処理の具体例については、別記事にまとめたいとおもいます。
この記事では、前処理の代わりに、EDAの際に人間が読みやすい値を別カラムに追加する処理を置いておきます。
# 調をラベル値として別カラムに :長調(major)は1, 単調(minor)は0
tracks_with_features_df.loc[tracks_with_features_df['mode'] == 1, 'a_mode'] = 'major'
tracks_with_features_df.loc[tracks_with_features_df['mode'] == 0, 'a_mode'] = 'minor'
# キーをラベル値として別カラムに : Cは1, C#は2 ...
tracks_with_features_df.loc[tracks_with_features_df['key'] == 0, 'a_key'] = 'C'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 1, 'a_key'] = 'C#'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 2, 'a_key'] = 'D'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 3, 'a_key'] = 'D#'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 4, 'a_key'] = 'E'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 5, 'a_key'] = 'F'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 6, 'a_key'] = 'F#'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 7, 'a_key'] = 'G'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 8, 'a_key'] = 'G#'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 9, 'a_key'] = 'A'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 10, 'a_key'] = 'A#'
tracks_with_features_df.loc[tracks_with_features_df['key'] == 11, 'a_key'] = 'B'
# 時間単位の変換:ミリ秒 → 秒
tracks_with_features_df['a_second'] = tracks_with_features_df['duration_ms'] / 1000
まとめ
SpotifyAPIを使用して、楽曲のオーディオデータのデータ可視化と前処理を示しました。
次回こそ、オーディオデータから、楽曲の類似度を可視化していきます。それでは。