はじめに
この記事は、GitHub 上で公開されている Azure Synapse Link for Azure Cosmos DB API for MongoDB のサンプルの解説記事です。
本家の記載は英語となっています。こちら のリポジトリにて日本語訳を行っていますので、どちらか好きな方にアクセスを行ってください。
- 本家 (English): Azure-Samples/Synapse
- 日本語訳 (非公式): ymasaoka/Synapse
なお、Azure Synapse Link for Azure Cosmos DB API for MongoDB のサンプルは、/Notebooks/PySpark/Synapse Link for Cosmos DB samples/MongoDB に用意されています。詳細を確認したい方は、こちらも合わせてご確認ください。
環境構築
このサンプルの実行には、以下の環境が必要です。
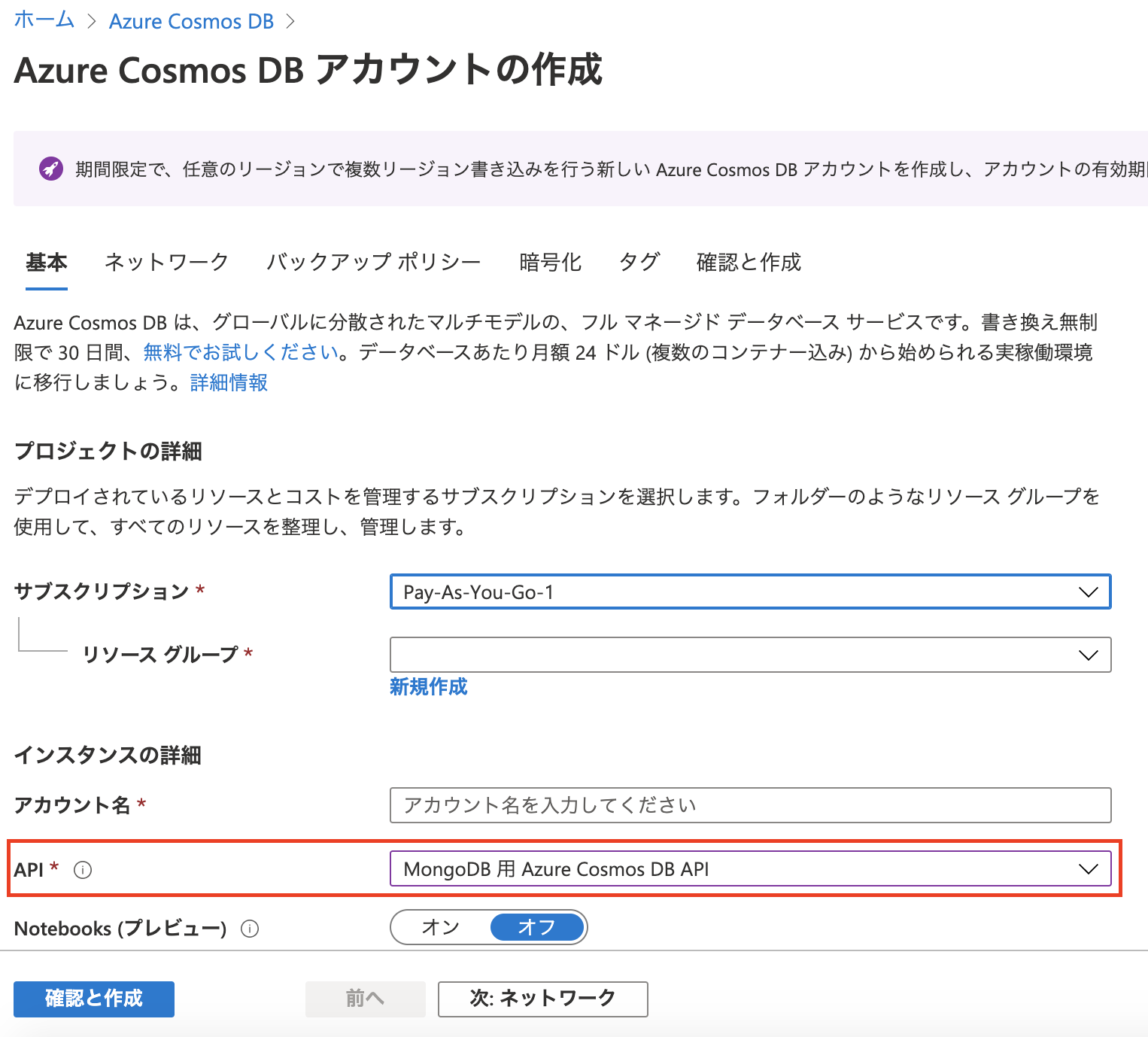
- Azure Cosmos DB アカウント (API for MongoDB)
- Spark プールがある Azure Synapse ワークスペース
環境の作成方法については、以下の記事を参考にしてみてください。
Cosmos DB の要求ユニット (RU/s) は 400 RU/s で十分です。
ただし、Azure Cosmos DB アカウントの作成時に選択する API は、必ず MongoDB 用 Azure Cosmos DB API を選択してください。
Azure Cosmos DB の API for MongoDB と Synapse Link をはじめる
今回の流れ
今回は、以下の流れで Azure Synapse Link の動作を確認していきます。
- 従来の MongoDB クライアントを使用してデータセットを Azure Cosmos DB トランザクションストアに挿入
- トランザクションストアから ETL された分析ストア内のデータに対して集計クエリを実行
- 別のデータセットを Azure Cosmos DB トランザクションストアに挿入
- 分析ストア内にある両方のデータセットを統合し、集計クエリを実行
事前準備
Cosmos DB コレクションの作成
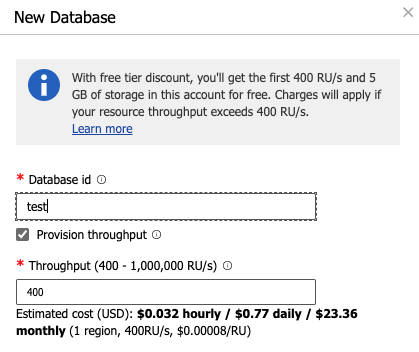
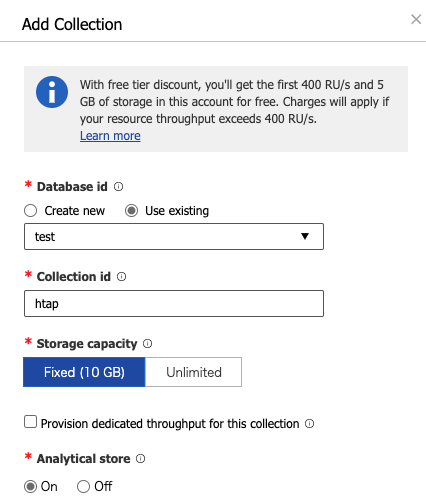
Azure Cosmos DB 側で、データベースとコレクションを作成しましょう。
1 点注意は、MongoDB の場合、パーティションキーは シャードキー1というものに置き換えられます。
また、2020/09/25 時点で、本家のサンプル記載ではシャードキーを設定するとありますが、シャードキーは設定しないでください。
-
データベース:
test -
コレクション:
htap-
Storage capacity:
Fixed (10 GB) -
分析ストア:
On
-
Storage capacity:
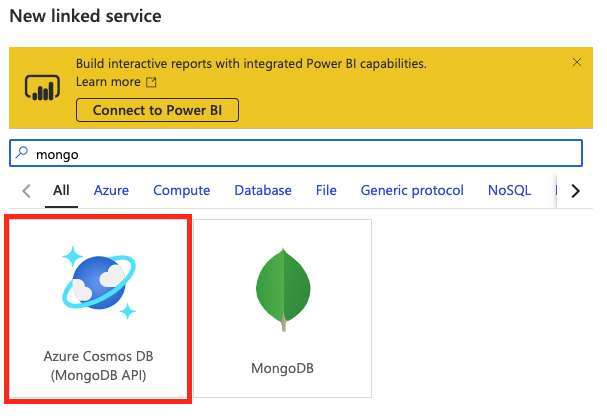
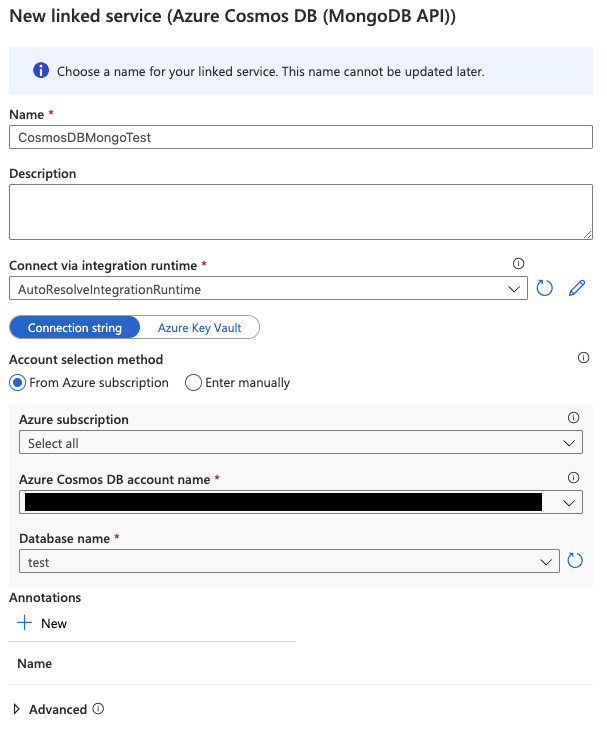
Synapse 側で Linked services を作成
こちらは、SQL API の時と同様に、Azure Synapse ワークスペースより Linked services を設定します。
リンクされたサービス名の名前は任意のものを設定してください。
この記事では、CosmosDBMongoTestという名前を使用します。
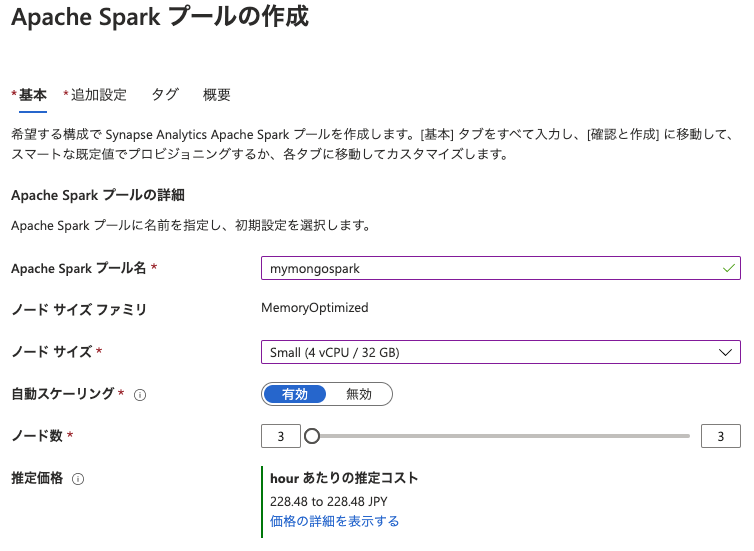
新しい Spark プールを作成
このサンプルでは Spark プールを使用して PySpark で Cosmos DB の分析ストアにアクセスします。
サンプルの実行にあたり、いくつかの Python ライブラリを Spark プール内にインストールしますが、既に別の用途で Spark プールを作成している場合、新しい Spark プールを作成することを推奨します。
Spark プールに Python ライブラリをインストールすることで、他に影響を与えないためです。
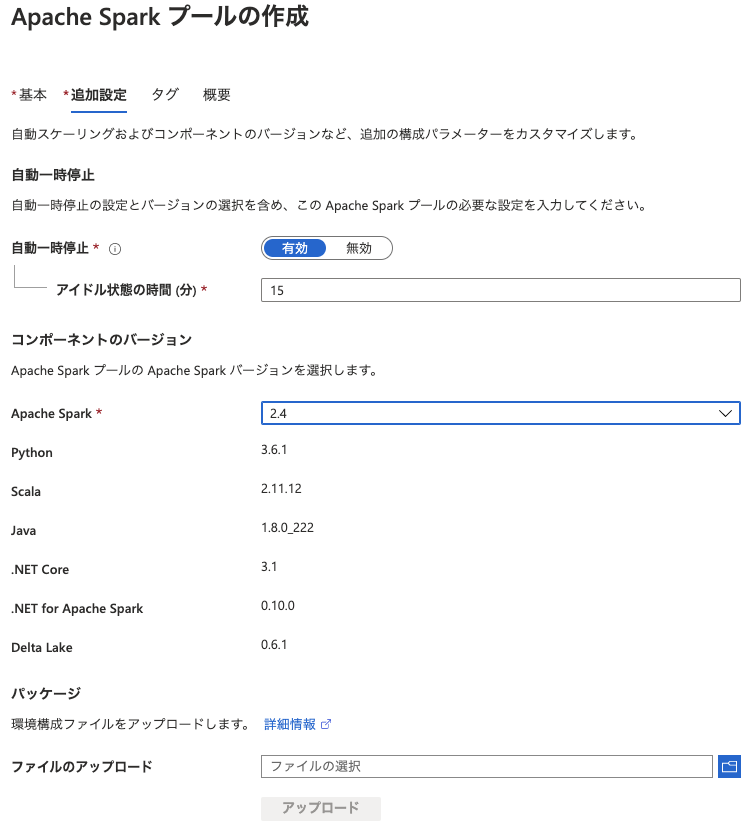
使用していない Spark プールについては、アイドル期間中はコンピューティングの課金は発生しません。(自動一時停止の設定)
デフォルトでは 15 分になっていますが、こちらを無効化しないようにしておくのがベストです。アイドル状態までの時間は任意で変更してください。
サンプル実行に必要なライブラリをインストール
新しく作成した Spark プールに対して、サンプル実行に必要な Python ライブラリをインストールします。
サンプル実行に必要なライブラリの一覧は、サンプルノートブックに記載のある通りです。
pymongo==2.8.1
aenum==2.1.2
backports-abc==0.5
bson==0.5.10
これを Spark プールにインストールします。インストールは pip 経由ではなく、pip freezeのリファレンスドキュメントで説明されている形式に従った要件ファイルを使用し、Spark プールの作成時、あるいは Azure ポータル、Synapse ワークスペースの専用画面から行います。
まず、ローカルに、requirements.txtを用意します。
pymongo==2.8.1
aenum==2.1.2
backports-abc==0.5
bson==0.5.10
今回は、Synapse ワークスペースの画面から、この requirements.txt を使用して Python モジュールのインストールを行います。
[Manage] -> [Apache Spark pools] 画面に遷移し、サンプルで使用する Spark プールを選択します。
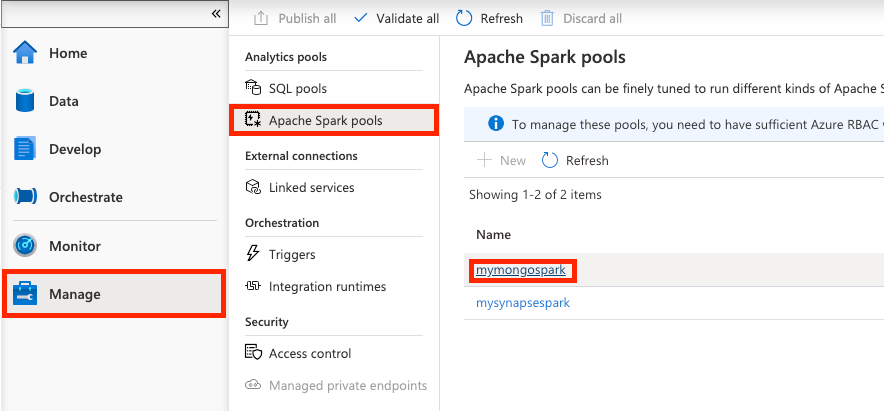
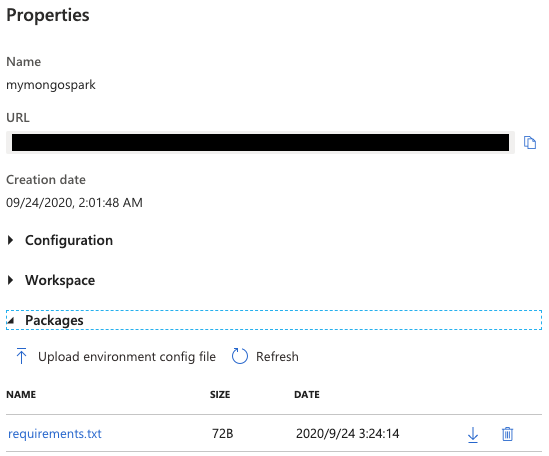
Spark プールを選択すると、プロパティ画面が表示されますので、[Packages] 欄にある Upload environment config file ボタンを選択し、先ほど作成した requirements.txt をアップロードしましょう。

アップロードが正常に完了すると、以下のような通知が確認でき、requirements.txt が適用されたことが確認できるはずです。

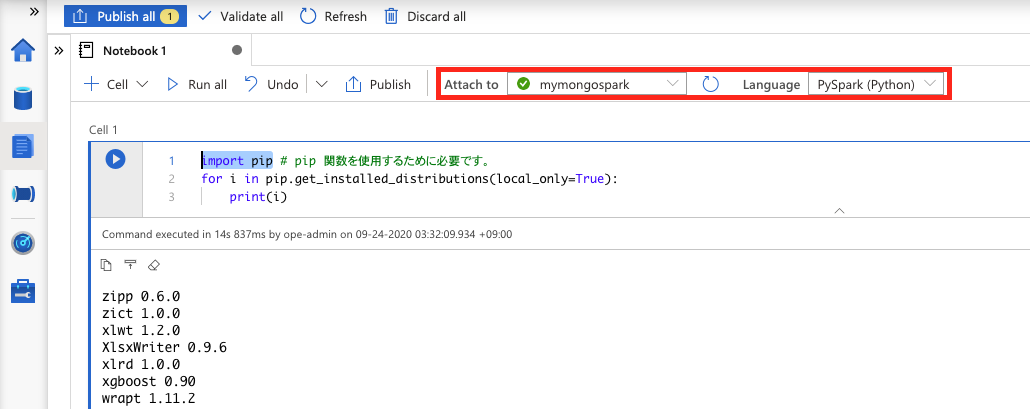
インストールされた Python ライブラリは、以下のコードで確認が可能です。Synapse ワークスペースのノートブックから実行することで確認することができます。
import pip # pip 関数を使用するために必要です。
for i in pip.get_installed_distributions(local_only=True):
print(i)
実行する際は、実行に使用する Spark プール、および Language が PySpark に設定されていることを確認しましょう。
requirements.txt に記載したパッケージは、Spark プールの開始時に PyPI からダウンロードされる仕組みになっており、Spark プールから Spark インスタンスが作成される度に使用されるようになります。
もし、出力結果に requirements.txt に記載した Python ライブラリが表示されていない場合は、Spark プールを再起動してみてください。
なお、requirements.txt のアップロード後は、Spark プールの再起動が内部的に実行されるため、環境によっては反映までに時間を要する場合があります。
MongoDB クライアントを初期化しデータを挿入
Python 用の MongoDB クライアントである pymongo を使用して、Cosmos DB のトランザクションストアにデータを挿入します。
MongoDB クライアントを使用するにあたって、CosmosDB のユーザー名とプライマリ/セカンダリ パスワードを先に取得しておきます。
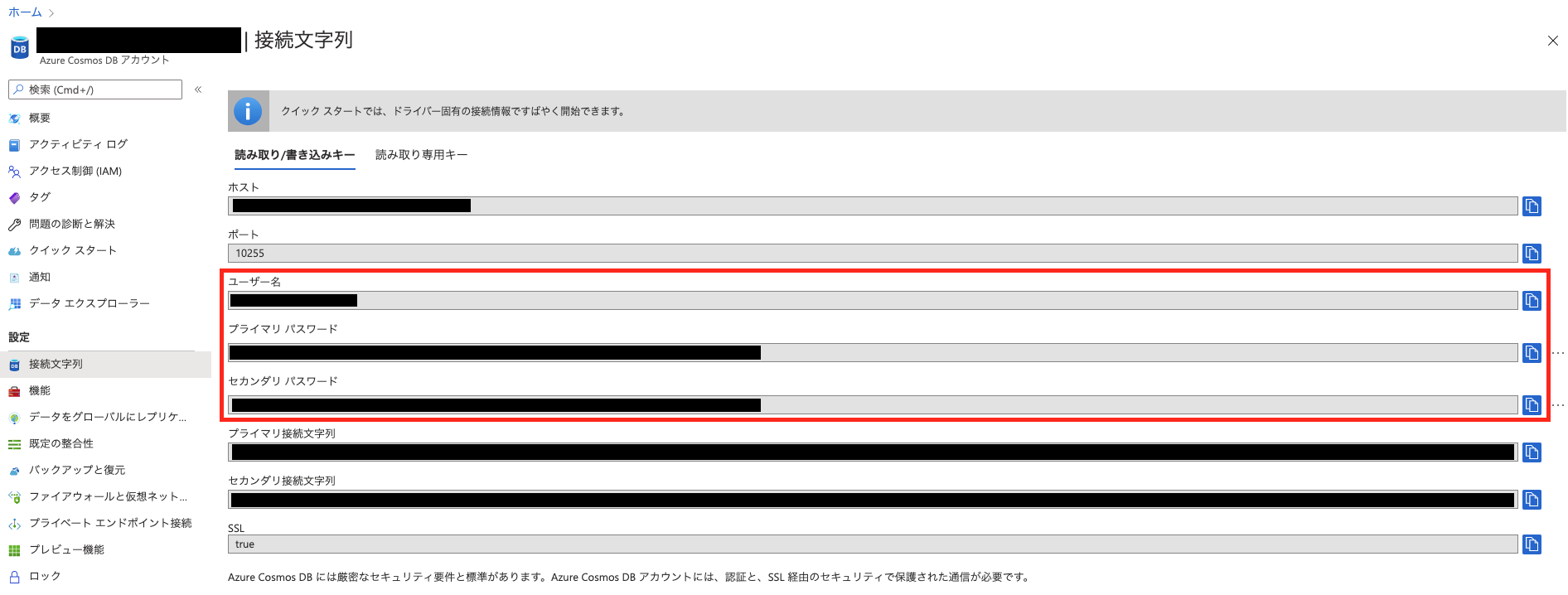
取得したら、変数として設定しておきます。
DATABASE_ACCOUNT_NAME = '<ここにユーザー名を入力>'
DATABASE_ACCOUNT_READWRITE_KEY = '<ここにプライマリ/セカンダリ パスワードを入力>'
設定したら、MongoDB クライアントを初期化します。
from pymongo import MongoClient
from bson import ObjectId # ObjectId が機能するため
client = MongoClient("mongodb://{account}.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb".format(account = DATABASE_ACCOUNT_NAME)) # 独自のデータベースアカウントのエンドポイント。
db = client.test # データベースを選択
db.authenticate(name=DATABASE_ACCOUNT_NAME,password=DATABASE_ACCOUNT_READWRITE_KEY) # データベースアカウント名と任意の読み取り/書き込みキーを使用します。
MongoDB クライアントを初期化したら、データを挿入します。500 アイテムを生成します。
from random import randint
import time
orders = db["htap"]
items = ['Pizza','Sandwich','Soup', 'Salad', 'Tacos']
prices = [2.99, 3.49, 5.49, 12.99, 54.49]
for x in range(1, 501):
order = {
'item' : items[randint(0, (len(items)-1))],
'price' : prices[randint(0, (len(prices)-1))],
'rating' : randint(1, 5),
'timestamp' : time.time()
}
result=orders.insert(order)
print('500 個の注文の作成が終了しました')
分析ストアからデータを確認
トランザクションストアにデータを挿入したデータが、分析ストアから確認できることを確認します。
データが裏側で自動的に ETL されるため、データの挿入後すぐに以下のコードを実行するとエラーになります。
5 分程度、時間をおいて実行してください。
# 分析ストアのデータをデータフレームにロードする
# シークレットを使用してセルを実行し、DATABASE_ACCOUNT_NAME および DATABASE_ACCOUNT_READWRITE_KEY 変数を取得します。
df = spark.read.format("cosmos.olap")\
.option("spark.cosmos.accountEndpoint", "https://{account}.documents.azure.com:443/".format(account = DATABASE_ACCOUNT_NAME))\
.option("spark.cosmos.accountKey", DATABASE_ACCOUNT_READWRITE_KEY)\
.option("spark.cosmos.database", "test")\
.option("spark.cosmos.container", "htap")\
.load()
# ピザの注文からのすべての収益を調べてみましょう
df.groupBy(df.item.string).sum().show()
# df[df.item.string == 'Pizza'].show(10)
# df.select(df['item'] == Struct).show(10)
# df.select("timestamp.float64").show(10)
# df.select("timestamp.string", when(df.timestamp.string != null)).show(10)
結果が返ってきたら、一緒にスキーマ情報も確認してみましょう。
df.schema
StructType(List(StructField(_rid,StringType,true),
StructField(_ts,LongType,true),StructField(id,StringType,true),
StructField(_etag,StringType,true),
StructField(_id,StructType(List(StructField(objectId,StringType,true))),true),
StructField(item,StructType(List(StructField(string,StringType,true))),true),
StructField(price,StructType(List(StructField(float64,DoubleType,true))),true),
StructField(rating,StructType(List(StructField(int32,IntegerType,true))),true),
StructField(timestamp,StructType(List(StructField(float64,DoubleType,true))),true),
StructField(_partitionKey,StructType(List(StructField(string,StringType,true))),true)))
形式が異なる timestamp データを追加で投入
さらにデータを投入していきます。
追加のデータ投入では、timestampデータの部分は、先ほどはtime.time()を指定していましたが、今回はstrftime("%Y-%m-%d %H:%M:%S")を指定してみます。
from random import randint
from time import strftime
orders = db["htap"]
items = ['Pizza','Sandwich','Soup', 'Salad', 'Tacos']
prices = [2.99, 3.49, 5.49, 12.99, 54.49]
for x in range(1, 501):
order = {
'item' : items[randint(0, (len(items)-1))],
'price' : prices[randint(0, (len(prices)-1))],
'rating' : randint(1, 5),
'timestamp' : strftime("%Y-%m-%d %H:%M:%S")
}
result=orders.insert(order)
print('500 個の注文の作成が終了しました')
もし、上記のコードの実行に時間がかかっている、またはエラーが返された場合、MongoDB クライアントをもう一度初期化した後、再実行してみてください。
追加したデータを確認
データの投入が完了したら、再度、分析ストアのデータを確認しましょう。
前述の通り、トランザクションストアから分析ストアに対してデータがバックグラウンドで ETL されているため、少し時間をおいて実行してください。
# 分析ストアのデータをデータフレームにロードする
# シークレットを使用してセルを実行し、DATABASE_ACCOUNT_NAME および DATABASE_ACCOUNT_READWRITE_KEY 変数を取得します。
df = spark.read.format("cosmos.olap")\
.option("spark.cosmos.accountEndpoint", "https://{account}.documents.azure.com:443/".format(account = DATABASE_ACCOUNT_NAME))\
.option("spark.cosmos.accountKey", DATABASE_ACCOUNT_READWRITE_KEY)\
.option("spark.cosmos.database", "test")\
.option("spark.cosmos.container", "htap")\
.load()
# ピザの注文からのすべての収益を調べてみましょう
df.filter( (df.timestamp.string != "")).show(10)
ここでのポイントは、timestamp.string パラメーターを指定していることです。これを指定することによって、time.time() で挿入されたデータではなく、strftime("%Y-%m-%d %H:%M:%S") で挿入された、ISO 文字列の日付が入っているデータのみを個別に読み取ることができます。
合わせて、先ほど同様、スキーマ情報も確認してみましょう。
df.schema
StructType(List(StructField(_rid,StringType,true),
StructField(_ts,LongType,true),
StructField(id,StringType,true),
StructField(_etag,StringType,true),
StructField(_id,StructType(List(StructField(objectId,StringType,true))),true),
StructField(item,StructType(List(StructField(string,StringType,true))),true),
StructField(price,StructType(List(StructField(float64,DoubleType,true))),true),
StructField(rating,StructType(List(StructField(int32,IntegerType,true))),true),
StructField(timestamp,StructType(List(StructField(float64,DoubleType,true),StructField(string,StringType,true))),true),
StructField(_partitionKey,StructType(List(StructField(string,StringType,true))),true)))
timestamp の部分がStructField(timestamp,StructType(List(StructField(float64,DoubleType,true),StructField(string,StringType,true))),true),に変更されていることを確認できると思います。
これによって、Azure Cosmos DB 分析ストアのスキーマ管理にて、スキーマ情報が変更されたことを確認することができると思います。
-
MongoDB のシャーディングについては、(古い書籍ですが)スケーリングMongoDB を読むと良いかと思います。※MongoDB 1.x 当時の本です。(現在の最新バージョンは 4.4) ↩