スクリーンショット
レジリエンスダッシュボード — スコア・障害シナリオ・SPOFを一画面で確認
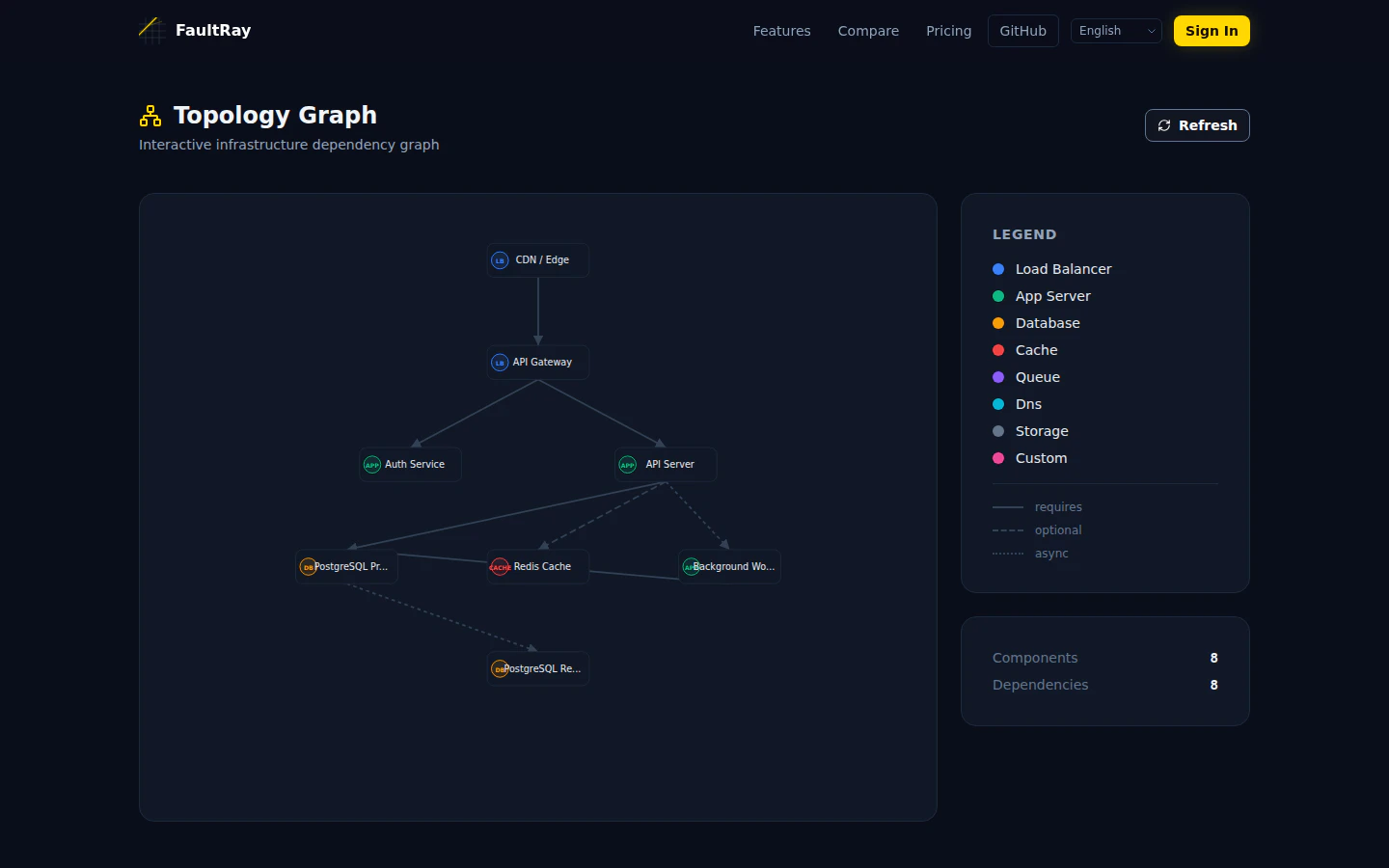
依存関係トポロジー — 障害伝播パスを可視化
terraform apply で本番が壊れた話
DevOps エンジニアなら誰でも、一度は terraform apply で痛い目を見たことがあるはずです。
PR はクリーンだった。terraform plan の出力も問題なさそうだった。レビューも通った。でも apply したら本番が落ちた。原因は replicas: 1 に変わっていたこと。plan の差分には出ていたけど、誰も気づかなかった。深夜 2 時にアラートが鳴って、そこから 4 時間の障害対応。
plan の出力は「何が変わるか」を教えてくれますが、「その変更でシステムがどれだけ脆くなるか」は教えてくれません。ここにギャップがあります。
作ったもの: FaultRay
FaultRay は、インフラの障害シミュレーションをメモリ上で実行するツールです。本番環境には一切触れません。
やっていることはシンプルで、インフラの構成情報から依存関係グラフを構築し、2,000 以上の障害シナリオを自動生成して、レジリエンススコアを 0-100 で算出します。Terraform の plan JSON を食わせれば、変更前後のスコア差分が出ます。
使い方
インストールは pip 一発です。
pip install faultray
faultray demo
╭────────── FaultRay Chaos Simulation Report ──────────╮
│ Resilience Score: 36/100 │
│ Scenarios tested: 2,000+ │
│ Critical: 7 Warning: 66 Passed: 77 │
╰──────────────────────────────────────────────────────╯
Terraform 連携
本命はこちらです。terraform plan の出力を JSON で渡すだけ。
terraform plan -out=plan.out
terraform show -json plan.out > plan.json
faultray tf-check plan.json
╭──────────── FaultRay Terraform Guard ────────────╮
│ │
│ Score Before: 72/100 │
│ Score After: 45/100 (-27 points) │
│ │
│ NEW RISKS: │
│ - Database is now a single point of failure │
│ - Cache has no replication (data loss risk) │
│ │
│ Recommendation: HIGH RISK - Review Required │
│ │
╰───────────────────────────────────────────────────╯
スコアが 27 ポイント下がっていて、DB が単一障害点になったことが一目でわかります。plan の差分を目で追うよりはるかに速い。
CI/CD 統合
GitHub Actions に組み込めば、レジリエンスが下がる変更を自動でブロックできます。
# .github/workflows/terraform.yml
name: Terraform Plan Check
on:
pull_request:
paths: ["*.tf"]
jobs:
resilience-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Terraform Plan
run: |
terraform init
terraform plan -out=plan.out
terraform show -json plan.out > plan.json
- name: FaultRay Check
run: |
pip install faultray
faultray tf-check plan.json --fail-on-regression --min-score 60
--fail-on-regression はスコアが 1 ポイントでも下がればジョブを失敗させます。--min-score 60 は結果スコアが 60 未満なら失敗。両方の併用も可能です。
仕組み
依存関係グラフとシナリオ自動生成
FaultRay はインフラ定義(YAML, Terraform state, Prometheus)から NetworkX の有向グラフを構築します。コンポーネントがノード、依存関係がエッジです。
このグラフに対して、単一ノード障害、複数ノード同時障害、エッジ切断、負荷急増などのシナリオを組み合わせて 2,000 以上のケースを自動生成します。手動でシナリオを書く必要はありません。
5 層可用性リミットモデル
FaultRay のユニークな特徴が、可用性の理論的上限を算出する 5 層モデルです。
Layer 1: ソフトウェア限界 → 4.00 nines (99.99%)
Layer 2: ハードウェア限界 → 5.91 nines (99.999%)
Layer 3: 理論限界 → 6.65 nines (99.99997%)
Layer 4: 運用限界 → 3.50 nines (99.95%)
Layer 5: 外部SLAカスケード → 3.00 nines (99.9%)
システム全体の可用性は各層の最小値で決まります。
A_system = min(L1, L2, L3, L4, L5)
この例だと Layer 5 の外部 SLA が 99.9% なので、どれだけ内部を強化しても 99.9% が上限です。SLO を 99.99% に設定しているなら、エンジニアリング努力の前にアーキテクチャを変える必要があるとわかります。
カスケードエンジン
コアのカスケードエンジンは、ラベル付き遷移システム (Labeled Transition System) として形式化されています。あるコンポーネントが障害を起こしたとき、依存関係グラフ上をどう伝搬するかを追跡します。「Redis が死んだら、キャッシュ層が落ち、API のレイテンシが上がり、フロントエンドがタイムアウトする」という連鎖を自動的に検出します。
AI エージェント障害モデル
v11.0 で追加した差別化ポイントです。
インフラ障害は AI エージェントに固有の影響を与えます。例えば、データベースがダウンしたとき、従来のアプリケーションはエラーを返します。しかし AI エージェントは、データソースが利用できなくなっても自信満々に誤った回答を返すことがあります。これがハルシネーションです。
FaultRay はこのメカニズムを数学的にモデル化しています。
H(a, D, I) = 1 - ∏(1 - h_d) (d ∈ D_unhealthy)
a がエージェント、D がデータソース集合、I がインフラ状態です。データソースが健全なら H はベースラインの値ですが、インフラ障害でデータソースが不健全になると H は単調に増加します。
FaultRay が検出する障害モードは 10 種類あり、代表的なものにハルシネーション、コンテキストオーバーフロー、LLM レート制限、トークン枯渇、ツール障害、エージェントループ、プロンプトインジェクションなどがあります。
検証結果
18 件の実インシデント(AWS us-east-1 障害、GCP ネットワーク障害、Azure DNS 障害、Meta BGP ミス設定、Cloudflare 制御プレーン障害など)に対してバックテストを実施しました。
影響を受けるコンポーネントの特定精度は F1 = 1.000 でした。
ただし、これは post-hoc(事後)検証です。インシデント情報をもとにインフラ構成を再現してシミュレーションしているので、予測というより「モデルが正しくカスケードを再現できるか」の検証です。この点は正直に述べておきます。
正直な限界
- モデルの精度は入力に依存します。 YAML で定義されていない依存関係は検出できません。定義が実態と乖離していれば、結果も乖離します。
- AI エージェントモデルは理論段階です。 数学的には妥当ですが、大規模な本番環境での実証はまだありません。
-
実行時の動的挙動はシミュレートしません。 FaultRay は構造的な脆弱性を検出するツールであり、実際のトラフィックパターンやリアルタイムのメトリクスに基づく動的シミュレーションは別のエンジン(
faultray dynamic)で対応しますが、実環境の再現ではありません。 - 従来のカオスエンジニアリングの代替ではありません。 FaultRay はシフトレフト(開発初期段階)での検証に最適化されており、本番での Chaos Monkey 的なテストとは補完関係にあります。
開発規模
個人開発ですが、品質には妥協していません。
- テスト: 32,000 件以上(全パス)
- CI: GitHub Actions で lint / 型検査 / ユニット / E2E / セキュリティ / パフォーマンス / mutation を自動実行
- 特許: USPTO 仮特許出願済み(US 64/010,200)
- 論文: Zenodo 公開済み(DOI: 10.5281/zenodo.19139911)
デモ
ブラウザで試せるデモがあります: https://faultray.com/demo
リンク
- GitHub: https://github.com/mattyopon/faultray
- ライブデモ: https://faultray.com/demo
- 論文 (DOI): https://doi.org/10.5281/zenodo.19139911
- PyPI: https://pypi.org/project/faultray/
- 特許出願: US Provisional Patent Application No. 64/010,200