とても多くのお客様がVantageとAWSのサービスとの統合に関心を持っています。そのようなトピックからここではAWS AppFlowとVantageの接続について説明します。
このガイドで説明するアプローチはVantageとAppFlowとを統合するための多くの可能性のあるアプローチの一つであり、そのままの形で提供されるものです。 このアプローチは社内で実装されテストされていますが、TeradataまたはAWSのいずれからも、このアプローチに関する正式なサポートはありませんのでご注意ください。
免責事項:本ガイドは、AWSとTeradata製品の両方のドキュメントからの内容を含んでいます。
概要
本記事では、SlackからAWS AppFlow経由でAWS S3にデータを転送し、Teradata Vantage Native Object Store(NOS)を使用してS3内のデータにアクセスする手順を説明します。
AWS AppFlowについて
AWS AppFlowは、Salesforce、Marketo、Slack、ServiceNowなどのSaaSアプリケーションと、Amazon S3、Amazon RedshiftなどのAWSサービス間で安全にデータを転送できる、フルマネージの統合サービスである。AppFlowは、移動中のデータを自動的に暗号化し、AWS PrivateLinkと統合されたSaaSアプリケーションの公衆インターネット上でのデータの流れを制限することができ、セキュリティ脅威への露出を減らすことができます。
AWS AppFlowは、本日現在、16のソースから選択でき、Amazon S3、Amazon Redshift、Salesforce、Snowflakeの4つの宛先にデータを送信します。
Teradata Vantageについて
Vantageは、
-
パーベイシブ・データ・インテリジェンスのためのプラットフォームで、組織のあらゆる部分のユーザーとシステムにインテリジェントな回答をリアルタイムで提供します。Vantageは、規模、量、複雑さに関係なく、ビジネスデータの100パーセントを活用することが可能です。
-
記述的分析、予測的分析、処方的分析、自律的意思決定、ML機能、可視化ツールを統合し、データがどこに存在しても、リアルタイムのビジネスインテリジェンスを大規模に発掘する統合プラットフォームです。
Vantageは、小規模から始めて、使用した分だけを支払ってコンピュートやストレージを弾力的に拡張し、低コストのオブジェクトストアを活用して、分析ワークロードを統合することを可能にします。
- R、Python、Teradata Studio、およびその他のSQLベースのツールをサポートしています。Vantageは、パブリッククラウド、オンプレミス、最適化されたインフラ、コモディティインフラ、As-a-Serviceのいずれでも導入可能です。
Teradata Vantage Native Object Store (NOS) を使用すると、標準SQLを使用してAmazon S3などの外部オブジェクトストアにあるデータを探索することができます。NOSを使用するために、特別なオブジェクトストレージ側の計算インフラストラクチャは必要ありません。S3バケットにあるデータを探索するには、バケットを指すNOSテーブル定義を作成するだけです。NOSを使えば、S3からデータを素早くインポートしたり、データベース内の他のテーブルと結合したりすることも可能です。
前提条件
この記事をご理解いただくためにはAWS AppFlowサービスやTeradata Vantageを理解されていることが期待されます。
以下のアカウント、システムが必要です:
・AWSアカウント
・SQLE 17.0+を搭載したTeradata Vantageインスタンス
・AppFlowのデータ(ptctsoutputなど)を保存するS3バケット
・自分が管理者になっているワークスペースのあるSlackアカウント。必要であれば、新しいワークスペースを作成します。
手順
前提条件を満たした上で、以下のステップを踏んでください:
- Slackで「appFlow」アプリを作成し、設定情報を収集する
- フローを作成する
- NOSを使ったデータの探索
ステップ1. AWS AppFlow用のSlackアプリを作成する
Slackにログインし、「apps」 を開きます。「appFlow」というアプリを作成します。

アプリをクリックし、「App Credentials」にアプリのクライアントID、クライアントシークレットをメモします。Slackインスタンス名はワークスペース名です。AWS AppFlowでSlackの接続を作成するには、クライアントID、クライアントシークレット、インスタンス名が必要です。
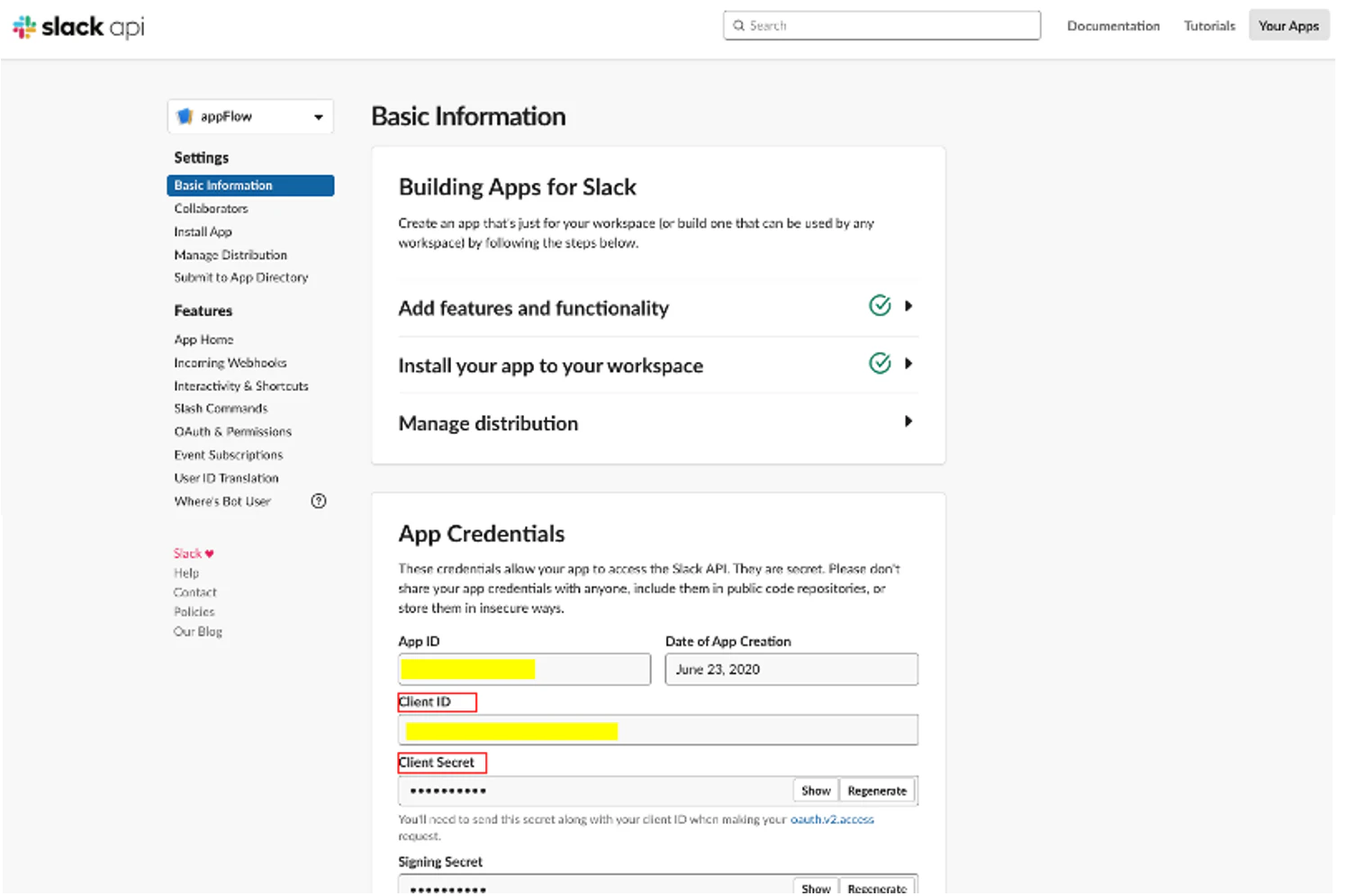
AppFlow用のSlack接続を作成するために必要な手順の詳細は、こちら をご覧ください。
注:説明の2番目の「redirect URL」と3番目の「Set user token scopes」は、アプリ「appFlow」の「OAuth & Permissions」をクリックして設定することができます。
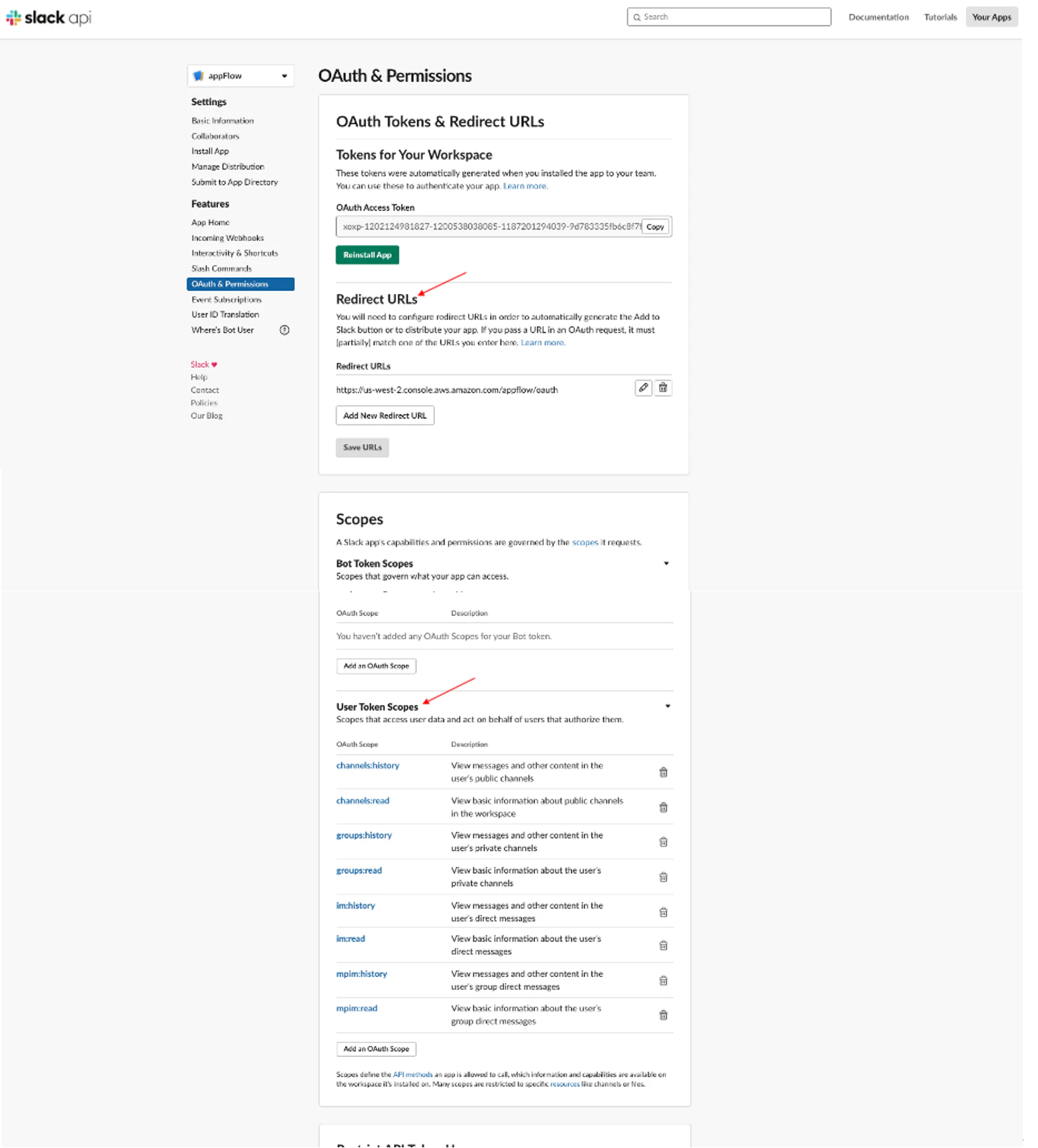
ステップ2. フローを作成する
AppFlowコンソール にアクセスし、"Create flow "をクリックします。
1. フローの詳細を指定する
「フロー名」と「フローの説明」(任意)を入力し、「暗号化設定のカスタマイズ(詳細)」のチェックは外したままにしてください。Next "をクリックします。
2. フローを設定する
1. 「ソース名」は「Slack」、「Slack接続の選択」は「新規接続の作成」を選択します。
2. Slackアプリ「appFlow」からClient ID、Client secret、Workspaceを入力します。名前を付けて「Continue」をクリックします。
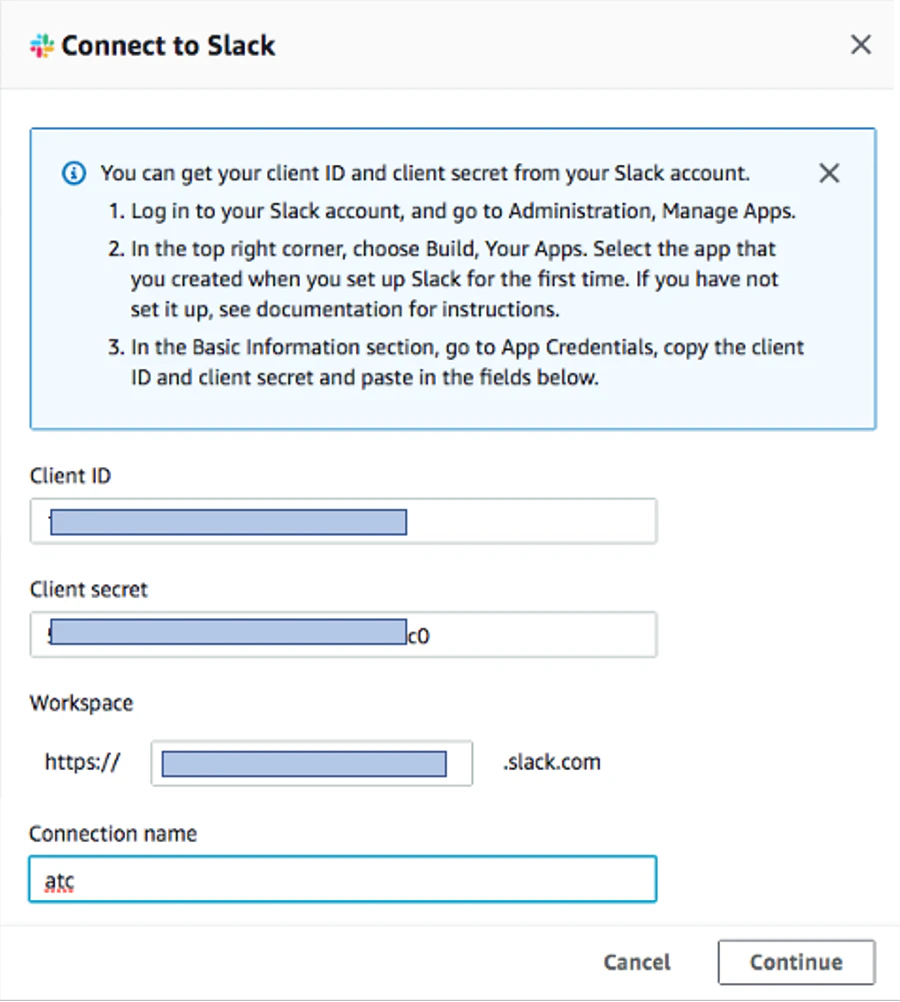
3. Slackワークスペースへのアクセス許可を求めるウィンドウが表示された場合は「許可」をクリックし、Slackワークスペースへのサインインを求めるウィンドウが表示された場合はSlackのメールアドレスとパスワードを入力する。
4. "Slackオブジェクト "に "Conversations "を選択する。
5. "Slackチャンネルを選択 "でデータを転送したいチャンネルを選ぶ
6. 「Destination name」に「Amazon S3」を選び、先ほど 作成したデータを保存するバケット(例:ptctsoutput)を選択します。
7. "Flow trigger "は "Run on demand "を選択します。「Next」をクリックします。
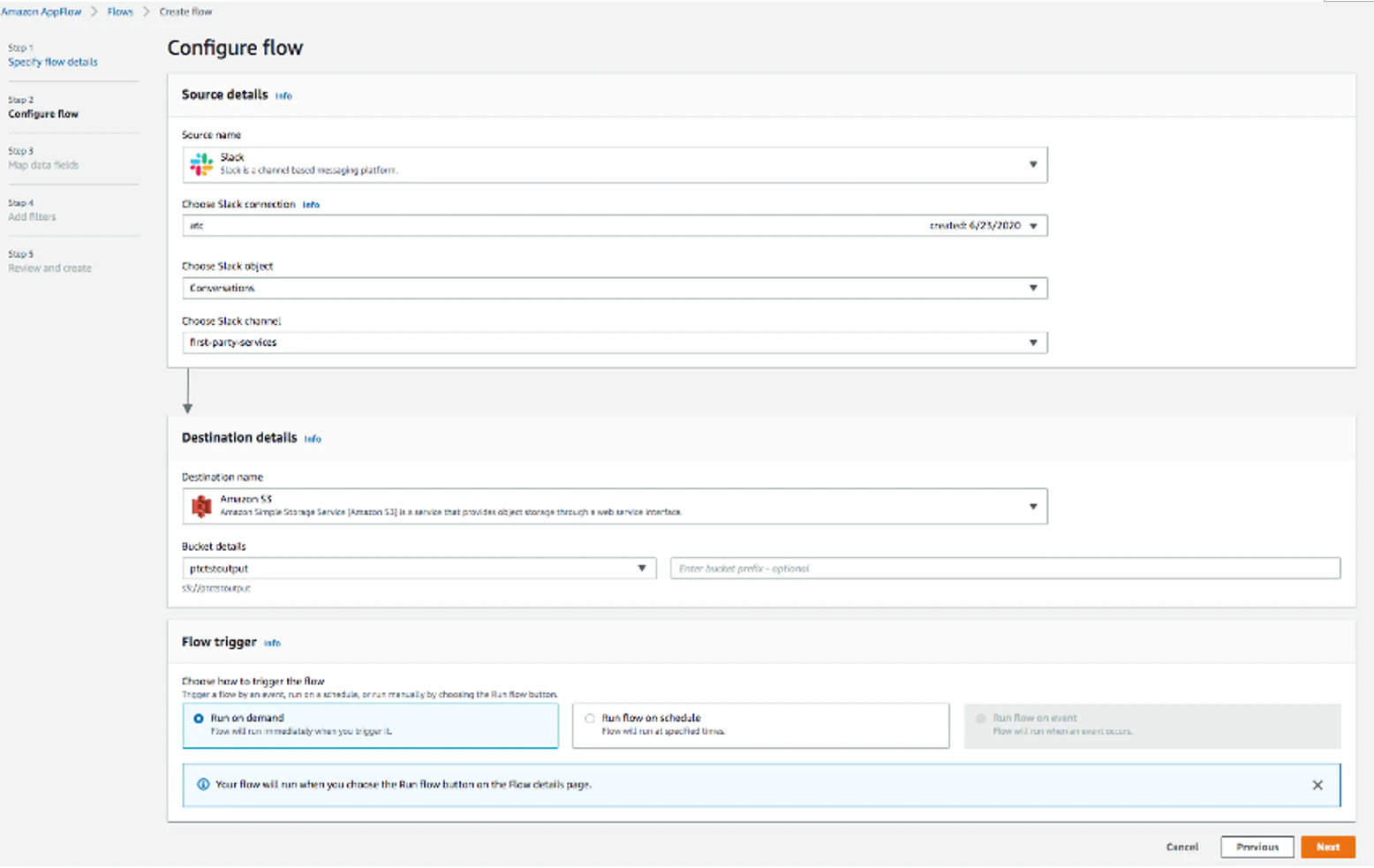
3. 地図データフィールド
- "マッピング方法 "として "手動でフィールドをマッピングする "を使用する
- 簡単のため,"Source to destination filed mapping "は "Map all fields directly "を選択します.
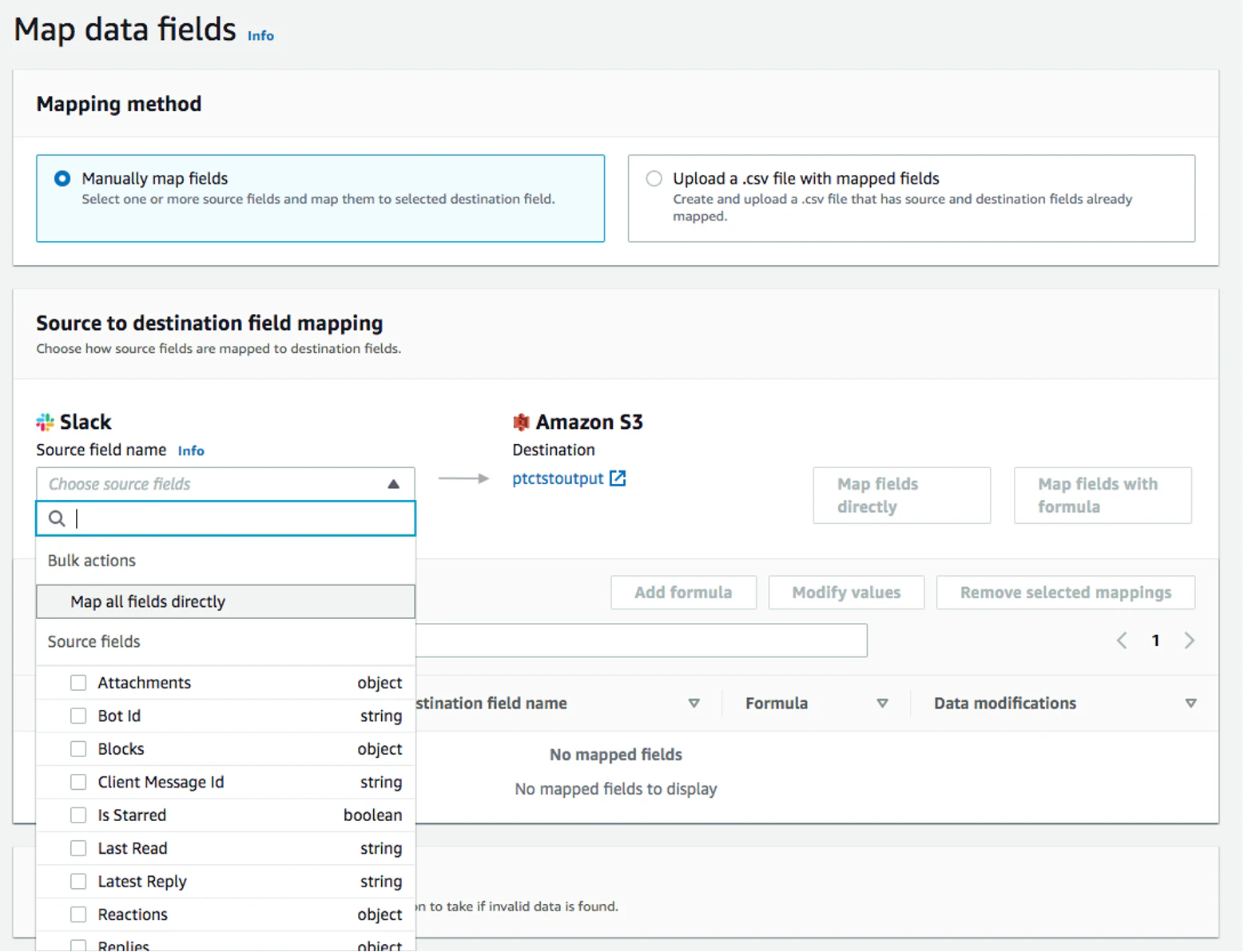
すべてのフィールドを直接マッピングする」をクリックすると、すべてのフィールドが「マッピングされたフィールド」の下に表示されます。計算式の追加(連結)」、「値の修正(フィールド値のマスクまたは切り捨て)」、「選択したマッピングの削除」を行いたいフィールドのチェックボックスをクリックします。
この例では、チェックボックスはチェックされません。
- "Next "をクリックします。
4. フィルターの追加
転送したいデータにタイムスタンプフィルターを追加することができます。この例では、フィルターは追加されません。Next "をクリックします。
5. レビューと作成
入力したすべての情報を確認します。必要であれば修正します。「フローの作成」をクリックします。
6. ランフロー
フロー作成成功のメッセージが、フロー情報とともに表示されます。右上の "Run flow "をクリックします。
フローの実行が完了すると、実行が成功したことを示すメッセージが表示されます。
メッセージの例:

バケツへのリンクをクリックすると、データを見ることができます。
7. データファイルのプロパティを変更する
S3バケット内のデータファイルをクリックし、"プロパティ "タブをクリックします。
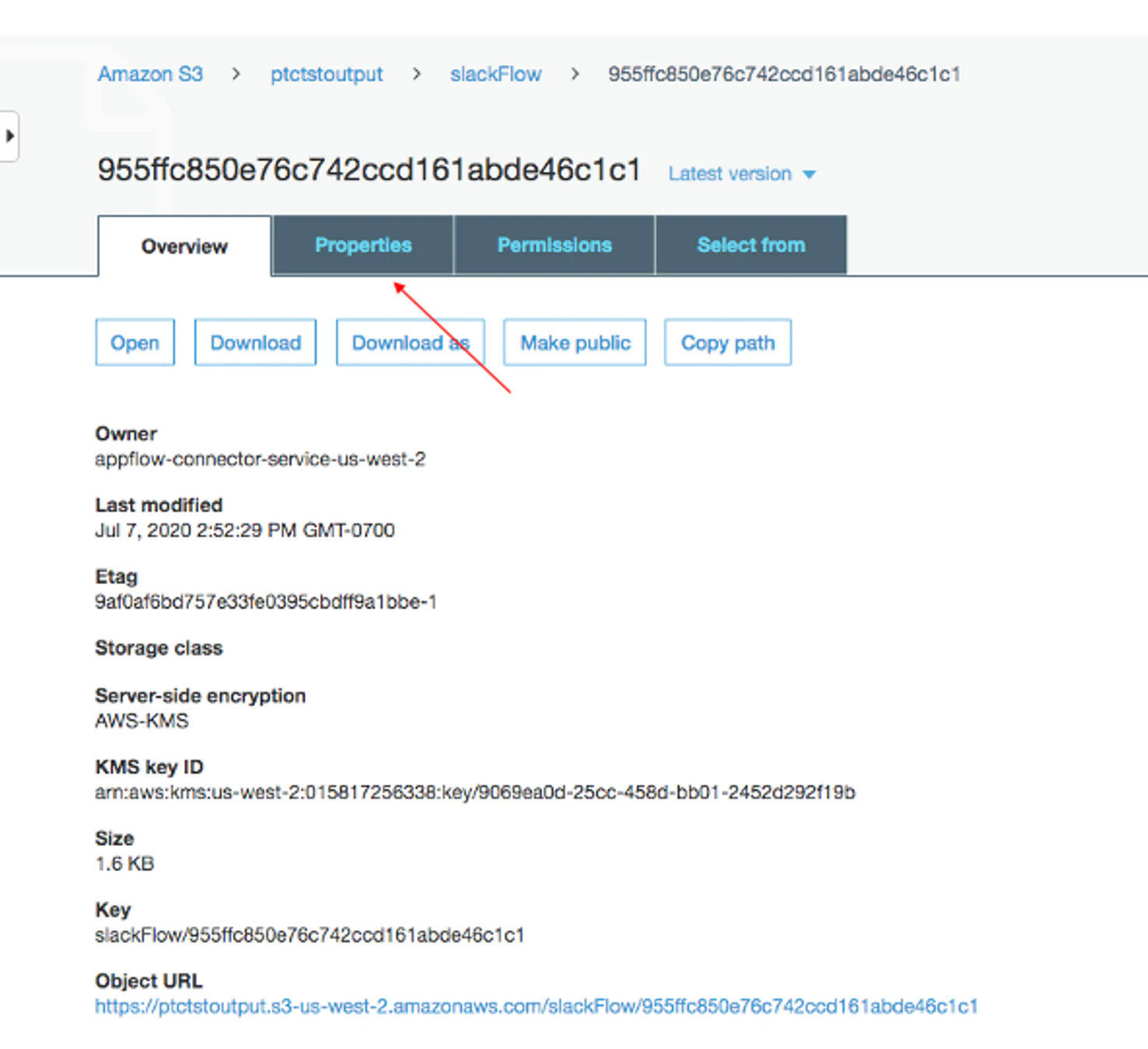
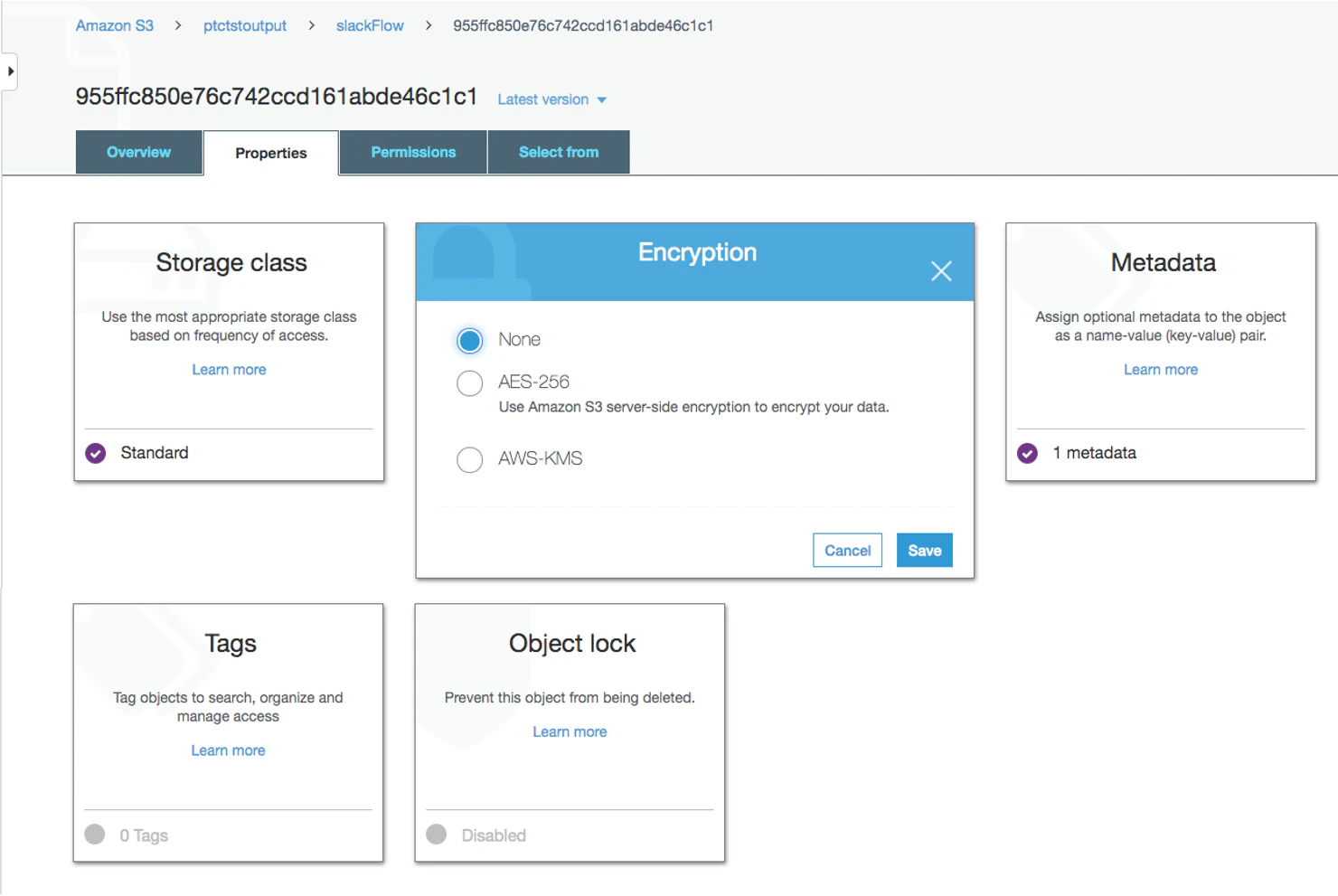
デフォルトでは、slackのデータは暗号化されています。暗号化」から「AWS-KMS」をクリックし、「AWS-KMS」の暗号化から「なし」に変更します。保存」をクリックします。
ステップ3. NOSを使ったデータの探索
Native Object Storeには、AWS S3内のデータを探索・分析するための機能が組み込まれています。ここでは、NOSのよく使われる機能をいくつか列挙します。
1.外部テーブルの作成
外部テーブルを使用すると、Vantage SQL Engine 内で外部データを簡単に参照でき、構造化されたリレーショナル形式 でデータを利用できるようになります。
外部テーブルを作成するには、まず認証情報を使用してTeradata Vantageシステムにログインします。S3バケットにアクセスするためのアクセスキーを持つAUTHORIZATIONオブジェクトを作成します。Authorizationオブジェクトは、AWS S3データにアクセスするために、誰が外部テーブルの使用を許可されるかの制御を確立することで、セキュリティを強化します。
CREATE AUTHORIZATION DefAuth_S3
AS DEFINER TRUSTED
USER 'A*****************' /* AccessKeyId */
PASSWORD '********'; /* SecretAccessKey */
USER "はAWSアカウントのAccessKeyId、"PASSWORD "はSecretAccessKeyです。
S3上のJSONファイルに対して、以下のコマンドで外部テーブルを作成します。
CREATE MULTISET FOREIGN TABLE slackData,
EXTERNAL SECURITY DEFINER TRUSTED DefAuth_S3
(
Location VARCHAR(2048) CHARACTER SET UNICODE CASESPECIFIC,
Payload JSON(8388096) INLINE LENGTH 32000 CHARACTER SET UNICODE
)
USING
(
LOCATION ('/S3/s3.amazonaws.com/ptctstoutput/slackFlow/955ffc850e76c742ccd161abde46c1c1')
);
最低限、外部テーブルの定義には、テーブル名と、オブジェクトストアのデータを指すLocation句(黄色でハイライトされています)を含める必要があります。Locationは、Amazonでは "バケット "と呼ばれるトップレベルのシングルネームが必要です。
ファイル名の末尾に標準的な拡張子(.json、.csv、.parquet)がない場合、データファイルの種類を示すために、LocationとPayloadの列定義も必要です(青緑色でハイライトされています)。
外部テーブルは、常にNoPI(No Primary Index)テーブルとして定義される。
いったん外部テーブルが作成されると、外部テーブル上で "Select "を実行することによって、S3データセットの内容を照会することができます。
SELECT * FROM slackData;
SELECT payload.* FROM slackData;
外部テーブルには、2つのカラムしか含まれていません。LocationとPayloadです。Locationは、オブジェクトストアシステム内のアドレスです。データ自体はpayloadカラムで表され、外部テーブルの各レコード内のpayload値は、単一のJSONオブジェクトとそのすべての名前-値ペアを表します。
"SELECT * FROM slackData; "の出力例

サンプル出力形式「SELECT payload.* FROM slackData;」。

2.JSON_KEYS 表演算子
JSON データは、レコードによって異なる属性を含むことがあります。データストアで可能な属性の全リストを確認するには、JSON_KEYSを使用します:
SELECT DISTINCT * FROM JSON_KEYS (ON (SELECT payload FROM slackData)) AS j;
出力します:

3.ビューの作成
ビューは、ペイロード属性に関連する名前を単純化し、オブジェクトストアのデータに対して実行可能なSQLを簡単にコーディングできるようにし、外部テーブルのLocation参照を隠して通常の列のように見えるようにすることができます。
以下は、上記のJSON_KEYSテーブル演算子から検出された属性を使用した、ビュー作成文のサンプルです。
REPLACE VIEW slackDataView AS (
SELECT CAST(payload.client_msg_id AS VARCHAR(50)) Client_Msg_ID,
CAST(payload."type" AS VARCHAR(10)) "Type",
CAST(payload.subtype AS VARCHAR(20)) Subtype,
CAST(payload."text" AS VARCHAR(100)) Msg_Text,
CAST(payload.team AS VARCHAR(20)) Team_ID,
CAST(payload.ts AS VARCHAR(50)) Time_Stamp,
CAST(payload."user" AS VARCHAR(20)) User_ID,
CAST(payload.blocks[0].block_id AS VARCHAR(10)) Block_ID,
CAST(payload.blocks[0]."type" AS VARCHAR(10)) Block_Type
FROM slackData);
SELECT * FROM slackDataView;
サンプル出力です:

4.READ_NOS 表演算子
READ_NOSテーブル演算子は、最初に外部テーブルを定義することなく、データの一部をサンプリングして探索したり、Location句で指定したすべてのオブジェクトに関連するキーのリストを表示するために使用することができます。
SELECT top 5 payload.*
FROM READ_NOS (
ON (SELECT CAST(NULL AS JSON CHARACTER SET Unicode))
USING
LOCATION ('/s3/s3.amazonaws.com/ptctstoutput/slackFlow/955ffc850e76c742ccd161abde46c1c1')
ACCESS_ID ('A**********') /* AccessKeyId */
ACCESS_KEY (‘8**********’) /* SecretAccessKey */
) AS D
GROUP BY 1;
出力します:

5.S3データをデータベース内のテーブルに結合する
外部テーブルは、Vantage のテーブルと結合して、さらに分析することができます。たとえば、MemberInfo テーブルは、memberID と memberName の 2 つの列を持つ Vantage のテーブルで、次のようなデータを含んでいます:

slackDataの外部テーブルを確立されたデータベーステーブルMemberInfoに結合することで、特定のメッセージについて、memberNameなどの追加情報を取得することができます。
SELECT s.payload.client_msg_id as Client_Msg_ID,
s.payload."text" as Msg_Text,
s.payload.team as Team_ID,
s.payload."user" as User_ID,
m.memberName as User_Name
FROM slackData s, MemberInfo m
WHERE User_ID = m.memberID
ORDER BY 1;

6.S3データをVantageにインポートする
S3データの永続的なコピーを持つことは、同じデータへの反復的なアクセスが予想される場合に便利です。NOSの外部テーブルは、自動的にS3データの永続的なコピーを作成しない。データベースにデータを取り込むためのいくつかのアプローチについて、以下に説明します。
a. データを含むテーブルを作成する
CREATE TABLE AS ... WITH DATA" ステートメントは、外部テーブル定義がソーステーブルとして機能する状態で使用することができます。この方法では、外部テーブルのペイロードの中からターゲットテーブルに含める属性を選択し、リレーショナルテーブルのカラムにどのような名前を付けるかを決定することができます。
CREATE TABLE slackDataVantage AS (
SELECT CAST(payload.client_msg_id AS VARCHAR(50)) Client_Msg_ID,
CAST(payload."type" AS VARCHAR(10)) "Type",
CAST(payload.subtype AS VARCHAR(20)) Subtype,
CAST(payload."text" AS VARCHAR(100)) Msg_Text,
CAST(payload.team AS VARCHAR(20)) Team_ID,
CAST(payload.ts AS VARCHAR(50)) Time_Stamp,
CAST(payload."user" AS VARCHAR(20)) User_ID,
CAST(payload.blocks[0].block_id AS VARCHAR(10)) Block_ID,
CAST(payload.blocks[0]."type" AS VARCHAR(10)) Block_Type
FROM slackData)
WITH DATA
NO PRIMARY INDEX;
"SELECT * FROM slackDataVantage;" の結果です:

外部テーブルを使用する代わりに、READ_NOS テーブル演算子を使用することができます。このテーブル演算子により、最初に外部テーブルを構築することなく、オブジェクトストアから直接データにアクセスすることができます。READ_NOSをCREATE TABLE AS句と組み合わせて、データベース内にデータの永続的なバージョンを構築することができます。
CREATE TABLE slackDataReadNOS AS (
SELECT CAST(payload.client_msg_id AS VARCHAR(50)) Client_Msg_ID,
CAST(payload."type" AS VARCHAR(10)) "Type",
CAST(payload.subtype AS VARCHAR(20)) Subtype,
CAST(payload."text" AS VARCHAR(100)) Msg_Text,
CAST(payload.team AS VARCHAR(20)) Team_ID,
CAST(payload.ts AS VARCHAR(50)) Time_Stamp,
CAST(payload."user" AS VARCHAR(20)) User_ID,
CAST(payload.blocks[0].block_id AS VARCHAR(10)) Block_ID,
CAST(payload.blocks[0]."type" AS VARCHAR(10)) Block_Type
FROM READ_NOS(
ON (SELECT CAST(NULL AS JSON CHARACTER SET Unicode))
USING
LOCATION ('/s3/s3.amazonaws.com/ptctstoutput/slackFlow/955ffc850e76c742ccd161abde46c1c1')
ACCESS_ID ('A********') /* AccessKeyId */
ACCESS_KEY (‘********’) /*SecretAccessKey*/
) AS D
) WITH DATA;
slackDataReadNOSテーブルの検索結果:

7.INSERT SELECTステートメント
S3データをリレーショナルテーブルに配置するもう一つの方法は、「INSERT SELECT」である。この方法では、外部テーブルがソーステーブルであり、新しく作成されたパーマネントテーブルが挿入されるテーブルです。上記のREAD_NOSの例とは逆に、この方法ではパーマネント・テーブルを事前に作成する必要がある。
INSERT SELECT方式の利点の1つは、ターゲット・テーブルの属性を変更できることです。例えば、ターゲットテーブルをMULTISETにするかしないかを指定したり、別のプライマリインデックスを選択したりすることができます。
CREATE TABLE slackDataPerm, FALLBACK ,
NO BEFORE JOURNAL,
NO AFTER JOURNAL,
CHECKSUM = DEFAULT,
DEFAULT MERGEBLOCKRATIO,
MAP = TD_MAP1
(
Client_Msg_ID VARCHAR(50) CHARACTER SET LATIN NOT CASESPECIFIC,
Content_Type VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Subtype VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Content_Text VARCHAR(100) CHARACTER SET LATIN NOT CASESPECIFIC,
Team_ID VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Msg_Time VARCHAR(50) CHARACTER SET LATIN NOT CASESPECIFIC,
User_ID VARCHAR(20) CHARACTER SET LATIN NOT CASESPECIFIC,
Block_ID VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC,
Block_Type VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC
) PRIMARY INDEX (Client_Msg_ID);
INSERT INTO slackDataPerm
SELECT CAST(payload.client_msg_id AS VARCHAR(50)) Client_Msg_ID,
CAST(payload."type" AS VARCHAR(10)) "Type",
CAST(payload.subtype AS VARCHAR(20)) Subtype,
CAST(payload."text" AS VARCHAR(100)) Msg_Text,
CAST(payload.team AS VARCHAR(20)) Team_ID,
CAST(payload.ts AS VARCHAR(50)) Time_Stamp,
CAST(payload."user" AS VARCHAR(20)) User_ID,
CAST(payload.blocks[0].block_id AS VARCHAR(10)) Block_ID,
CAST(payload.blocks[0]."type" AS VARCHAR(10)) Block_Type
FROM slackData;
SELECT * FROM slackDataPerm;
サンプル結果です:

おわりに
Amazon AppFlowでS3に落としたデータをVantageで様々にアクセスする方法を記述してみました。皆様もぜひお試しください!