目的
前回の投稿でAWS Rekognitionについて軽く触れました。
AWS Rekognition デモまとめ
今回は実際にAzure Video Indexerのデモを体験したので、Rekognition同様に使用感等をみていけたらと思います。
Rekognitionとの違い
Video Indexerは基本的にはRekognitionとできることが同じです。そのため違いを説明していきます。
- UIの違い
- 会話内容トピック
- ブランド認識
- シーン分割
- カスタマイズ性
- 顔の分析/比較(機能がないだけで説明は省略します)
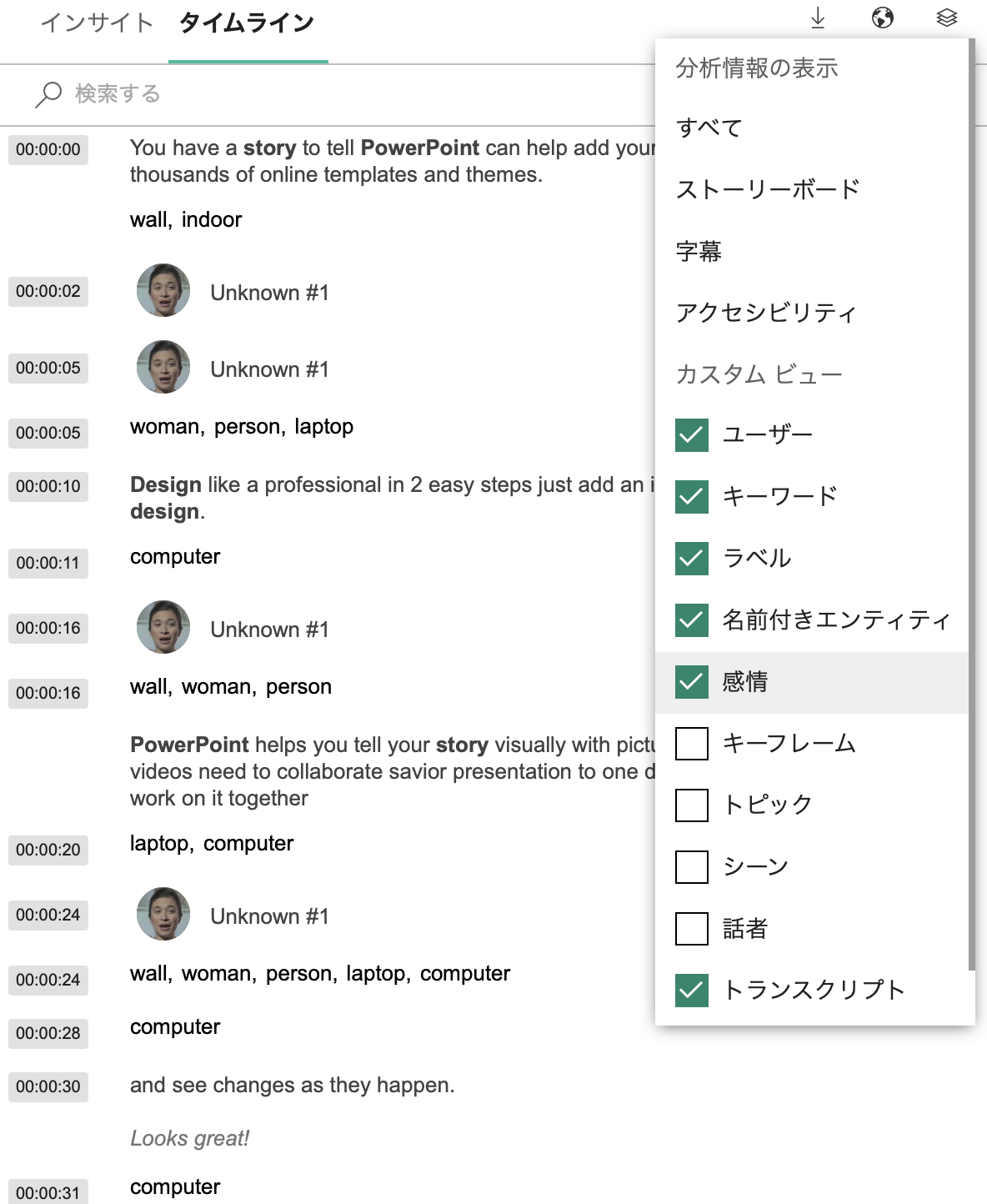
UIの違い 1
Video IndexerはタイムラインというUIがあり、より時間軸を意識した作りとなっています。タイムラインでは下図のようにどんどん情報を追加できます。
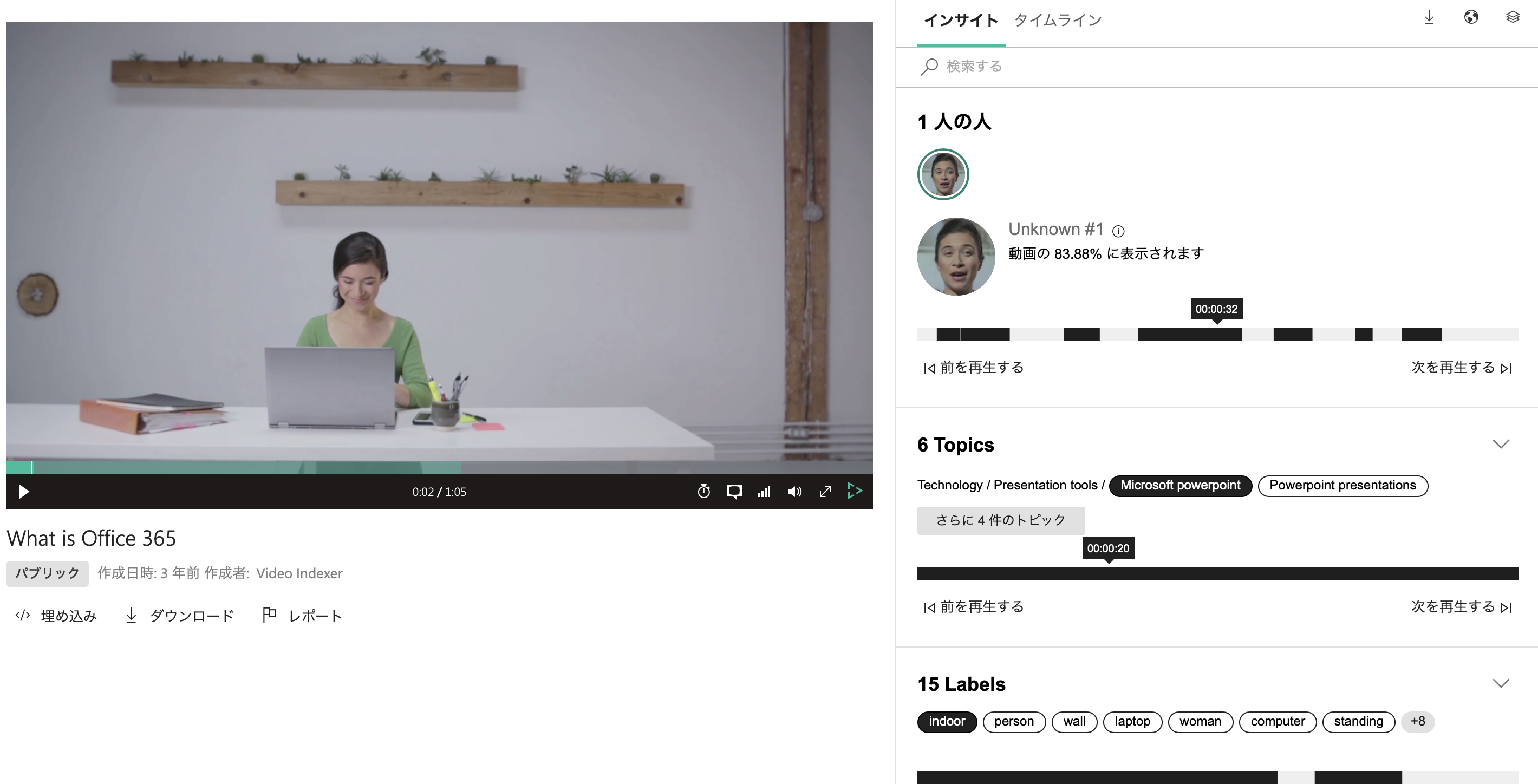
UIの違い 2
プレイヤー部の機能がリッチです。Rekognitionは再生と音声しか制御できませんが、Video Indexerでは再生速度、音声解析した言葉の字幕(背景色なども変更可)、画質設定、全画面、シークサムネイルと機能が揃っています。さらにそれを埋め込みボタンでhtml化してくれました。
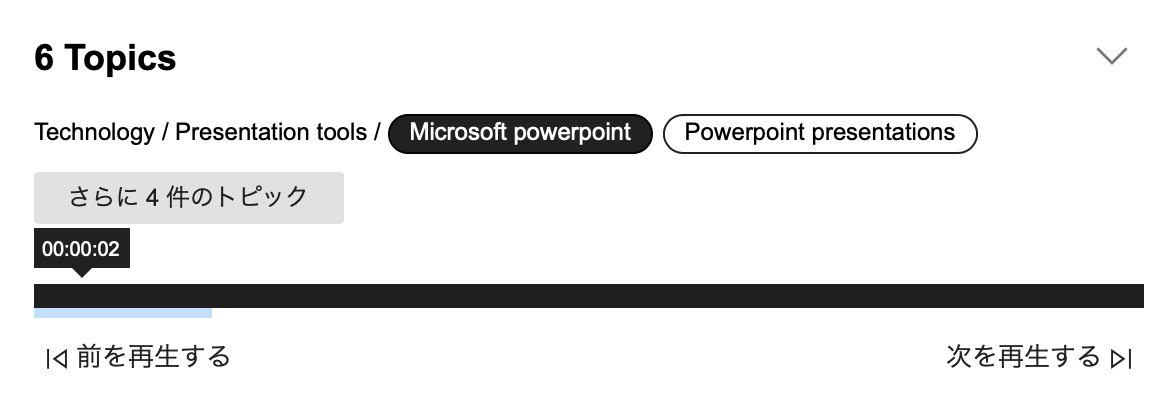
会話内容トピック
会話内容からトピックを抽出してくれるようです。逆に会話がない画像ではトピックがなかったです。日本語の解析はまだまだ精度が悪く、そこからできたトピックも精度が悪そうです。
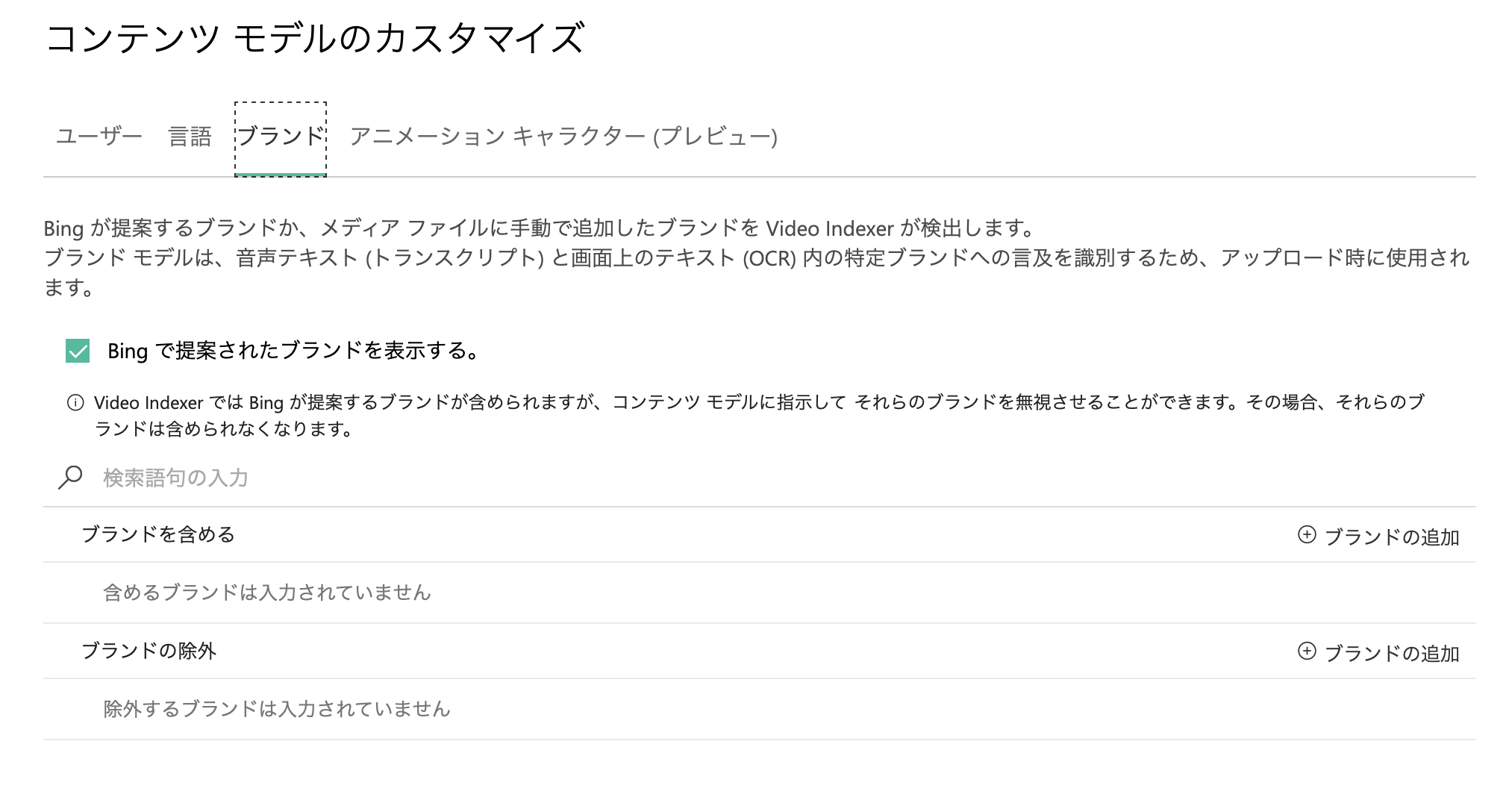
ブランド認識
ブランドを登録しておき、関連リンク等を設定しておけるようです。動画内広告(例えば車のブランドなど)のコンバージョンに影響しそうです。
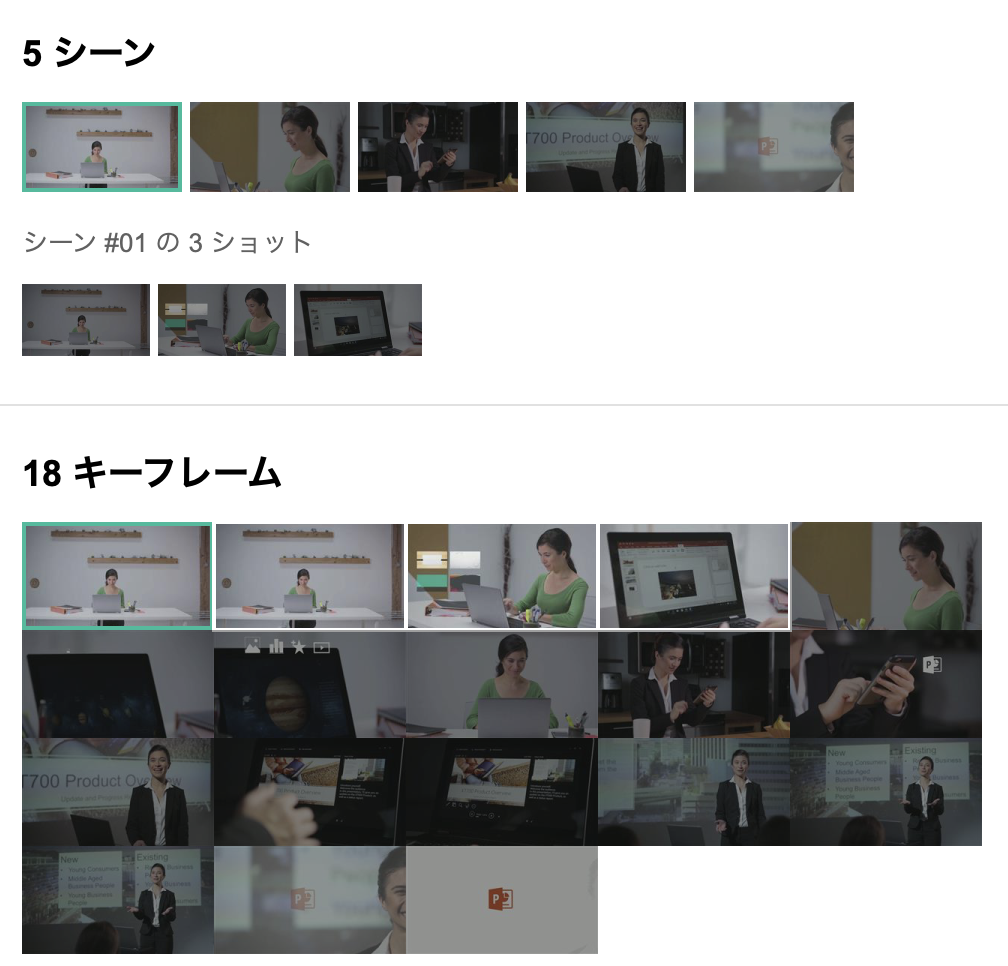
シーン分割
シーン分割はチャプターのように機能します。キーフレームは画面の構成が変更点を切り取ってくれているような動きに見え、シークサムネイルでも利用してる画像のようでした。
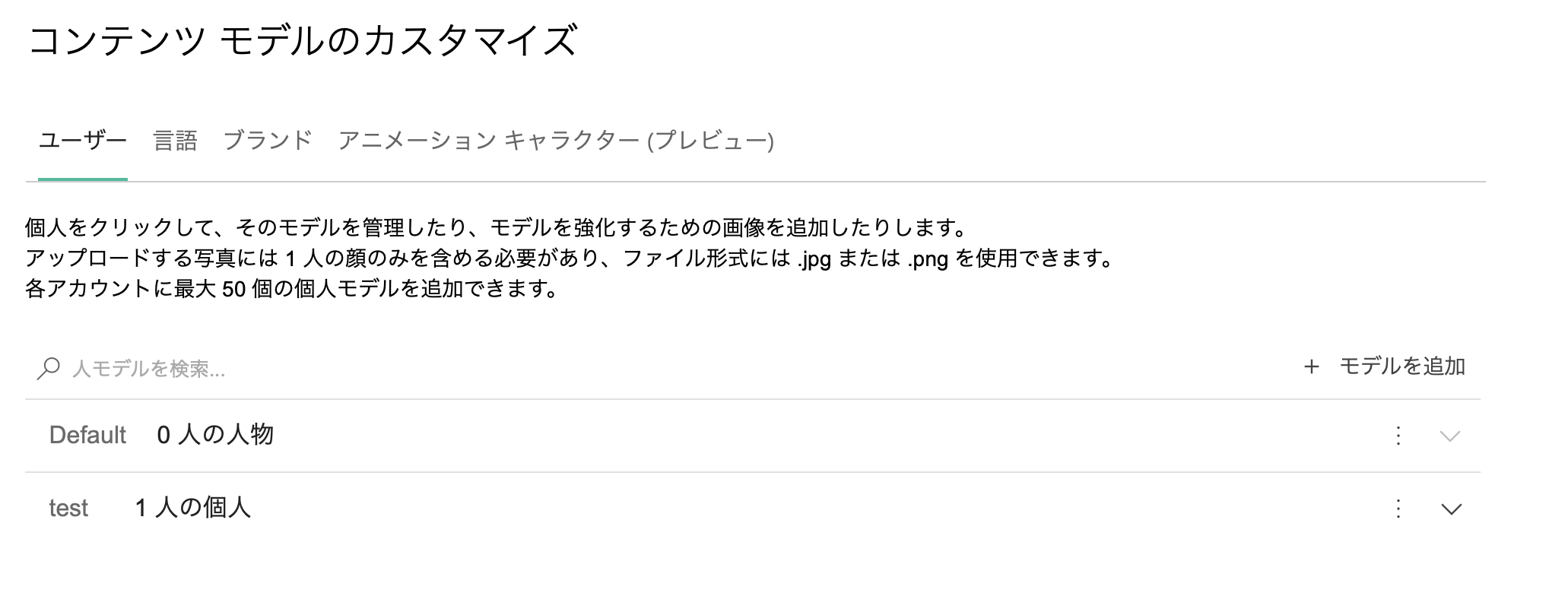
カスタマイズ性 1
ブランド認識も同様ですが、モデルを拡張することが可能なようです。Rekognitionでは拡張性は見当たらなかったので、ML視点で見るとここは大きな違いかもしれません。
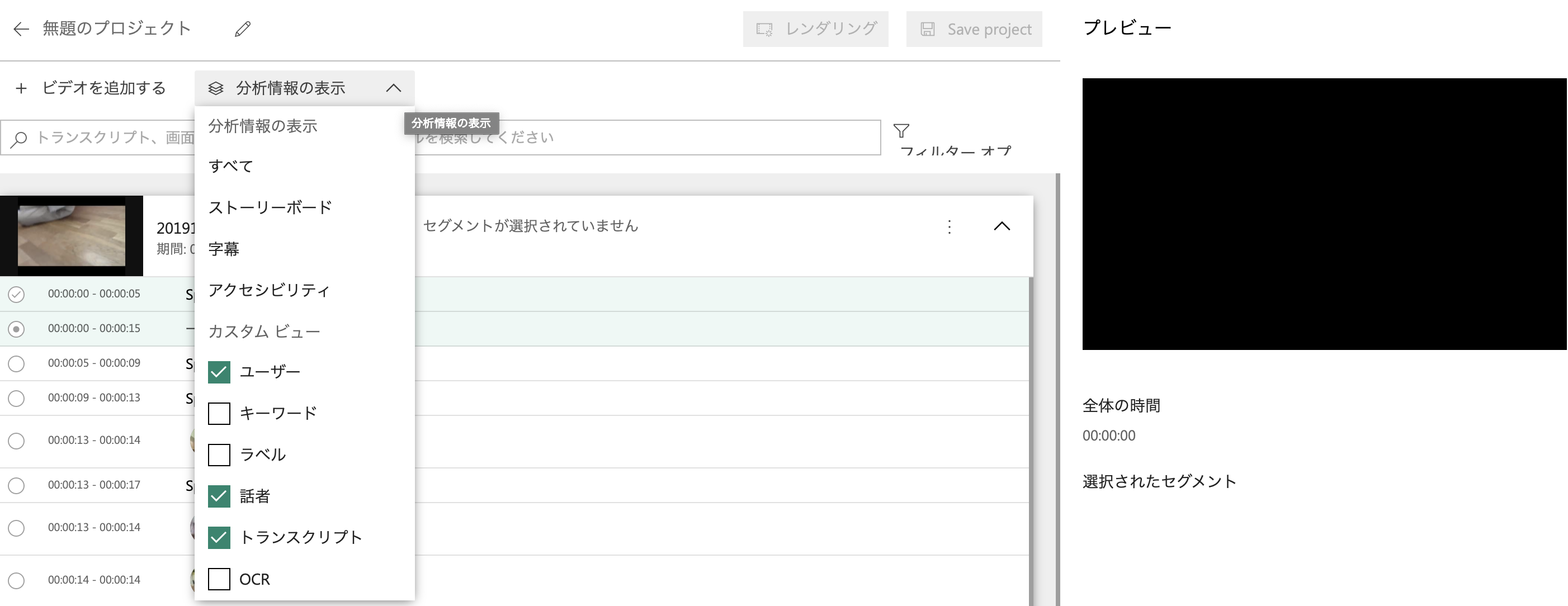
カスタマイズ性 2
おそらく動画のクリッピングができる機能のようです。抽出方法は解析したメタを利用できるようでした。動画編集する場合は必要と思いますが、完パケを配信するサービスでは特段必要性は感じませんでした。
補足情報
解析時間については640x480の1分程の尺の動画を解析するのに6分ほどかかりました。
Rekognitionと異なり、Suggestiveなものはレビュー対象という形で表現されています。怪しい動画はMicrosoft側にレビュー依頼する必要があります。ただし日本語の精度が低いのにつられ、こちらの判定精度も悪いように感じました。

まとめ
Video Indexerの機能を見るとRekognitionは画像解析から端を発する感が強い印象でした。顔の分析/比較機能の有無はそこら辺にありそうです。動画にスコープを絞る場合はVideo Indexerの方が高機能に感じました。