目的
前回の投稿でMLの動画解析ソリューションを調べました。
機械学習関連AWSソリューション簡易まとめ
今回は実際にRekognitionのデモを体験したので、
スクショを貼って具体のイメージが持てる状態にしたいです。
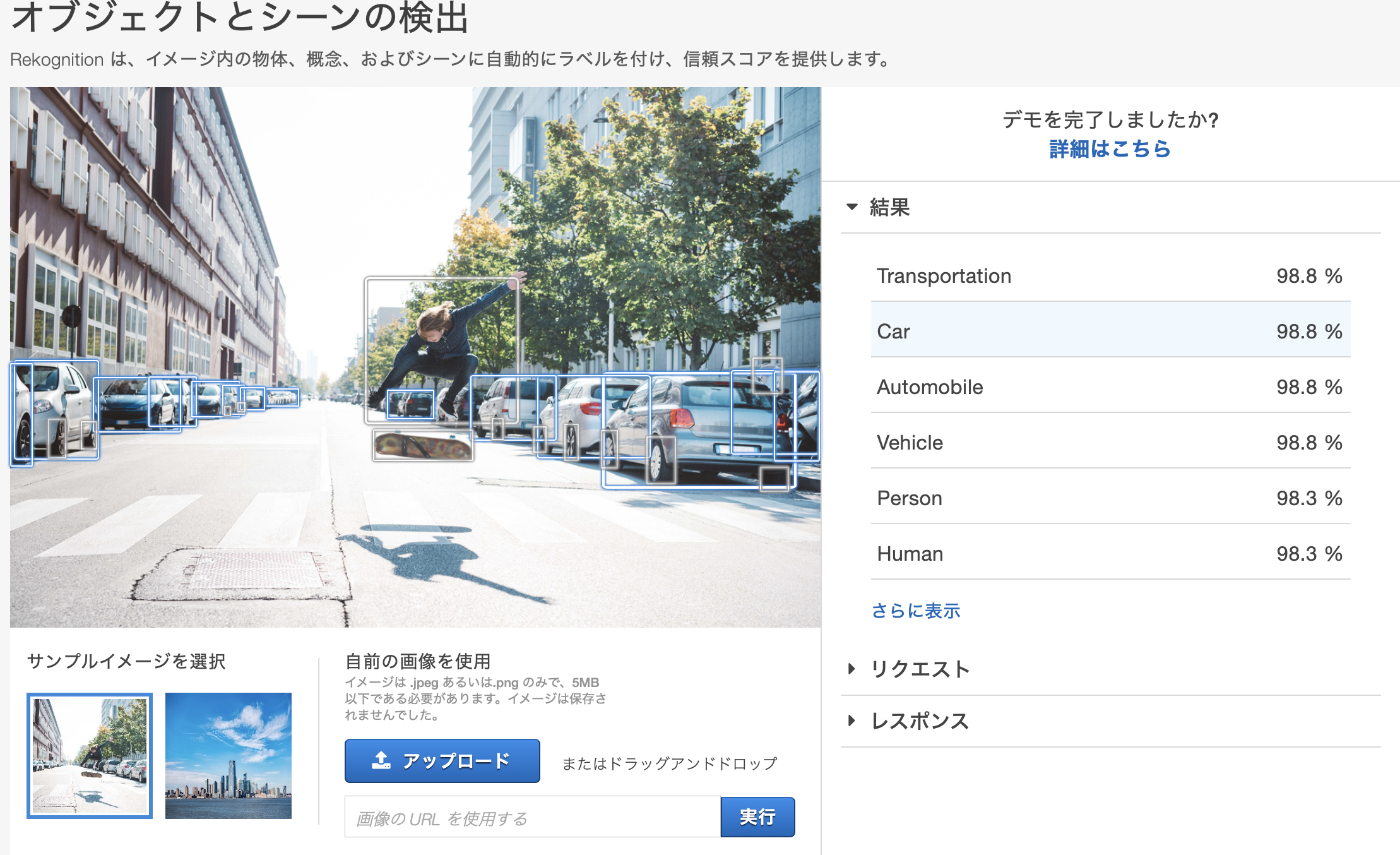
オブジェクトとシーンの検出
画像に現れるオブジェクト検出を行います。自分の画像で解析してみましたが、オブジェクトは汎用的なものが多く精度はデモ画像ほど検出してくれませんでした。動画を検索する際のキーワード抽出等で活用できるかもしれません。
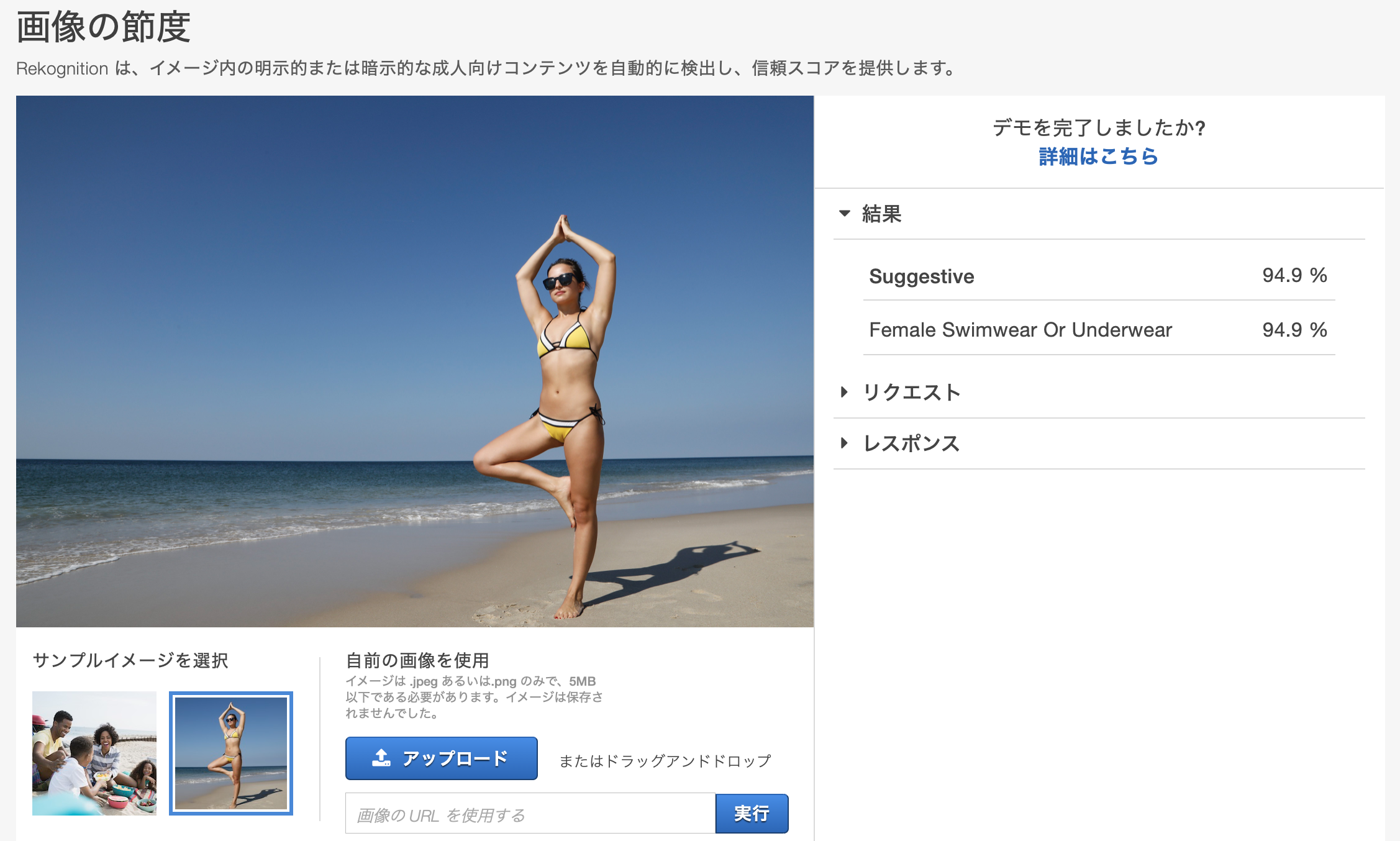
画像の節度
サービスを提供する側にとって、不適切な画像などは検知したい場合があると思います。家族の画像の場合は問題ないですが、水着の女性の画像はSuggestiveと判定されています。この判定がされた場合に映像の検品などのユースケースがあると思います。
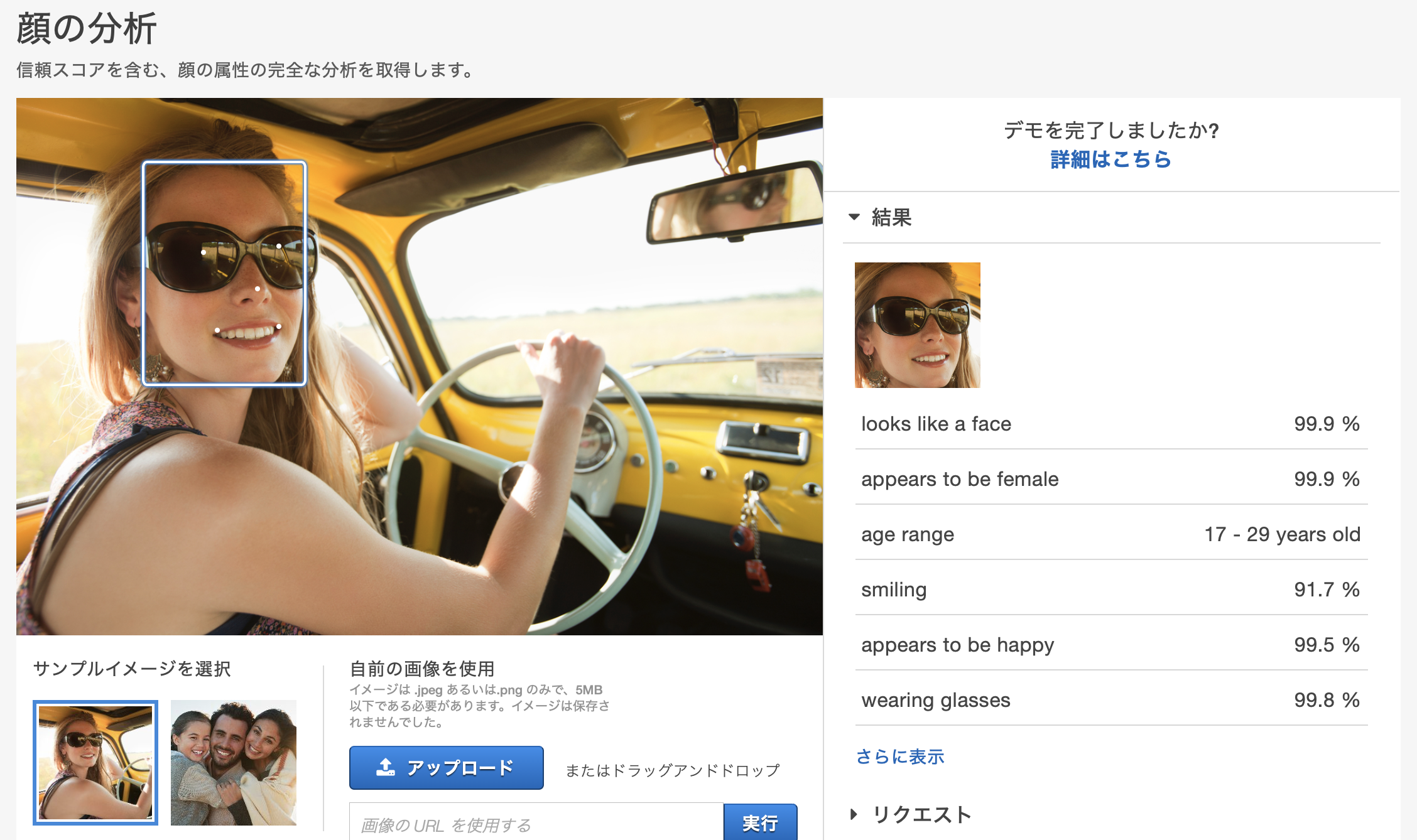
顔の分析
笑っているなど、顔の情報が取得できます。複数人いる場合もそれぞれ検出してくれます。自分の画像で試してもかなりの精度でした(99%の確率で幸せとのこと笑)。動画を検索する際のキーワード抽出等で活用できるかもしれません。
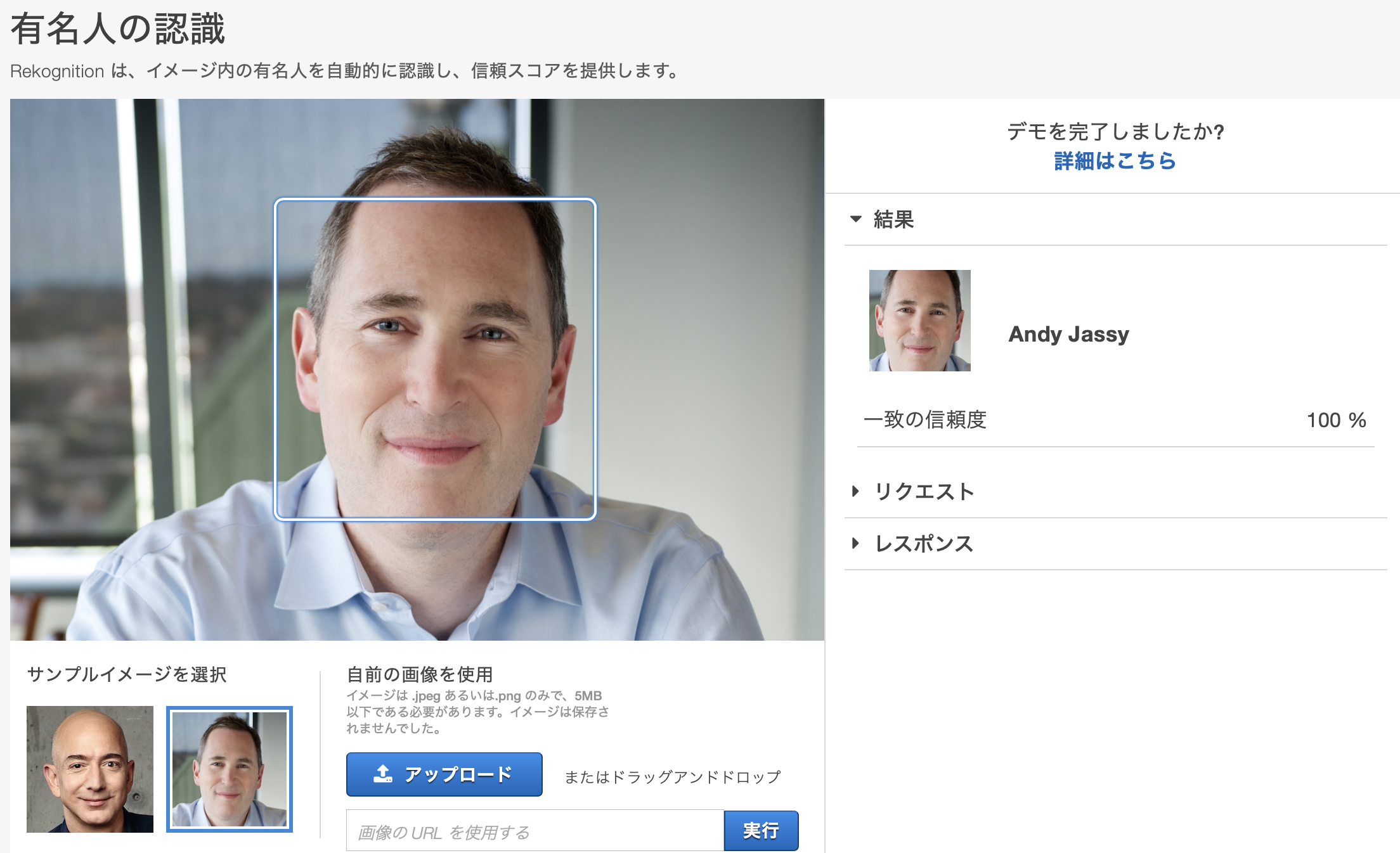
有名人の認識
日本人かつ複数人の有名人が写る画像でもちゃんと判定してくれました(沢尻エリカはiconiqと誤判定された)。たまたま目に止まったbishというバンドメンバーでは判定できませんでした。動画を検索する際のキーワード抽出等で活用できるかもしれません。
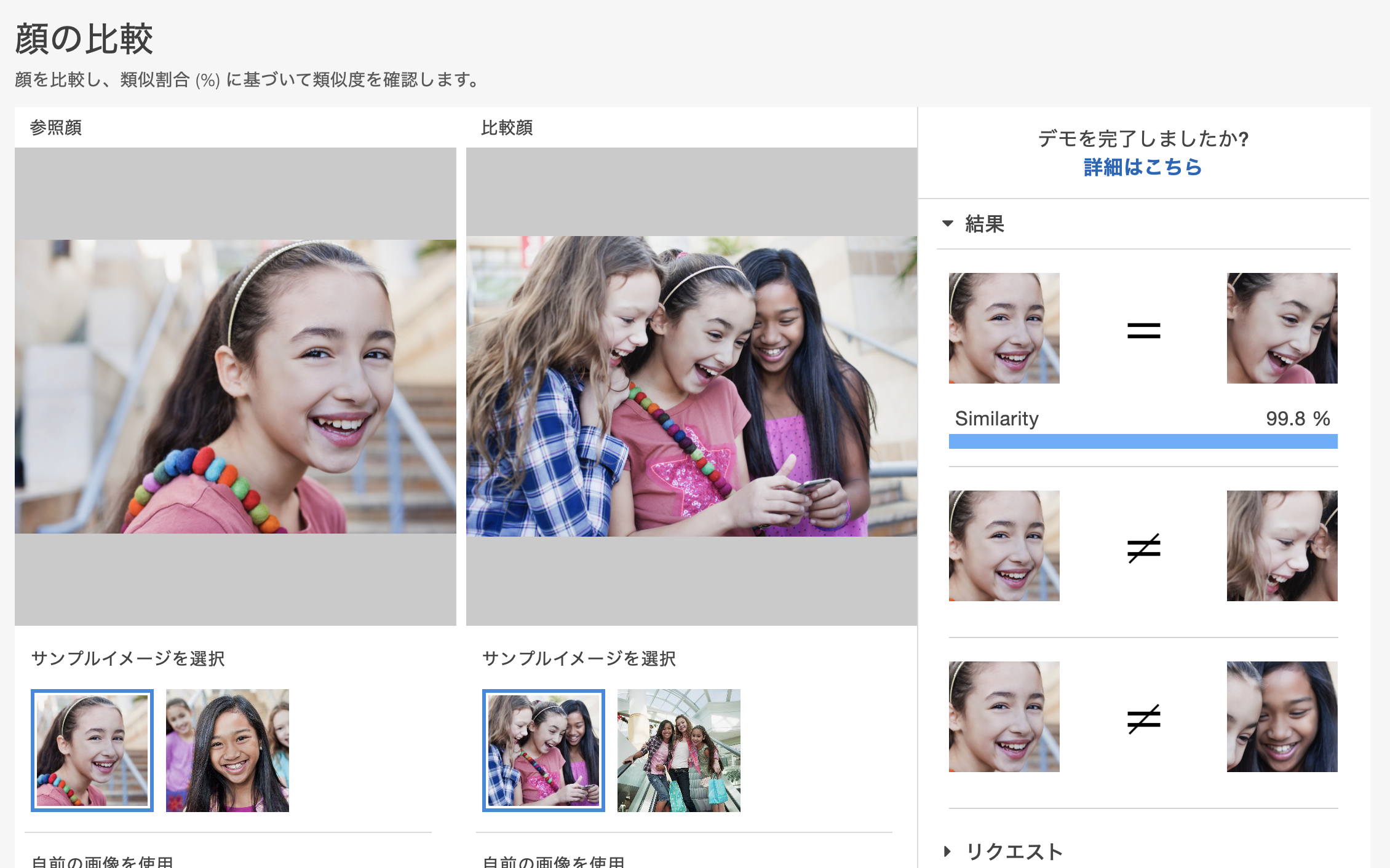
顔の比較
そのままの機能ですが、自分の画像で試してみたところかなりの精度で検出してくれました。動画のグルーピングに活用できそうです。
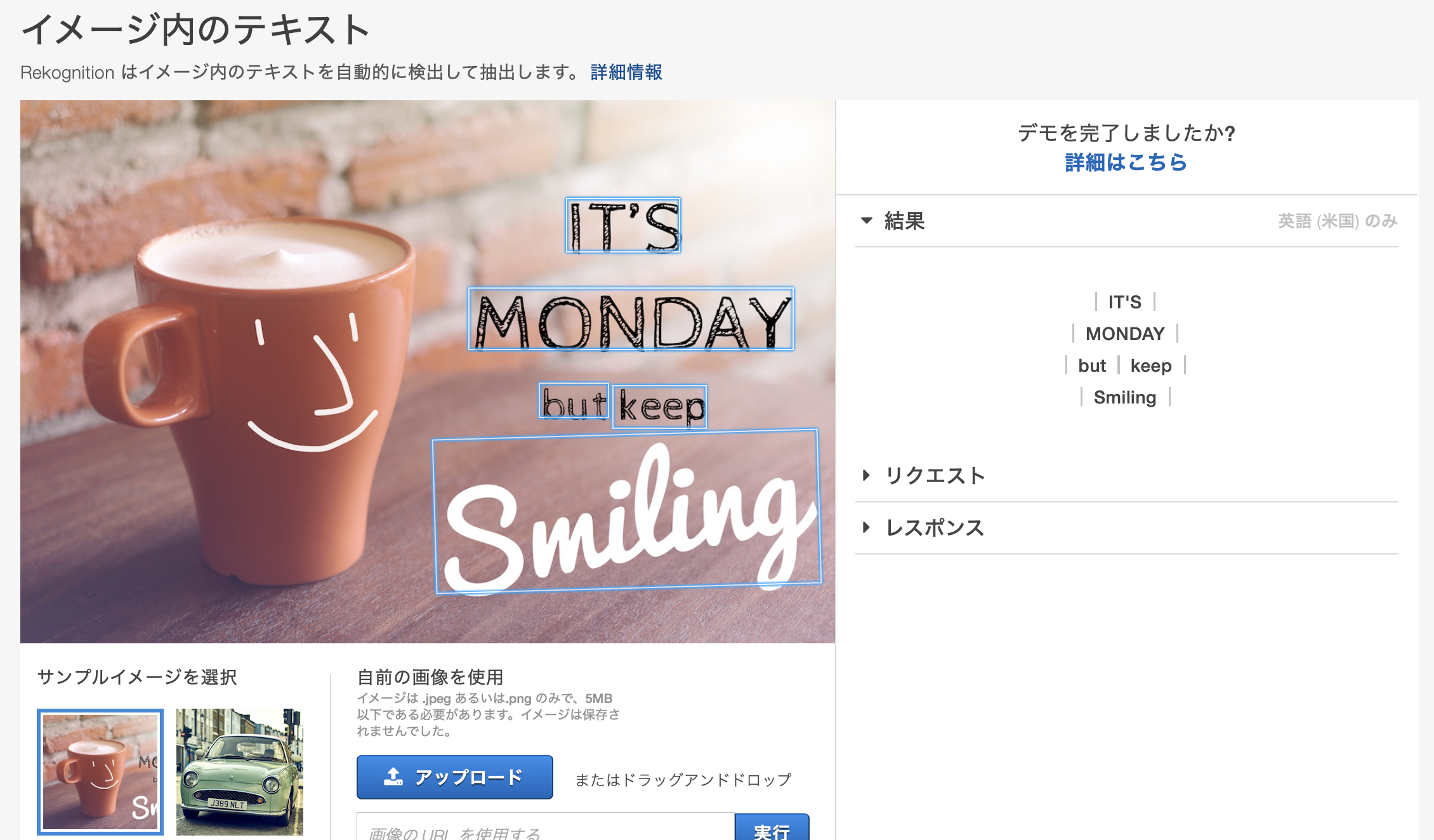
イメージ内のテキスト
いわゆるOCRです。デモのためなのかわかりませんが、日本語は対応してないようでした。
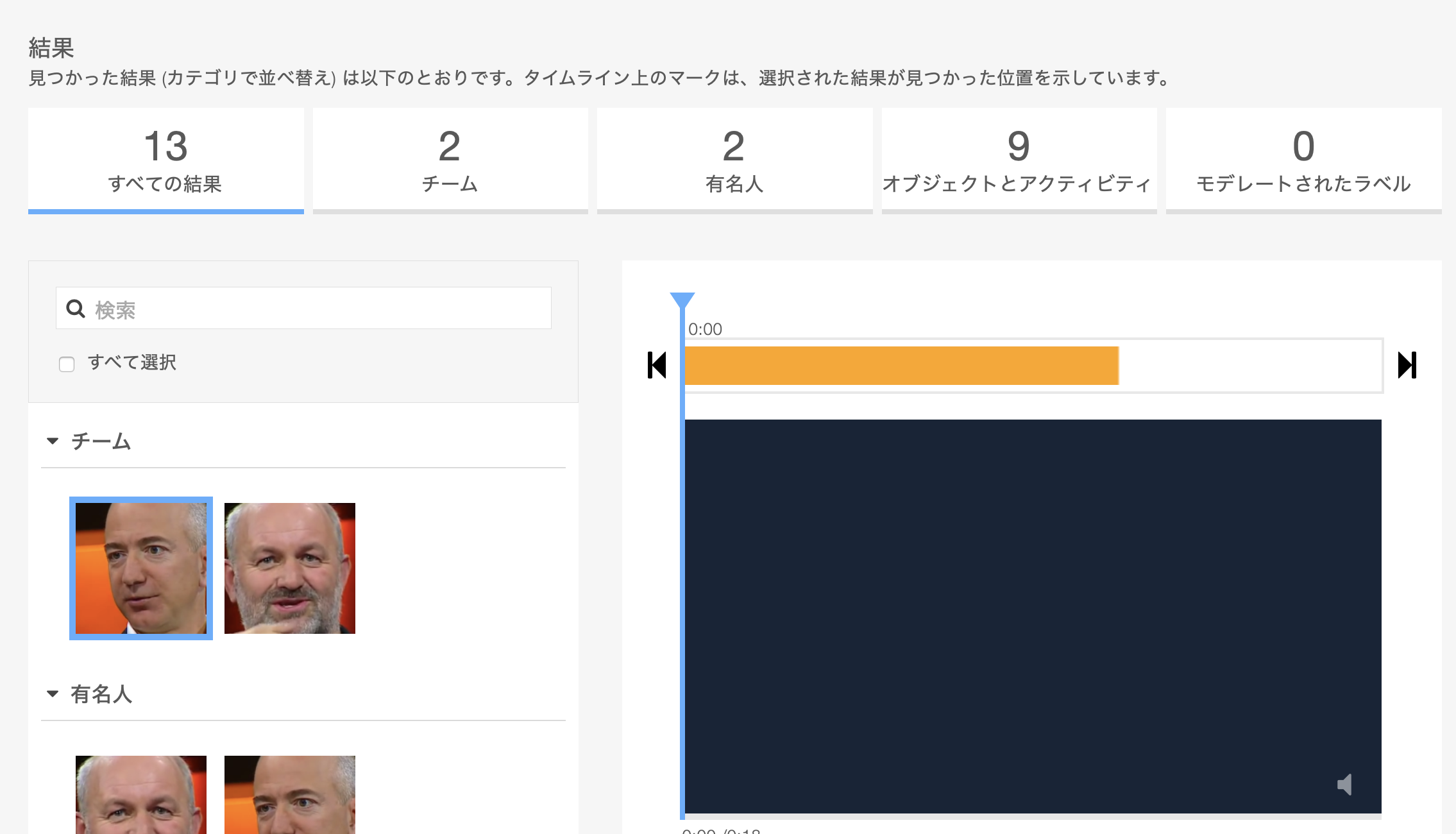
ビデオ分析
ビデオ分析では今まま説明した機能が入っていました。動画のプレビューにあるオレンジの帯は選択した人物やオブジェクトの出現時間となります。利用してみましたが、オブジェクトの出現時間の精度がいまいちのようでした。
まとめ
Rekognitionでは人物検出など既に実用できるレベルでした。懸念があるのはオブジェクト検出です。そもそもオブジェクト検出は膨大な種類から特定する難しい問題だとは思います。そのため用途を限定する必要があると感じました。Rekognitionの概要は掴めたので、次はAzureのVideo indexerを利用してみたいと思います。