こんにちは。わいけいです。
今回はローカル環境で DB に対して発行されているスロークエリを発見する手順について書いていきたいと思います。
アプリケーションが育ってくると、サーバーのパフォーマンスのボトルネックになりやすいのが DB です。
クラウドが浸透した現在では、アプリケーションサーバーの方はお金さえ払えば比較的自由に(水平・垂直に)スケーリングできます。
これに対して、RDB の方は相対的にスケーリングが難しい傾向にあります。(クラウドのパワーによって金でゴリ押し可能な面が増えてきてはいますが)
そういった背景から、極力非効率な SQL は投げたくないものです。
とはいえ、現実的には例えば以下の理由によって DB にスロークエリを投げてしまっていることは多々あります。
- ORM が裏側で非効率な SQL を発行していた
- インデックスを貼り忘れた
- 可読性とのトレードオフで、あえて SQL の最適化を断念した
現場の開発方針として、「ある程度まではSQLが遅くても許容する」というケースも多いと思います。
(私もどちらかというとそういう立場です。)
が、それでも「ある程度」以上に遅いSQLを書いている場合は早めに(できればデプロイする前に)気づきたいものです。
そこで今回はローカルのpostgresコンテナのパフォーマンスのログを記録し、それをブラウザで確認する手順を備忘録も兼ねてまとめておきます。
なお、今回は負荷試験用のツール等は使っておらず、あくまでもクエリログを残すための設定とそのデータの視覚化の部分に力点を置いています。
やることを大まかにまとめると以下のようになります。
- スロークエリのログを吐き出すようにPostgresQLコンテナを設定
- テスト用のSQLを実行
- ログの視覚化ツールで確認
では早速とりかかっていきましょう。
私のSNSアカウント等です。
今後もPython・LLM・Go・Web開発などのトピックについて発信していくのでフォローしていただけると喜びます。
-
X: わいけい
-
LinkedIn: ykimura517
-
Github: ykimura517
Zenn版:
https://zenn.dev/spiralai/articles/65db8a78ea31d4
環境構築
まず今回は、作業ディレクトリに下記のようなファイル群を用意しました。
.
├── docker-compose.yml
├── entrypoint.sh
└── postgresql.conf
0 directories, 3 files
それぞれの中身は下記の通りです。
services:
db:
image: postgres:15-alpine
container_name: "my_db"
restart: always
volumes:
- ./postgres-data:/var/lib/postgresql/data # 中身のデータは取り敢えずホストのその場にマウント
- ./postgres-logs:/var/log/postgresql # ログフォルダをホストにマウント
- ./postgresql.conf:/etc/postgresql/postgresql.conf:ro
- ./entrypoint.sh:/usr/local/bin/entrypoint.sh
environment:
- POSTGRES_DB=db
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=password
ports:
- 5432:5432
entrypoint: ["/usr/local/bin/entrypoint.sh"]
adminer:
image: adminer
restart: always
ports:
- 8081:8080
普段私はデータベース用のコンテナはalpineベースのものを使うことが多いのですが、ここでもそうしました。
やはりアプリケーション用のコンテナよりも独自にインストールしたいモジュールなどが少ないので、個人的には軽量なalpineでいいだろうと思っています。
(しかし今回のようにpostgresの設定を多少なりともカスタマイズしたい時は、alpineであるがゆえのハマりポイントも少々あったかもしれません。)
また、データ投入の時などにブラウザ経由のGUIでSQLコマンドを実行したかったので、adminerコンテナも使用しました。
これによりpostgresコンテナに入らなくても、ブラウザ経由で諸々のデータ投入やデータの確認が可能になります。
#!/bin/bash
# entrypoint.sh
# ログディレクトリの所有者をpostgresユーザーに設定
chown -R postgres:postgres /var/log/postgresql
# PostgreSQLを通常通り起動(設定ファイル指定)
exec docker-entrypoint.sh postgres -c config_file=/etc/postgresql/postgresql.conf
postgresコンテナで最初に実行されるスクリプトです。
log_min_duration_statement = 1 # 1ミリ秒以上のクエリをログに記録
log_directory = '/var/log/postgresql' # ログのディレクトリ
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' # ログファイル名のフォーマット
logging_collector = on # ロギングコレクタを有効にする
listen_addresses = '*' # 他コンテナなどから接続できるようにするため追加。あくまでローカル開発のみなので全許可
こちらがpostgresコンテナに反映させる設定ファイルです。
今回は1ミリ秒以上のクエリを全てログに記録するようにしていますが、必要に応じて500ミリ秒などに書き換えるといいでしょう。
コンテナ起動
準備が整ったので各コンテナを起動させていきます。
docker compose up
postgres-data と postgres-logs という2つのディレクトリが生成されるはずです。
そして、もろもろの設定がうまくいっていれば postgres-logs ディレクトリにSQLのログが吐き出されていくはずです。
データ投入
さて次は実際にこのデータベースにデータを投入していきましょう。
ブラウザで localhost:8081 にアクセスして、docker-compose.yml で設定した認証情報を入力してデータベースを表示します。
ログインできたら左メニューの「SQLコマンド」から下記のSQLを実行してダミーデータを投入します。
-- テーブルの作成
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
department VARCHAR(50),
salary INTEGER
);
-- データの投入(100000行を想定)
INSERT INTO employees (name, department, salary)
SELECT
'Employee ' || generate_series, -- 名前
(ARRAY['Sales', 'Engineering', 'HR', 'Marketing'])[ceil(random() * 4)], -- 部署
(round(random() * 1000000) + 50000)::INTEGER -- 給与
FROM generate_series(1, 100000);
これで10万行分の架空の従業員データが作成されます。
次にこのテーブルに対して適当に遅そうなクエリを投げておきましょう。
-- 非効率的な集計クエリ
SELECT department, AVG(salary) AS average_salary
FROM employees
GROUP BY department;
これらのSQLの実行ログはホストマシンにマウントされているファイルに書き込まれているはずです。
これ以降は書き込まれたログ情報からスロークエリの情報を取得します。
ログ確認
まず、postgres-logs 配下にログファイルが存在していることを確認してください。
(存在しなければコンテナ側からこのファイルにログを書き込むことに失敗しています。権限などのエラーログが表示されていないかなどを確認してください)
このログファイルは人の目で見てもごちゃごちゃしていて情報が掴みにくいです。
そこでPostgreSQLのログファイルを解析するのに特化しているツールを使います。
今回は pgbadger を使います。pgbadgerを使えばログの統計情報や具体的にどのSQLに時間がかかっているかといった情報をHTMLファイルに書き出しブラウザで視覚的に確認することが可能です。
pgbadger がインストールされてない場合はOSなどに応じたインストール方法をググってインストールしてください。
私のUbuntu環境では
sudo apt install pgbadger
でインストールすることができました。
ログ情報表示
さて pgbadger のインストールができたらプロジェクトのルートディレクトリで下記のコマンドを実行します。
pgbadger -f stderr -o out.html postgres-logs/postgresql-xxxxxxxxxxxxxxxxx.log
*ログファイルの名前はそれぞれで吐き出されたログファイルに応じて適宜書き換えてください。
成功すると out.html というファイルが吐き出されるのでこれをブラウザで開いてみましょう。

図のようにいい感じにSQLクエリに関する統計情報が表示されていますね!
今回はスロークエリを特定したかったので「Top」メニューから「Slowest individual queries」を選択しました。
すると下画像のように、時間がかかったSQLがランキング形式で表示されています。
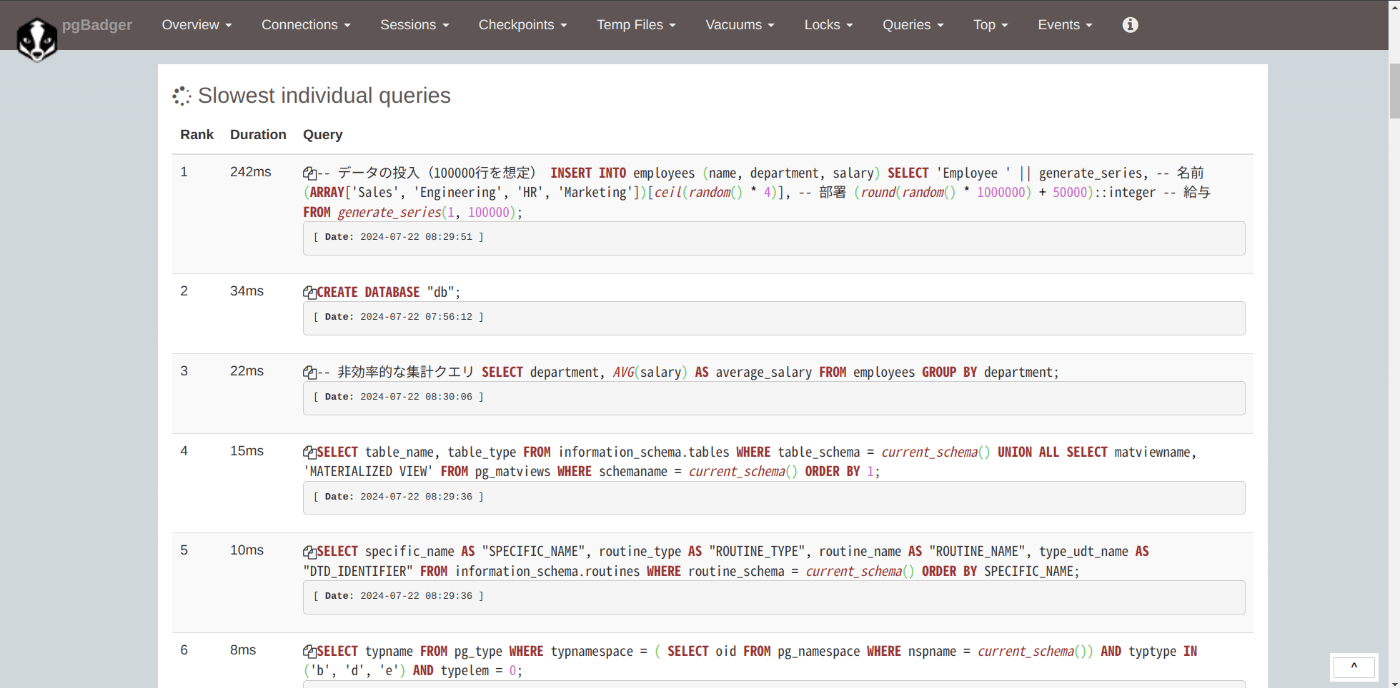
今回は10万行のデータの投入に240ms程度かかっておりこれが計測中で最も遅かったようですね。
先ほど非効率な集計クエリとして使用したSELECT文も上位にランクインしていますね(とはいえこの所要時間が22msなので現場で致命的にUXを損ねるようなものかと言うと微妙ではあります)。
今回はアプリケーションコンテナは省略していました。
が、実際にはそれぞれの環境でアプリケーションコンテナも起動した状態で、そこからパフォーマンス的に重そうな操作を色々とやってみましょう。
発行されたSQLログから、ボトルネックを発見できるかもしれません。
まとめ
今回の記事では、ローカル環境に用意したPostgreSQLのコンテナでスロークエリを視覚化する手順の一例をまとめました。
ローカル開発時に、アプリケーションを起動させてその間ずっとログを取得しておくと意外なボトルネックが発見できるかもしれません。
私からは以上です。
※ローカル環境と本番環境では、データ量やインフラ的な条件が厳密に同じではないはずです。本番環境の監視も忘れないようにしましょう(自戒)。
今後もWeb開発やLLMに関する発信を行っていく予定なので今回の記事が少しでも役立ったという方は、私のSNSなどをフォローしていただけると大変喜びます。
-
X: わいけい
-
LinkedIn: ykimura517
-
Github: ykimura517