目次
- はじめに
- Web サーバーの構築
- apache の構築
-アクセススクリプトの作成 - rsyslog の設定
- apache の構築
- Syslog サーバーの構築
- Elastic Stack の構築
- ログファイルを取得するスクリプトの作成
- ssh の設定
- crontab の設定
- java のインストール
- Logstash のインストール
- Elasticsearch のインストール
- Kibana のインストール
- Logstash の簡単な設定
- Elasticsearch の簡単な設定
- Kibana の簡単な設定
- おわりに
- 課題
- 今後の予定
はじめに
仕事でElasticsearch を使う可能性があり,冬休みを利用して調査したり,試験的に構築して触ってみることにした.その経験を仕事に活かせるように,またどこでも似たような環境をすぐさま構築できるようにこのようにドキュメントにアウトプットすることにした.
構築した環境は以下の通り.断続的にログが転送されてくる環境にしたかったので,Web サーバーにアクセスするスクリプトを作成してそのログをSyslog サーバーに転送させ,そのログファイルをscp でElastic Stack に取り込む形にした.なぜ一見面倒そうな設計にしたのかというと,何となく本番環境がこのような形になりそうだと踏んだからである.
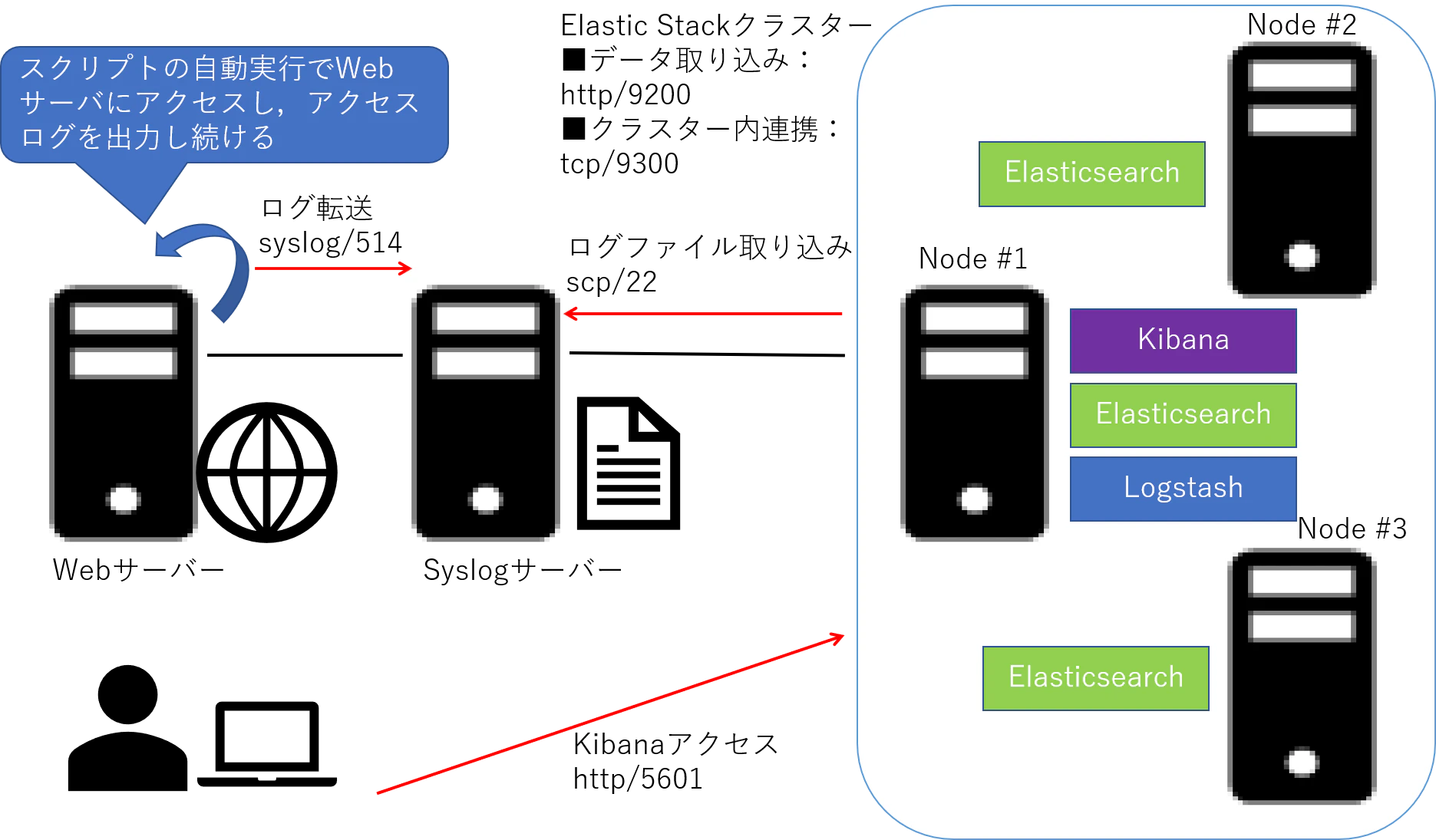
Elastic Stack に関しても,障害が発生した場合でも稼働を維持し続ける設計が必要であるため,ノード3台でクラスター構築を組んでいる.
Web サーバーの構築
最初に,Web サーバーを用意し,そのアクセスログをsyslog にてSyslog サーバーに転送するインスタンスを構築する.
apache の構築
apache をインストールする.
# dnf -y install httpd
apache の自動実行をON にし,起動させる.
# systemctl enable httpd
# systemctl start httpd
Cent OS 8 から?IPアドレス指定だけでアクセスしようとすると403がレスポンスされる.それだと正常にアクセスできたかどうかわからなかったので,ドキュメントルート直下に以下のhtml ファイルを作成して配置した.curl でアクセスするとtest とだけレスポンスされる.
test
最後に,ログ転送関連の設定を行う.
アクセススクリプトの作成
以下のスクリプトを作成し,アクセスログを定期的に発生させるようにした.
最初はsleep コマンドはなかったが,ないとログが多すぎるのでログ量を調整することにした.
# !/bin/bash
while [ true ]
do
curl 【Web サーバーのIPアドレス】/test.html
sleep 60
done
rsyslog の設定
rsyslog により,apache のアクセスログをSyslog サーバーに転送するため,apache の設定ファイルに以下を追記する.ユーザー定義のlocal0 を利用する.
CustomLog "|/usr/bin/logger -p local0.info -t httpd_access" combined
次に,rsyslog でSyslog サーバーに転送の設定を記述する.今回は,UDP でログ転送をする.
local0.* @【Syslog サーバーのIPアドレス】:514
Syslog サーバーの構築
Syslog サーバーでは,rsyslog に受信の設定を記述する.
送信側がlocal0 でログ転送するので,そのファシリティで受信したログの保存先を指定する.
$ModLoad imudp
$UDPServerRun 514
...
local0.* -/var/log/test/access.log
Elastic Stack の構築
Elastic Stack の役割は,Syslog サーバーに保存されているログファイルを取得してLogstash でパース,Elasticsearch に取り込み,Kibana で可視化したり,csv ファイルに出力させてSQL サーバーに取りこむことである.本ドキュメントでは,Elastic Stackのクラスターを構築し,Elasticsearchが1台ダウンしてしまってもログの蓄積などElasticsearch が担う役割が全うできるかを確認するため,データベースサーバーへの取り込みまでは行わず,csv ファイルの出力までを実施することにする.
ログファイルを取得するスクリプトの作成
Syslog サーバーに保存されているapache のアクセスログファイルを取得するため,以下のスクリプトを作成する.このスクリプトをcrontab により定期的に自動実行させる.
# !/bin/bash
scp -i /home/elastic/.ssh/id_rsa root@【Syslog サーバーのIPアドレス】:/var/log/test/access.log /var/log/test
ssh の設定
scp によりファイルを取得するため,まずはssh に使用する公開鍵と秘密鍵のペアを作成する.
# ssh-keygen -t rsa
パスフレーズなどは設定せず,すべての質問はEnter を入力して進む.
次に,公開鍵をSyslog サーバーに登録する.
# scp root@【Elastic Stack のIPアドレス】:/home/elastic/id_rsa.pub /root/authorized_keys
これで公開鍵が登録できたので,次は設定ファイルより公開鍵認証でログインできるようにする.
PubkeyAuthentication yes
今回は設定実施しなかったが,インターネット公開系のシステムであったりすると,root ログインやパスワード認証を無効にする.
PermitRootLogin no #root ログインを無効
PasswordAuthentication no #パスワード認証を無効
crontab の設定
定期的にログファイルをSyslog サーバーから取得するため,crontab の設定を行う.以下のファイルを作成する.
# 分 時 月 日 曜日 ユーザ名 コマンド
*/5 * * * * root /home/elastic/log_copy.sh
このファイルにより,5分おきにlog_copy.sh が実行され,Syslog サーバーからapache のアクセスログファイルがElastic Stack のローカルにコピーされる.
java のインストール
Logstash やElasticsearch のインストールに必要なjava をインストールする.
Elastic Stack はUbuntu 18.04 で構築しているため,Web サーバーやSyslog サーバーとはコマンドが異なる.
# apt install java-1.8.0-openjdk
Logstash のインストール
Logstash をインストールする.インストールするためのファイルは,以下のページからダウンロードする.
https://www.elastic.co/jp/downloads/
今回は,「logstash-7.4.0.deb」をインストールする.
# dpkg -i logstash-7.4.0.deb
インストールが完了したら,サービスを起動する.
# service logstash start
Elasticsearch のインストール
今回は,「elasticsearch-7.4.0-amd64.deb」をインストールする.ファイルはLogstash と同じページからダウンロードした.
# dpkg -i elasticsearch-7.4.0-amd64.deb
インストールが完了したら,サービスを起動する.
# service elasticsearch start
Kibana のインストール
今回は,「kibana-7.4.0-amd64.deb」をインストールする.ファイルはLogstash と同じページからダウンロードした.
# dpkg -i kibana-7.4.0-amd64.deb
インストールが完了したら,サービスを起動する.
# service kibana start
Logstash の簡単な設定
取り込むログファイルに関しての設定を行う.Logstash はinput,filter,output プラグインが存在し,入出力およびログファイルのパースなどといった処理内容を記述する.今回は,以下のファイルを作成した.
input {
file {
mode => "tail"
path => ["/var/log/test/access.log"]
sincedb_path => "/var/log/test/pointer"
start_position => "beginning"
}
}
filter {
grok {
match => {
"message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{HOSTNAME:source} %{USERNAME}\[%{INT}\]: %{IPV4:destination} - - \[%{HTTPDATE:access_time}\] %{GREEDYDATA:message}"
remove_filed => ["message"]
}
}
}
output {
# debug
# stdout {
# codec => rubydebug
# }
file {
path => ["/var/log/tanium/result_access.log"]
}
elasticsearch {
hosts => ["【node-1のIPアドレス】:9200", "【node-2のIPアドレス】:9200", "【node-3のIPアドレス】:9200"]
index => "test"
}
}
上記設定ファイルで,syslog 経由で送信されてくるapache のログファイルをある程度パースできる.
設定が正しくできているかはlogstash を設定ファイルを指定して実行させることで確認できる.その前に,以下の文を追記しておき,パスを通しておく.
export PATH="$PATH:/usr/share/logstash/bin"
以下のコマンドを実行し,結果を確認する.
# logstash -r -f "/etc/logstash/conf.d/access.conf"
以下のような形で,json 形式でログが取り込まれていればOK.
{
"message": [
"Jan 3 01:36:13 localhost httpd_access[8378]: 【WebサーバーのIPアドレス】 - - [03/Jan/2020:01:36:13 -0500] \"GET /test.html HTTP/1.1\" 200 5 \"-\" \"curl/7.61.1\"",
"\"GET /test.html HTTP/1.1\" 200 5 \"-\" \"curl/7.61.1\""
],
"syslog_timestamp": "Jan 3 01:36:13",
"destination": "【WebサーバーのIPアドレス】",
"path": "/var/log/test/access.log",
"access_time": "03/Jan/2020:01:36:13 -0500",
"@timestamp": "2020-01-03T13:38:53.721Z",
"host": "elastic1",
"@version": "1",
"source": "localhost"
}
これで,所定のログファイルを取り込んで,パースして,結果を出力できるのが確認できたので,問題ないとおもっていたが,Logstash サービスの起動だけではログファイルを取り込んでくれない問題が発生した.
上記のように,実行ファイルを直接実行させる形では問題なく動作しているため,conf ファイルの設定ミスではなさそうだが,原因がわからない...
今回の検証では実行ファイルの直接実行でも差し支えないためそのまま進めることにした.
Elasticsearch の簡単な設定
Elasticsearch は,3台でクラスターを構築し,それぞれデータノードおよびマスター候補ノードとして扱うよう設定する.以下の設定ファイルの記述は,構築に必要なため追記/修正したものを抜粋した.
cluster.name: exam-cluster
node.name: node-1 #node-2,node-3とnode ごとに名前を変える
network.host: 0.0.0.0
http.port: 9200
transport.host: 【node のIPアドレス】 #node-2,node-3とnode ごとに値を変える
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["【node1 のIPアドレス】", "【node2 のIPアドレス】", "【node3 のIPアドレス】"]
これで,クラスターが構築できたと思ったが,他のノードが表示されないという問題が発生した.
クラスターのノードを確認するには以下のコマンドを実行する.
# curl http://【node のIPアドレス】:9200/_cat/nodes
1台しかノードが表示されていないことが確認できる.
【node のIPアドレス】 11 84 9 0.10 0.13 0.11 dilm * 【node 名】
クラスターの状態確認は以下のコマンドを実施する.
# curl --ipv4 http://【node のIPアドレス】:9200/_cluster/health?pretty
実行すると,ステータスがyellow となっており,ノードの数も1台でクラスターが組まれていないことが分かる.
{
"cluster_name" : "exam-cluster",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 4,
"active_shards" : 4,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 1,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 80.0
}
一番やってみたかったクラスター構築が実施できておらず,ショック...
なぜ構築されていないのか?原因が不明なため今後の課題にします.
一応,以下のコマンドを実行してポートを見てみると,他のノードと連携しているようには見えた.
# lsof -i:9300
Kibana の簡単な設定
Kibana は今回設定は実施しなかったが,要件としてアカウントごとの権限管理が必要になりそうなので,その設定を実施していく予定である.その設定が完了次第,本記事を更新する.
csvファイルの出力
curl をスクリプトで自動実行させ,Elasticsearch のAPI にアクセスして検索結果を出力する予定である.この部分も,完了次第記事を更新する.
おわりに
Elastic Stack の設計および構築を実施した.また,その前段としてのログを出力する機能を構築した.
課題として,事象に挙げる4点が残ったが,Elastic Stack の理解が少し進んだ.
今後は,課題の解消およびおそらく運用を始めることで様々な問題が発生するので,少しでもElastic Stack の理解を進めていきたい.(特にElasticsearch のAPI 活用)
課題
環境を構築,検証している中で以下の4点が課題となった.
-
Logstash がサービス起動しただけでは/etc/logstash/conf.d/ 配下のconf ファイルを読み込まず,ログが取り込まれない (実行ファイルで指定した場合はちゃんと動作する)
-
Elasticsearch でクラスタが構築できない (9300ポートで待ち受けていないため,どのノードからも1台しかノードが確認できず,ステータスがyellow である)
-
Kibana のアカウント権限管理の設定 (未トライ)
-
csv ファイルの出力方法 (未トライ)
今後の予定
上記の課題を解消するとともに,本番環境の構築およびElasticsearch のAPI 利用により所望のログを出力する方法を調べてSQL サーバーに取り込む.