はじめに
最近csvファイルのデータをグラフにすることをやる必要が出たが,そこでみょん※なcsv ファイルに出会ってプロットするのに苦労したので,その苦労をまとめておく.
なお,言語はPython を使用する.
※"妙な,変な"の意味です.某プロジェクトの某キャラが使っている言葉だと思います.
みょんなところ
以下の点がみょんなところだと思いました.
※個人の見解です.専門的な人からしたら,全然みょんではないかもしれません
- ヘッダ (タイトル行)がない
→ まあ普通にあり得る.ヘッダなし指定と,カラム名を設定する必要あり.
- (ヘッダはないのに)コメントがある
→ なぜ不要なものがあるのか?大した情報でもないので,入れないでほしかった...
- 時間情報がエポック秒表記になっている
→ はじめ見たときわからなかった.人の目でわかる表記に変換する必要あり.
- 値が存在しない列が存在する
→ 謎.どの行にも値がない完全に不要な列が存在していた.エクセルで見るとそれが分からず,テキストエディターで見ると最後にカンマがついていて,ここでもひと手間必要だった.
どんなものかと具体的に表すと,以下のファイルみたいなcsv ファイルです.
sample data
1606997936543,529,
1606997943550,586,
1606997944556,364,
1606997965564,212,
1606997975572,749,
1606997982578,856,
1606997994583,267,
1606998022588,81,
1606998043598,808,
1606998064610,945,
なお,このデータはダミーです.
実際にあったファイルをもとに,以下のスクリプトで生成しました.
# !/bin/bash
for i in $(seq 1 10)
do
time=$(date +%s%3N)
count=$(echo $(($RANDOM % 1000)))
echo "$time,$count," >> sample_data.csv
sleep=$(echo $(($RANDOM % 60)))
sleep $sleep
done
sed -i '1isample data' sample_data.csv
プログラム
以下が,プログラムの全体です.
import pandas as pd
import matplotlib.pyplot as plt
import datetime
file = "sample_data.csv"
data = pd.read_csv(file, header=None, names=["time", "sum"], encoding='UTF8', skiprows=1, usecols=[0, 1])
for i in range(len(data.index)):
epoc = data.iat[i, 0] / 1000.0
timestamp = datetime.datetime.fromtimestamp(epoc).strftime('%Y-%m-%d %H:%M:%S.%f')
data.loc[i, 'time'] = timestamp
print(data)
data.plot(x=data.columns[0])
ヘッダなしの場合
ヘッダなしのcsv の場合,header=None と入力し,カラム名を自らnames=["time", "sum"] で指定します.今回の場合,一列目は,エポック秒なのでtime,二列目は合計値なのでsumとしています.
header=None, names=["time", "sum"]
コメント行を無視
次に,1行目のコメント行を無視する記述です.
不要なコメントがある1行目をスキップします.
skiprows=1
値のない3列目を無視
次に,値のない3列目を無視して,1列目と2列目だけを使いたいので,以下の記述を入れます.
usecols=[0, 1]
エポック秒を時刻表記に変換
最後に,1列目のエポック秒を人の目でわかる時刻表記に変換します.
for i in range(len(data.index)):
epoc = data.iat[i, 0] / 1000.0
timestamp = datetime.datetime.fromtimestamp(epoc).strftime('%Y-%m-%d %H:%M:%S.%f')
data.loc[i, 'time'] = timestamp
ミリ秒を含んでいるので,最初に1000 で割ってから時刻表記に直します.今回の場合,"2020-12-03 21:18:56.543000" という時刻表記に変換されます.
変換後は,元のデータフレームに値を入れなおしています.
実行結果
実行結果です.まずは,変換後のプロット対象であるデータフレームの中身は以下のようになりました.
time sum
0 2020-12-03 21:18:56.543000 529
1 2020-12-03 21:19:03.550000 586
2 2020-12-03 21:19:04.556000 364
3 2020-12-03 21:19:25.564000 212
4 2020-12-03 21:19:35.572000 749
5 2020-12-03 21:19:42.578000 856
6 2020-12-03 21:19:54.583000 267
7 2020-12-03 21:20:22.588000 81
8 2020-12-03 21:20:43.598000 808
9 2020-12-03 21:21:04.610000 945
余計な列やコメントが消えており,時刻もエポック秒ではなく一目でわかる表記になっていることが分かります.
最後に,このデータをプロットします.その結果が以下です.
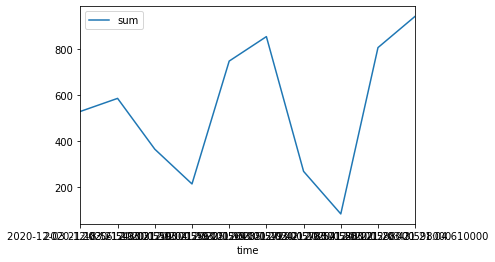
無事にプロットできています.めでたし,めでたし???
横軸の表記は何とかしたいですが,今後の課題ということで.
まとめ
- みょんなcsv ファイルを頑張ってプロットまでもっていった
- 世の中いろんなファイルがあるなーと感心した
- 頑張れば,なんとかなる
- 横軸の表記を今後どうにかしたい
- ところで,"みょん"って,使って大丈夫かな?
以上です.