やりたかったこと
記事のタイトルが長くなってしまいましたが、
今回やってみたかったのは、下記のような折れ線グラフの描画です。

時系列データを python で折れ線グラフで描画する際、
「グラフの値とは別な指標でマーカ色を変更したい」 というニーズに対するものです。
python実装ということで matplotlib や seaborn での実現例をググってみたのですが、該当するサンプルが上手く見つけられず、結局自分で試行錯誤するはめとなりました。
以下、その試行錯誤の過程と最終結果を共有します。
背景
先日、私の友人が健康診断を受け「またD判定だ~」と嘆いておりました。
友人曰く「XXX値が低いのは体質的なもの。自分としては標準範囲!」とのこと。
今回、過去15回ぶんの健診データを開示してもらえることになり、果たして標準範囲と言えそうなのか、その推移をグラフにして確認してみることにしました。
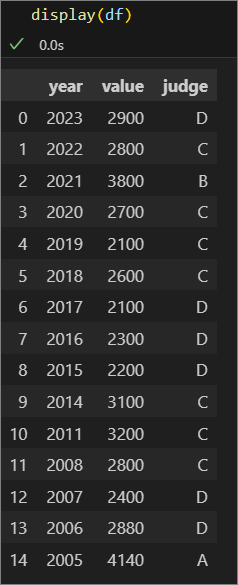
先ずは、実際のデータを見てみましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({
'year': [2023, 2022, 2021, 2020, 2019, 2018, 2017, 2016, 2015, 2014, 2011, 2008, 2007, 2006, 2005,],
'value': [2900, 2800, 3800, 2700, 2100, 2600, 2100, 2300, 2200, 3100, 3200, 2800, 2400, 2880, 4140,],
'judge': [ 'D', 'C', 'B', 'C', 'C', 'C', 'D', 'D', 'D', 'C', 'C', 'C', 'D', 'D', 'A',],
})
データ値は検討に影響が出ない範囲でレンジ変換したものとなります。
・year:健診年度
・value: 検査値
・judge: 判定結果
試行錯誤の過程
先ずは上記データを、時系列の折れ線グラフにして描画します。
plt.plot(df['year'], df['value'])
plt.show()

続いて目盛りやマーカをつけて、見た目を少し整えます。
plt.plot(df['year'], df['value'], marker='o')
plt.xticks( np.arange(2005, 2025, 5)) # X軸ラベル設定
plt.minorticks_on() # 小目盛りON
plt.grid() # グリッド線ON
plt.show()

さらに表示に変更を加え、平均線を追加してみます。
たしかに今年の値は「自分にとっては標準範囲内」という友人の主張も一理ありそうです。
plt.axhline( df['value'].mean(), color='k', linestyle=":", zorder=0) # 平均線(黒点線)
plt.plot(df['year'], df['value'], marker='o')
plt.xticks( np.arange(2005, 2025, 5))
plt.minorticks_on()
plt.grid()
plt.show()

さて、ここで各回の判定結果(A~E)によってマーカの色を変化させ、検査値の推移と判定結果との関係も確認してみたくなりました。
しかし、matplotlib の plot関数には 1本の折れ線のマーカ色を変える方法が見当たりません。
一方、散布図用の scatter関数にはプロット毎にマーカ色を指定する方法がありました。
そこで次の方法をとってみることにしました。
- plot関数で折れ線を描画(マーカはつけない)
- scatter関数により、プロット毎に色を指定しマーカを描画
- 両者を重ね合わせて表示
cdict = {
'A': 'g', # A判定は緑
'B': 'b', # B判定は青
'C': 'y', # ...黄
'D': 'r', # ...赤
'E': 'k', # ...黒
}
colors = [cdict[v] for v in df['judge']]
plt.axhline( df['value'].mean(), color='k', linestyle=":") # 平均線
plt.plot(df['year'], df['value']) # marker無し
plt.scatter(df['year'], df['value'], s=100, c=colors) # marker描画
plt.xticks( np.arange(2005, 2025, 5))
plt.minorticks_on()
plt.grid()
plt.show()

scatter関数を最後に呼び出すことでマーカが最後に描画されることを期待しましたが、実際には折れ線がマーカに上書きされてしまいました(関数を呼ぶ順序を変えても状況変わらず)。
......... 調べた結果、重ね合わせの描画順は zorder引数で指定するのがよいようです。
plt.axhline( df['value'].mean(), color='k', linestyle=":", zorder=0) # 平均線
plt.plot(df['year'], df['value'], zorder=1) # markerは無しへ
plt.scatter(df['year'], df['value'], s=100, c=colors, zorder=2) # marker描画
plt.xticks( np.arange(2005, 2025, 5))
plt.minorticks_on()
plt.grid()
plt.show()
こうして見ると、C判定<黄> と D判定<赤> の基準には各年でバラつきがあるようです。
これは他の指標もあわせ総合的に判定した結果と言えるかもしれませんが、友人のケースでは他の検査項目値は標準範囲内に収まっているとのことなので、単に判定者のさじ加減でバラついている可能性もありそうです。
友人の検査値が標準範囲といえるかどうか判断するには、もっと多くのデータを集め検討が必要になりますが、表題の目的が達成したところで記事は一区切りとさせていただきます。
なお、scatter関数ではマーカ色だけでなくマーカの大きさもプロット毎に指定可です。
よって、このように plot と scatter を組み合わせれば、時系列データの推移確認に第2・第3の指標を加えた可視化が実現出来そうです。
最終サンプルコード
試行錯誤の結果の最終形です。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({
'year': [2023, 2022, 2021, 2020, 2019, 2018, 2017, 2016, 2015, 2014, 2011, 2008, 2007, 2006, 2005,],
'value': [2900, 2800, 3800, 2700, 2100, 2600, 2100, 2300, 2200, 3100, 3200, 2800, 2400, 2880, 4140,],
'judge': [ 'D', 'C', 'B', 'C', 'C', 'C', 'D', 'D', 'D', 'C', 'C', 'C', 'D', 'D', 'A',],
})
cdict = {
'A': 'g', # A判定は緑
'B': 'b', # B判定は青
'C': 'y', # ...黄
'D': 'r', # ...赤
'E': 'k', # ...黒
}
colors = [cdict[v] for v in df['judge']]
plt.axhline( df['value'].mean(), color='k', linestyle=":", zorder=0) # 平均線
plt.plot(df['year'], df['value'], zorder=1) # marker無し
plt.scatter(df['year'], df['value'], s=100, c=colors, zorder=2) # marker描画
plt.xticks( np.arange(2005, 2025, 5))
plt.minorticks_on()
plt.grid()
plt.show()
動作確認環境:
・ python 3.10.11 + matplotlib 3.7.1