langchainのエージェントにキャラと役割を与えてさんま御殿をやらせてみました。
元ネタはこちらです。
https://python.langchain.com/en/latest/use_cases/agent_simulations/multiagent_authoritarian.html
デモ
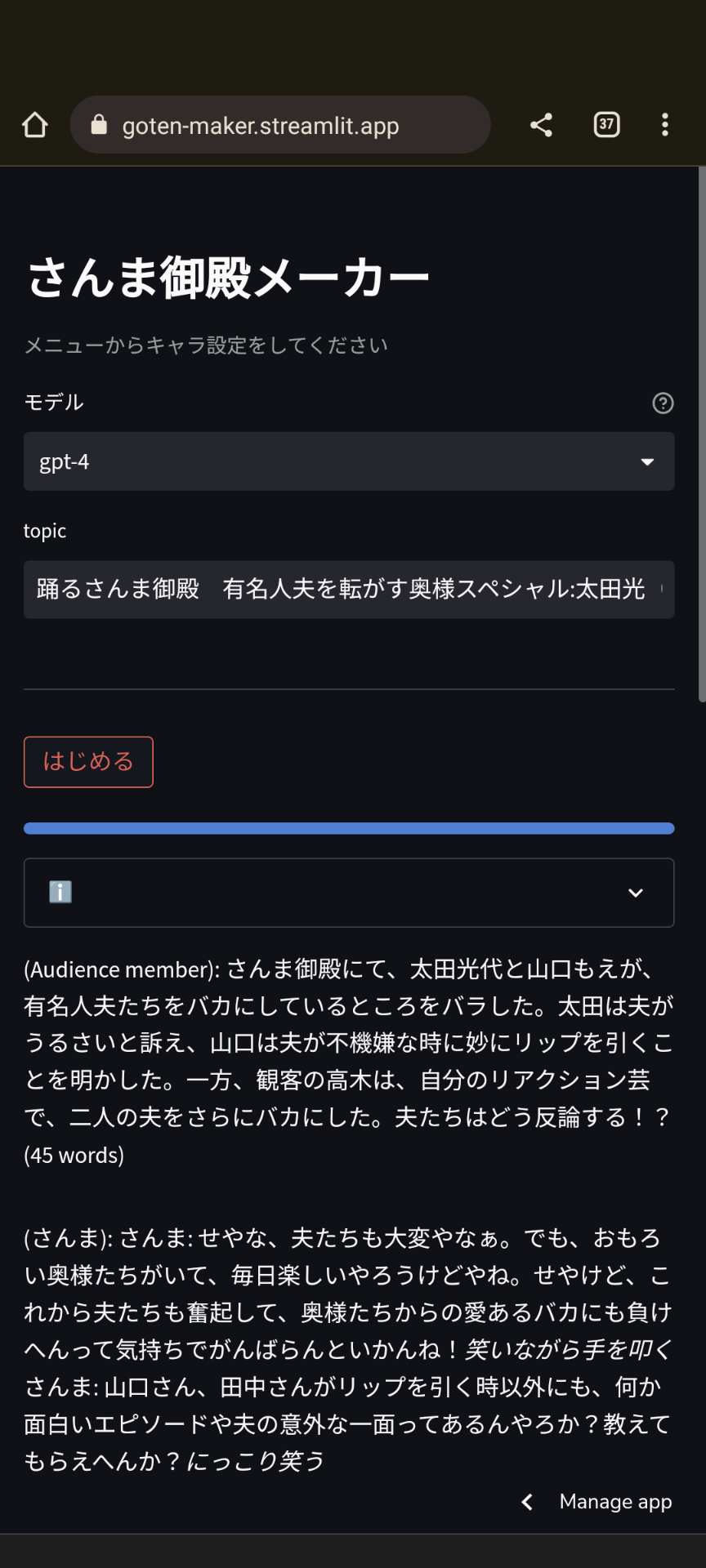

基本的にはDialogエージェントがそれぞれ会話のキャッチボールをしている感じですが、司会が各自に話を振るというのが特徴です。今回は話の振り方はランダムですが、何かしらのスコアリングで話しのフリ先を変える、トピックによって変える、など工夫の余地は大きいです。
コード
全コードはこちらを見てください。
https://github.com/yazoo1220/multi-agent-tv-show/blob/main/app.py
全体像
長いので大まかな全体像について解説します。(解説はGPTで生成)
最初の部分では、ユーザーがStreamlitのインターフェースを通じて設定を入力します。これには、AIモデルの選択(GPT-3.5-turboまたはGPT-4)、トピック、参加者の名前、役割、キャラクターなどが含まれます。
それから、ユーザーが「はじめる」ボタンを押すと、Streamlitのプログレスバーが表示され、対話の準備が始まります。
この準備フェーズでは、各参加者の詳細な説明、ヘッダー、システムメッセージが生成されます。この部分でAIモデルが利用されています。さらに、特定のトピックに関するより詳細な情報もAIモデルによって生成されます。
select_next_speaker関数は、次に話すべき参加者を選択します。奇数ステップでは、司会(director)が話し、偶数ステップでは、司会が次に話す参加者を選択します。
続いて、司会と他の参加者がDialogueAgentとして定義されます。この段階では、AIモデルに特定の設定(AIモデルの名前、温度、コールバック)が適用されます。
それらのDialogueAgentを使用して、DialogueSimulatorが作成され、対話が開始されます。対話は、特定のトピックを注入することで開始され、その後、参加者が交互に話すようにステップが進みます。この対話は司会がストップ信号を送るまで続きます。
クラスについての説明
主要なクラスや関数の詳細な解説を行います。
DirectorDialogueAgent クラス
このクラスは、対話の進行を指導する司会の役割を表しています。主に次のようなメソッドを含みます:
-
__init__: 司会エージェントを初期化します。モデル、スピーカーのリスト、ストップの確率などを引数にとります。 -
_generate_response: モデルを使用して応答を生成します。 -
_choose_next_speaker: 次に話すスピーカーを選択します。この選択は一様ランダムに行われます。 -
select_next_speaker: 司会が選んだスピーカーを返します。 -
send: 司会の応答を生成し、次のスピーカーを選択してプロンプトを生成します。
DialogueAgent クラス
このクラスは、対話の参加者を表します。以下のメソッドが含まれています:
-
__init__: ダイアログエージェントを初期化します。エージェントの名前、システムメッセージ、モデルを含む。 -
reset: エージェントの状態をリセットします。 -
send: エージェントの応答を生成します。
DialogueSimulator クラス
対話の進行をシミュレートするクラスです。主なメソッドは以下の通りです:
-
__init__: ダイアログシミュレータを初期化します。対話の参加者(エージェント)と、次のスピーカーを選択する関数を引数にとります。 -
reset: すべてのエージェントの状態をリセットし、新たな対話を開始します。 -
inject: 特定のエージェントの発話を対話に注入します。 -
step: 対話の次のステップを実行します。次に話すべきエージェントを選択し、そのエージェントの応答を生成します。
select_next_speaker 関数
次に話すべきエージェントを選択する関数です。奇数のステップでは、司会が選ばれ、偶数のステップではディレクターが次のスピーカーを選択します。
streamlitのGUI部分
最後の部分では、StreamlitのGUIを構築しています。
StreamlitはPythonでWebアプリケーションを作成するためのフレームワークで、以下の部分で使われています:
-
st.title、st.caption、st.markdownなどの関数は、ページ上にテキストを表示します。 -
st.selectbox、st.text_inputは、ユーザーに情報を入力させるためのウィジェットを提供します。たとえば、モデルの選択、話題の入力、各エージェントの設定(名前、役割、性格)などに使われています。 -
st.buttonはボタンウィジェットを表示し、ユーザーがそれをクリックするとTrueを返します。ここでは、「はじめる」ボタンとして使用され、ユーザーがクリックすると対話のシミュレーションが開始されます。 -
st.spinnerは長い処理の間に表示されるメッセージを表示します。 -
st.progressは進行状況バーを表示し、進行状況をユーザーに伝えます。 -
st.expanderは情報をコンパクトに表示するためのウィジェットで、ユーザーがクリックすると内容が展開します。 -
st.writeはページにテキストを表示します。ここでは、シミュレートされた対話の各ステップでエージェントのメッセージを表示するために使われています。
重要な部分
まずはキャラ設定。
st.title('さんま御殿メーカー')
st.caption('メニューからキャラ設定をしてください')
model = st.selectbox(label='モデル', options=['gpt-3.5-turbo','gpt-4'],help="gpt-4は遅くなる可能性があります。")
topic = st.text_input('topic','踊るさんま御殿 有名人夫を転がす奥様スペシャル:太田光(爆笑問題)の妻・太田光代と、田中裕二(爆笑問題)の妻・山口もえがテレビ初共演。山口は「社長のおかげで我が家はなりたってます」と太田に感謝。しかし二人の夫に対する不満が爆発!')
st.markdown('---')
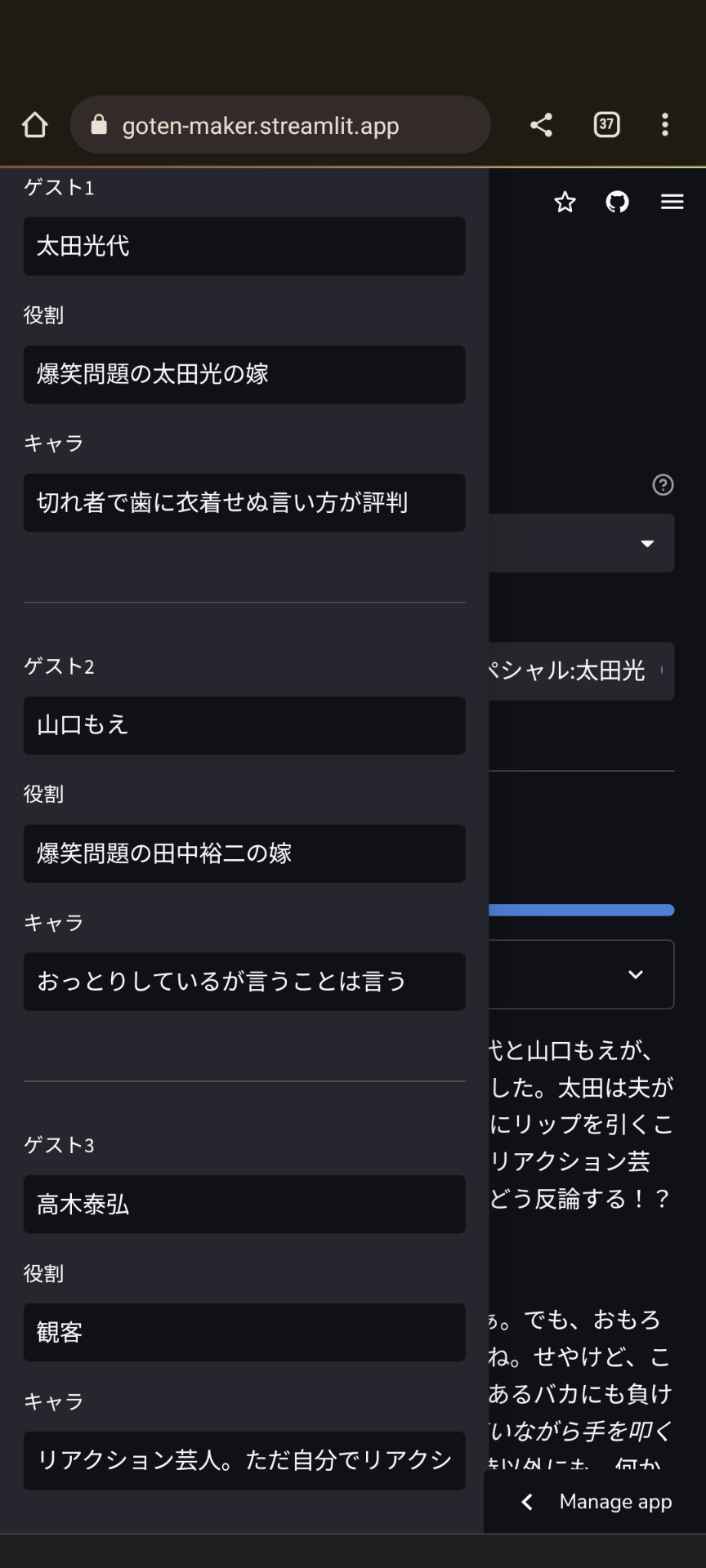
director_name = st.sidebar.text_input('司会者',"さんま")
director_role = st.sidebar.text_input('役割','踊るさんま御殿の司会者')
director_character = st.sidebar.text_input('キャラ','どんなネタも面白くしてしまう最強のコメディアン。関西弁でノリツッコミが得意。')
st.sidebar.markdown('---')
agent1_name = st.sidebar.text_input('ゲスト1',"太田光代")
agent1_role = st.sidebar.text_input('役割','爆笑問題の太田光の嫁')
agent1_character = st.sidebar.text_input('キャラ','切れ者で歯に衣着せぬ言い方が評判')
st.sidebar.markdown('---')
agent2_name = st.sidebar.text_input('ゲスト2',"山口もえ")
agent2_role = st.sidebar.text_input('役割','爆笑問題の田中裕二の嫁')
agent2_character = st.sidebar.text_input('キャラ','おっとりしているが言うことは言う')
st.sidebar.markdown('---')
agent3_name = st.sidebar.text_input('ゲスト3',"高木泰弘")
agent3_role = st.sidebar.text_input('役割','観客')
agent3_character = st.sidebar.text_input('キャラ','リアクション芸人')
st.sidebar.markdown('---')
これはstremalit上で自由に設定できるようにしています。
この情報を辞書にします。
agent_summaries = OrderedDict({
director_name: (director_role, director_character),
agent1_name: (agent1_role, agent1_character),
agent2_name: (agent2_role, agent2_character),
agent3_name: (agent3_role, agent3_character),
})
辞書を元に各エージェントに台本(プロンプト)を作成するような関数がこちらです。
def generate_agent_description(agent_name, agent_role, agent_location):
agent_specifier_prompt = [
agent_descriptor_system_message,
HumanMessage(content=
f"""{conversation_description}
Please reply with a creative description of {agent_name}, who is a {agent_role} in {agent_location}, that emphasizes their particular role and location.
Speak directly to {agent_name} in {word_limit} words or less.
Do not add anything else."""
)
]
agent_description = ChatOpenAI(temperature=1.0)(agent_specifier_prompt).content
return agent_description
def generate_agent_header(agent_name, agent_role, agent_location, agent_description):
return f"""{conversation_description}
Your name is {agent_name}, your role is {agent_role}, and you are located in {agent_location}.
Your description is as follows: {agent_description}
You are discussing the topic: {topic}.
Your goal is to provide the funniest, creative, and silly perspectives of the topic from the perspective of your role and your character. Please speak in Japanese
"""
def generate_agent_system_message(agent_name, agent_header):
return SystemMessage(content=(
f"""{agent_header}
You will speak in the style of {agent_name}, and exaggerate your personality.
Do not say the same things over and over again.
Speak in the first person from the perspective of {agent_name}
For describing your own body movements, wrap your description in '*'.
Do not change roles!
Do not speak from the perspective of anyone else.
Speak only from the perspective of {agent_name}.
Stop speaking the moment you finish speaking from your perspective.
Never forget to keep your response to {word_limit} words!
Do not add anything else. Please speak in Japanese
"""
))
このプロンプトを変えると番組の趣旨や方向性も変わるので遊べるポイントです。
エージェントのインスタンス化
エージェントのllmのモデルやメモリなどを入れるのがここです。
司会の継承をして各登壇者も作っています。
director = DirectorDialogueAgent(
name=director_name,
system_message=agent_system_messages[0],
model=ChatOpenAI(temperature=0.9,model_name=model, callbacks=[handler]),
speakers=[name for name in agent_summaries if name != director_name],
stopping_probability=0.1
)
my_bar.progress(95)
agents = [director]
for name, system_message in zip(list(agent_summaries.keys())[1:], agent_system_messages[1:]):
agents.append(DialogueAgent(
name=name,
system_message=system_message,
model=ChatOpenAI(temperature=0.9,model_name=model,callbacks=[handler]),
))
## シミュレート
最後に、エージェントをシミュレータに入れて動かします。司会がストップ(一定確率)するまで続けます。
simulator = DialogueSimulator(
agents=agents,
selection_function=functools.partial(select_next_speaker, director=director)
)
my_bar.progress(100)
simulator.reset()
simulator.inject('Audience member', specified_topic)
st.write(f"(Audience member): {specified_topic}")
st.write('\n')
while True:
name, message = simulator.step()
st.write(f"({name}): {message}")
st.write('\n')
if director.stop:
break
感想
プロンプトでコントロールしている部分も大きいので、コメディ調、真面目なディスカッションなどなど結構プロンプトで遊べます。
ただ、エージェントに台本を渡して演じさせるプロセスは勉強のしがいがありました。この延長には合成データがあります。つまり顧客(の行動データ)の生成です。エージェントが本当らしいリアクションをとれるようになると、新商品や広告、さまざまなものへの想定される行動データがとれるようになります。現状は人間と同じ、とまではいきませんが、人間っぽいリアクションはとってくれてますね。
合成データがつくれれば僕たちは顧客を実験台にせずともある程度ABテストなどを回せるようになるかもしれません。となると、データの生成から分析、改善まで自動化できるようになります。となるとめっちゃPDCAが早くなりそうですね。
テスト駆動開発のような、合成データ駆動マーケティングもできるかもしれません。
(データ分析してくれるエージェントの記事もこちらに書きましたので合わせてどうぞ!
https://qiita.com/yazoo/items/4549f4b319b6706d46e2)
さんま御殿メーカーは、その勉強にとても役立ちました。