langchainのエージェントに自律的にpythonコードを生成しながらデータ分析させるアプリを作りました。
実は最近はChatGPTのプラグインのNoteableという神アプリが似たようなことをしてくれるのですが、自力で作れると他のLLMを使う際やアプリ化する時に非常に便利なので共有します。
デモ
csvを読ませて質問すると答えを出してくれます。
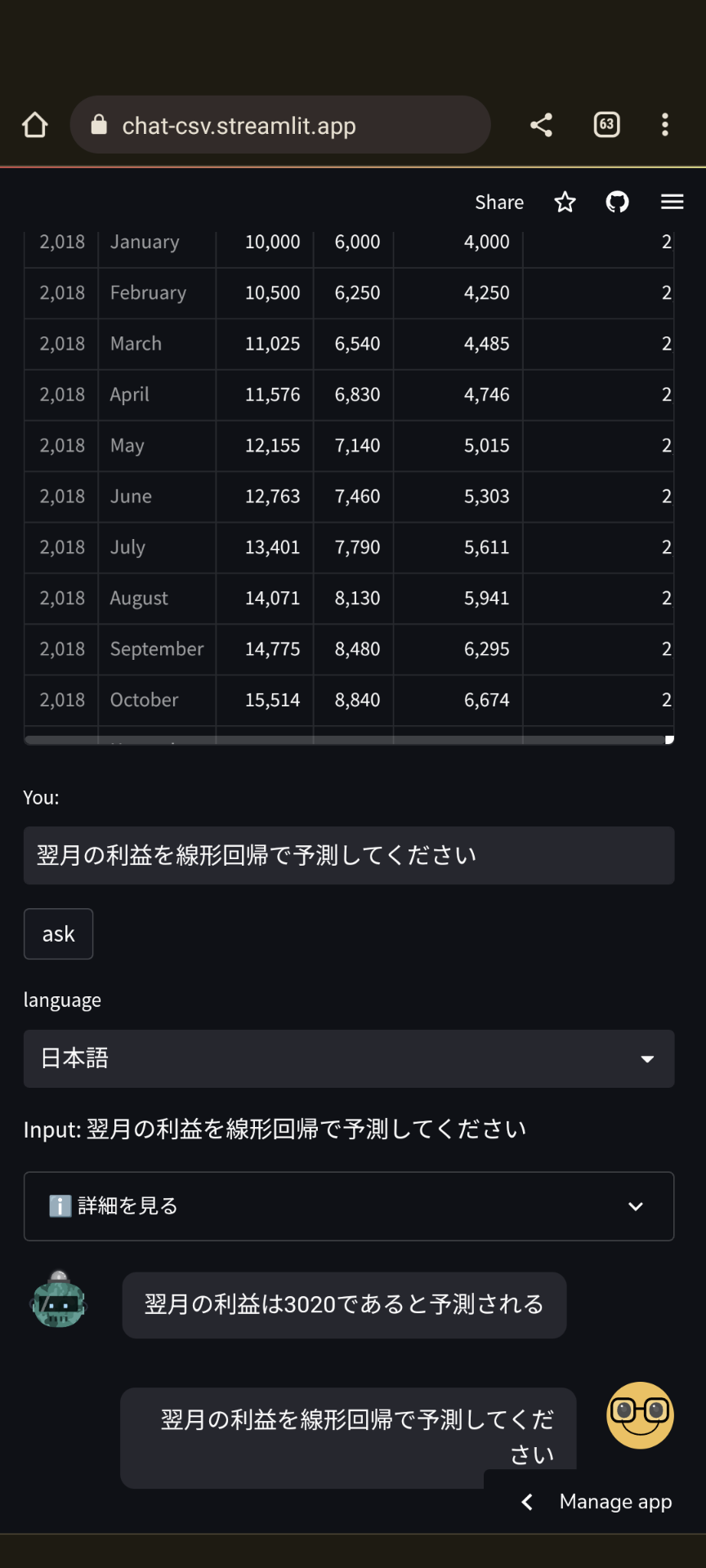
答えだけでなく経緯がどうなっているかのほうが気になると思うので、詳細についても表示しています。
まずpandasでcsvをデータフレーム化し、sklearnのLinearRegressionを呼び出して予測を立てていることがわかります。


実際に遊んでみたい場合はこちらをどうぞ。
https://chat-csv.streamlit.app/
csvのインデックスの箇所は適宜調整してください。
どうやって作っているのか
この記事を一言でまとめると、create_pandas_dataframe_agentを使いました、ということにつきます。これが優秀です。
これはツールとしてpython_repl_astを使って分析をしてくれるというものですが、特にデータの構造をAST(抽象構文木)で保持してくれるところが大きいです。これにより、LLM特有のハルシネーションが減り、ちゃんとデータ分析してくれます。
ただ、よくあるハマりポイントとして「途中のステップ(intermediate_steps)はどうやって表示するの?」というものがあります。これもdiscordで頻出する質問です。
また、メモリってどうやって保持させる?というのもstreamlit特有ですが問題になります。
そういったポイントにハマることなく、とりあえずこのコードを動かすことで一旦一通りの実装ができると思います。
# コード全体像
import streamlit as st
from streamlit_chat import message
import os
import pexpect
# From here down is all the StreamLit UI.
st.set_page_config(page_title="📊 ChatCSV", page_icon="📊")
st.header("📊 ChatCSV")
if "generated" not in st.session_state:
st.session_state["generated"] = []
if "past" not in st.session_state:
st.session_state["past"] = []
from langchain.agents import load_tools, initialize_agent, AgentType, Tool, tool
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
import pandas as pd
from langchain.agents import create_pandas_dataframe_agent
from langchain.memory import ConversationBufferMemory
from langchain import PromptTemplate
from langchain.callbacks.base import BaseCallbackHandler
from langchain.schema import (
HumanMessage,
)
from typing import Any, Dict, List
df = pd.DataFrame([])
data = st.file_uploader(label='Upload CSV file', type='csv')
# st.download_button(label='サンプルデータをダウンロードする',data='https://drive.google.com/file/d/1wuSx35y3-hjZew1XhrM78xlAGIDTd4fp/view?usp=drive_open',mime='text/csv')
header_num = st.number_input(label='Header position',value=0)
index_num = st.number_input(label='Index position',value=2)
index_list = [i for i in range(index_num)]
if data:
df = pd.read_csv(data,header=header_num,index_col=index_list)
st.dataframe(df)
def get_text():
input_text = st.text_input("You: ", "Tell me the average of the revenue", key="input")
return input_text
def get_state():
if "state" not in st.session_state:
st.session_state.state = {"memory": ConversationBufferMemory(memory_key="chat_history")}
return st.session_state.state
state = get_state()
prompt = PromptTemplate(
input_variables=["chat_history","input"],
template='Based on the following chat_history, Please reply to the question in format of markdown. history: {chat_history}. question: {input}'
)
class SimpleStreamlitCallbackHandler(BaseCallbackHandler):
""" Copied only streaming part from StreamlitCallbackHandler """
def __init__(self) -> None:
self.tokens_area = st.empty()
self.tokens_stream = ""
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
"""Run on new LLM token. Only available when streaming is enabled."""
self.tokens_stream += token
self.tokens_area.markdown(self.tokens_stream)
ask_button = ""
if df.shape[0] > 0:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0, max_tokens=1000), df, memory=state['memory'], verbose=True, return_intermediate_steps=True)
user_input = get_text()
ask_button = st.button('ask')
else:
pass
language = st.selectbox('language',['English','日本語'])
import json
import re
from collections import namedtuple
AgentAction = namedtuple('AgentAction', ['tool', 'tool_input', 'log'])
def format_action(action, result):
action_fields = '\n'.join([f"{field}: {getattr(action, field)}"+'\n' for field in action._fields])
return f"{action_fields}\nResult: {result}\n"
if ask_button:
st.write("Input:", user_input)
with st.spinner('typing...'):
prefix = f'You are the best explainer. please answer in {language}. User: '
handler = SimpleStreamlitCallbackHandler()
response = agent({"input":user_input})
actions = response['intermediate_steps']
actions_list = []
for action, result in actions:
text = f"""Tool: {action.tool}\n
Input: {action.tool_input}\n
Log: {action.log}\nResult: {result}\n
"""
text = re.sub(r'`[^`]+`', '', text)
actions_list.append(text)
answer = json.dumps(response['output'],ensure_ascii=False).replace('"', '')
if language == 'English':
with st.expander('ℹ️ Show details', expanded=False):
st.write('\n'.join(actions_list))
else:
with st.expander('ℹ️ 詳細を見る', expanded=False):
st.write('\n'.join(actions_list))
st.session_state.past.append(user_input)
st.session_state.generated.append(answer)
if st.session_state["generated"]:
for i in range(len(st.session_state["generated"]) - 1, -1, -1):
message(st.session_state["generated"][i], key=str(i))
message(st.session_state["past"][i], is_user=True, key=str(i) + "_user")
下記重要な部分のみ説明します。
pandas agentの作成
比較的シンプルですが、エージェントの作成時にst.session_stateで作成したメモリを入れています。
この方法についてはこちらでまとめています。
https://qiita.com/yazoo/items/70b7cf73eb3b232ca423
if df.shape[0] > 0:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0, max_tokens=1000), df, memory=state['memory'], verbose=True, return_intermediate_steps=True)
user_input = get_text()
ask_button = st.button('ask')
else:
pass
df.shape[0] > 0とすることで、csvをデータフレームとして読んだときのみ動くようにしています。
intermediate_stepsへのアクセス
まずはintermediate_stepsの情報を構造化して保持する用のnamedtuplesを作ります。
from collections import namedtuple
AgentAction = namedtuple('AgentAction', ['tool', 'tool_input', 'log'])
def format_action(action, result):
action_fields = '\n'.join([f"{field}: {getattr(action, field)}"+'\n' for field in action._fields])
return f"{action_fields}\nResult: {result}\n"
agentを走らせた時にintermediate_stepsをactionsに格納するようにします。
response = agent({"input":user_input}) #,"callbacks":handler})
actions = response['intermediate_steps']
actions_list = []
for action, result in actions:
text = f"""Tool: {action.tool}\n
Input: {action.tool_input}\n
Log: {action.log}\nResult: {result}\n
"""
text = re.sub(r'`[^`]+`', '', text)
actions_list.append(text)
制約
実はpandas agentでは文字をストリーミングすることは難しいです(2023年6月現在)。ストリーミングする方法はこちらにまとめたとおりなのですが、
https://qiita.com/yazoo/items/b318adbab0d5f3f58dc8
pandas agentはまだ旧来のCallbackManagerを使っていて、callbacksを使っても無視されます。そのうち対応すると思いますが、どうしてもいま使いたい場合はpandas agentのコードをコピペして、callbacksを追加する方法がありますが、メンテ上おすすめはできません。
感想
ここまでくると簡単なBIみたいなものがさくっと作れますね。ユーザーにある程度の分析の知識は必要になりますが、pythonを書いて実行してくれるのは書ける側としても普通に便利です。
また、もっとクエリに特化させたい場合は別途SQL用のエージェントがあってそれも優秀です。また別の機会に紹介したいと思います。