はじめに
バージョン:MySQL 8.0 (エンジンはInnoDB)
今回使うテーブルは以下です。
CREATE TABLE `table1` (
`id` int NOT NULL AUTO_INCREMENT,
`status` int DEFAULT NULL,
`created_at` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
主キーとなる id と別に、int型のカラムを2つつくっています。
これらにインデックスをつくったり消したりすることで、EXPLAINの結果がどうなるかみてみよう、という感じです。
テーブルスキャン、インデックスフルスキャンなど非効率的な検索はどういう条件で発生するか、反対に、効率的な検索はどういう条件なら実現できるかを確認してみよう、というのがテーマです。
主キーと別にカラムを2つつくったのは、カーディナリティの低いカラムと高いカラムがほしかったためです。
カラム名に特に意味はありません。
ダミーデータ準備
インデックスの挙動を確かめるにあたって、まず相当量のデータのあるテーブルが必要になるとおもわれます。
数件手動で Insert しただけのテーブルだと、オプティマイザはテーブルスキャンのほうが効率がいいと判断するかもしれないためです。
そこでとりあえず100万件くらいのデータを用意することにしました。
その1. 100万件のInsert文をつくる(挫折)
まずはなにも考えず100万件の insert 文をつくろうとしました。
10回くらいにわけてペタペタペーストするなり、mysqlコマンドに流すなりすればできるだろうと安直に考えましたが、ちょっとした正規表現の置換にエディタが悲鳴をあげ始めたため断念。
その2. MySQLだけでデータ生成する(成功)
参考)https://qiita.com/tayasu/items/c5ddfc481d6b7cd8866d
MySQLだけで乱数の生成や大量のinsertができそうだったので、こちらを試すことに。
カラのinsert文の発行を繰り返して、約100万件の行を生成したあと、以下のupdate文を実行。
mysql> update table1 set
-> status = ceil(rand() * 4),
-> created_at = cast(concat(1590, lpad(ceil(rand() * 1000000), 6, 0)) as decimal);
これで約100万件のデータは生成できました。
mysql> select count(*) from table1;
+----------+
| count(*) |
+----------+
| 1048576 |
+----------+
1 row in set (0.10 sec)
データの例としては、以下のようになっています。
| 1310692 | 1 | 1590674599 |
| 1310691 | 2 | 1590792462 |
| 1310690 | 3 | 1590598020 |
| 1310689 | 1 | 1590729991 |
| 1310688 | 1 | 1590474644 |
| 1310687 | 4 | 1590698694 |
status は大半は 1 ~ 4 のいずれか。(一部 5 となる行も手動で数行だけ追加)
created_at は多様で重複の少ない数列(一応Unix時間を想定)
status の散らばり具合も確認。
mysql> select count(*) from table1 where status = 1;
+----------+
| count(*) |
+----------+
| 262463 |
+----------+
1 row in set (0.07 sec)
mysql> select count(*) from table1 where status = 2;
+----------+
| count(*) |
+----------+
| 262516 |
+----------+
1 row in set (0.07 sec)
mysql> select count(*) from table1 where status = 3;
+----------+
| count(*) |
+----------+
| 261761 |
+----------+
1 row in set (0.06 sec)
mysql> select count(*) from table1 where status = 4;
+----------+
| count(*) |
+----------+
| 261832 |
+----------+
1 row in set (0.07 sec)
いい感じでバラバラになっています。
1. インデックスは主キーのみの場合
まずは追加のインデックスを作らず、テーブルスキャンの発生を確認します。
mysql> EXPLAIN SELECT * FROM table1 WHERE status = 1;
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | table1 | NULL | ALL | NULL | NULL | NULL | NULL | 1047493 | 10.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
status の等価比較をおこなっていますが、status にはインデックスが存在しないため、type = ALL とテーブルスキャンになっていることがわかります。
そのため、オプティマイザが統計情報を基に算出した、調査する行の見積もりを示す rows も 100万行となっているわけですね。
2. status の単一インデックスの場合
mysql> ALTER TABLE table1 ADD INDEX status_idx(status);
Query OK, 0 rows affected (7.53 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM table1;
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| table1 | 0 | PRIMARY | 1 | id | A | 1047493 | NULL | NULL | | BTREE | | | YES | NULL |
| table1 | 1 | status_idx | 1 | status | A | 4 | NULL | NULL | YES | BTREE | | | YES | NULL |
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.01 sec)
今度は status にだけインデックスをはります。
そしてさきほどと同じ SELECT を実行してみると、
mysql> EXPLAIN SELECT * FROM table1 WHERE status = 1;
+----+-------------+--------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
| 1 | SIMPLE | table1 | NULL | ref | status_idx | status_idx | 5 | const | 523746 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
1 row in set, 1 warning (0.01 sec)
type が ref となっており、インデックスが使われていることがわかります。
ただ、rows が 50万行ほどあり、実際の SELECT 結果よりも多い行数をオプティマイザは見込んでいます。
原因はよくわからないですが、この rows はあくまで見積もりなので、カーディナリティが低いとオプティマイザはコストを大きく見積もるなどといったことがあるのかもしれません。
なお、status が 5 となる行も4行だけ作ってあります。
mysql> SELECT * FROM table1 WHERE status = 5;
+---------+--------+------------+
| id | status | created_at |
+---------+--------+------------+
| 552329 | 5 | 1590505521 |
| 804648 | 5 | 1590505612 |
| 1131720 | 5 | 1590505700 |
| 1294273 | 5 | 1590505517 |
+---------+--------+------------+
4 rows in set (0.00 sec)
そこでこの SELECT の EXPLAIN を出力したところ、rows は実際と同じ行数でした。
mysql> EXPLAIN SELECT * FROM table1 WHERE status = 5;
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | table1 | NULL | ref | status_idx | status_idx | 5 | const | 4 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
3. created_at の単一インデックスの場合
mysql> ALTER TABLE table1 ADD INDEX created_at_idx(created_at);
Query OK, 0 rows affected (7.22 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM table1;
+--------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| table1 | 0 | PRIMARY | 1 | id | A | 1045228 | NULL | NULL | | BTREE | | | YES | NULL |
| table1 | 1 | created_at_idx | 1 | created_at | A | 633786 | NULL | NULL | YES | BTREE | | | YES | NULL |
+--------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.02 sec)
次は created_at にインデックスをはり、範囲指定の検索をしてみます。
mysql> EXPLAIN SELECT * FROM table1 WHERE 1590990000 < created_at;
+----+-------------+--------+------------+-------+----------------+----------------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+----------------+----------------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | table1 | NULL | range | created_at_idx | created_at_idx | 5 | NULL | 18654 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+----------------+----------------+---------+------+-------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
上記のように、インデックスの利用により十分絞り込めそうなときは type = range となり、高速な検索ができそうですが、
mysql> EXPLAIN SELECT * FROM table1 WHERE 1590500000 < created_at;
+----+-------------+--------+------------+------+----------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+----------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | table1 | NULL | ALL | created_at_idx | NULL | NULL | NULL | 1045228 | 50.00 | Using where |
+----+-------------+--------+------------+------+----------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
SELECT 結果が膨大になりそうな WHERE句を指定してみると、type = ALL と、テーブルスキャンになることもありました。
4. (status, created_at) の複合インデックス
mysql> show index from table1;
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| table1 | 0 | PRIMARY | 1 | id | A | 1047493 | NULL | NULL | | BTREE | | | YES | NULL |
| table1 | 1 | multi_idx | 1 | status | A | 3 | NULL | NULL | YES | BTREE | | | YES | NULL |
| table1 | 1 | multi_idx | 2 | created_at | A | 912203 | NULL | NULL | YES | BTREE | | | YES | NULL |
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
status、created_at の順番で複合インデックスを作ります。
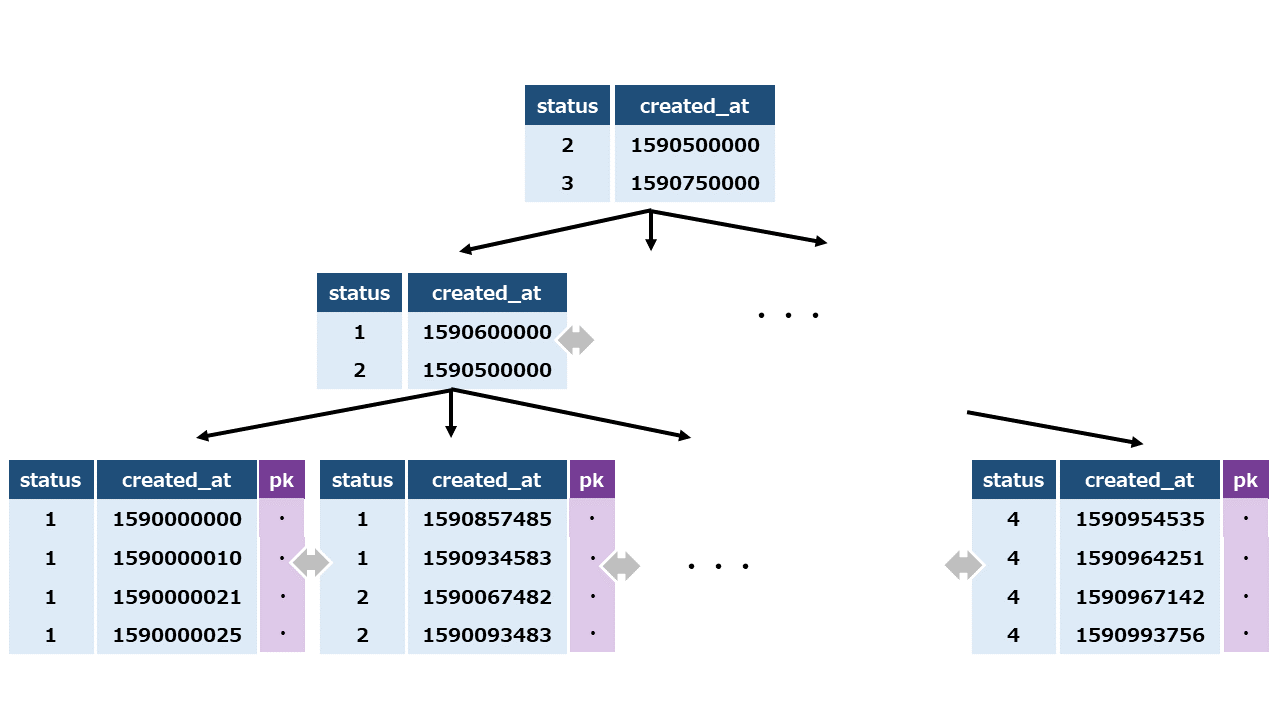
この複合インデックスの概念図を描いてみました。おおよそこんな感じだろうと思います。
MySQLのインデックスは、B+Tree というアルゴリズムで実装されています。
これは、インデックスとして入力されたキーをもとに、値を素早く検索して出力するための仕組みです。
このB+Treeアルゴリズムでは、インデックスのいくつかのセットが1つのノードを示し、ツリー構造でデータが保持されます。
インデックスを検索するときにはルートとなる上段のノードから検索を開始し、各ノードで計算した結果をもとに、どの枝に進むのか決定し、最終的には対象となるインデックスが見つかればその行を返します。
取得したいデータは最下段のノード(リーフノード)にのみ含まれているので、途中のノードとリーフノードでは持っている情報が異なります。
このアルゴリズムによって、logN のオーダーで検索できることを可能にしています。
MySQLでは、このB+Treeの次数が3であるようで、また隣接ノード同士は互いにポインタでリンクされているようです。
セカンダリインデックス(≠主キーインデックス)の場合には、リーフノードにはインデックスにひもづく主キーインデックスが格納されています。
そのためこのセカンダリインデックスの検索により得られるものは主キーインデックスの値であり、この値を利用して今度は主キーインデックスから検索をすることで、行が格納されたページへのポインタを取得します。
4.1 インデックス内のすべてのカラムを指定
mysql> explain select * from table1 where created_at < 1590505600 and status = 5;
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | table1 | NULL | range | multi_idx | multi_idx | 10 | NULL | 2 | 100.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+
status を等価比較、created_at を範囲比較すると、EXPLAIN 結果は type が range となり、インデックスを使った高速な検索ができていることがわかります。
4.2 インデックスの前半だけ指定
mysql> explain select * from table1 where status = 5;
+----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | table1 | NULL | ref | multi_idx | multi_idx | 5 | const | 4 | 100.00 | Using index |
+----+-------------+--------+------------+------+---------------+-----------+---------+-------+------+----------+-------------+
複合インデックスの前半の status だけを WHERE 句で指定した SELECT でも、type = ref とあるように、インデックスを使用した検索がおこなわれています。
4.3 インデックスの後半だけ指定
mysql> explain select * from table1 where created_at < 1590505600;
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+----------------------------------------+
| 1 | SIMPLE | table1 | NULL | range | multi_idx | multi_idx | 10 | NULL | 349129 | 100.00 | Using where; Using index for skip scan |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+----------------------------------------+
複合インデックスの後半だけを指定すると、インデックスフルスキャン(=type が index)になる.....かとおもいきや(※)、そうではなく type = range と、通常のインデックスを利用した高速な検索が行われました。
これはどうやら v8.0.13 で追加された機能のようで、条件を満たせばインデックスの後半だけ指定した WHERE 句でも高速に検索できるようです。
しかし条件によってはフルインデックススキャン、あるいはテーブルスキャンなど遅い検索となるので、複合インデックスを作成するときのインデックスの順番にはやはり気を配る必要がありそうです。
参考:https://dev.mysql.com/doc/refman/8.0/en/range-optimization.html#range-access-skip-scan
※想定していたフルインデックススキャン
たとえば、4.2 のような複合インデックスの前半を用いた検索がされるとき、効率的な検索がされるとおもわれます。
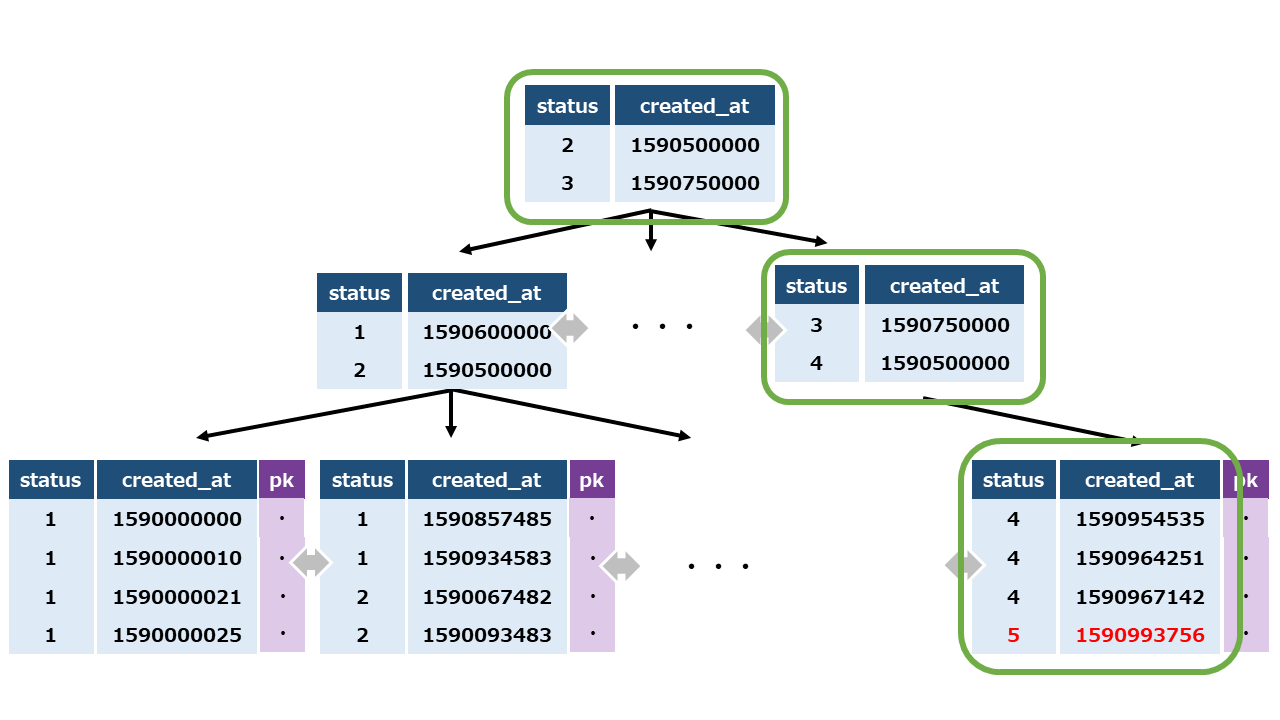
それは、この複合インデックスが status の値によってソートされているため、ごく一部のノードの読み込みだけで検索できるとおもわれるからです。
一方、4.3 のような、複合インデックスの後半だけを WHERE 句で指定した SELECT の際には、効率的な検索は難しく思えます。
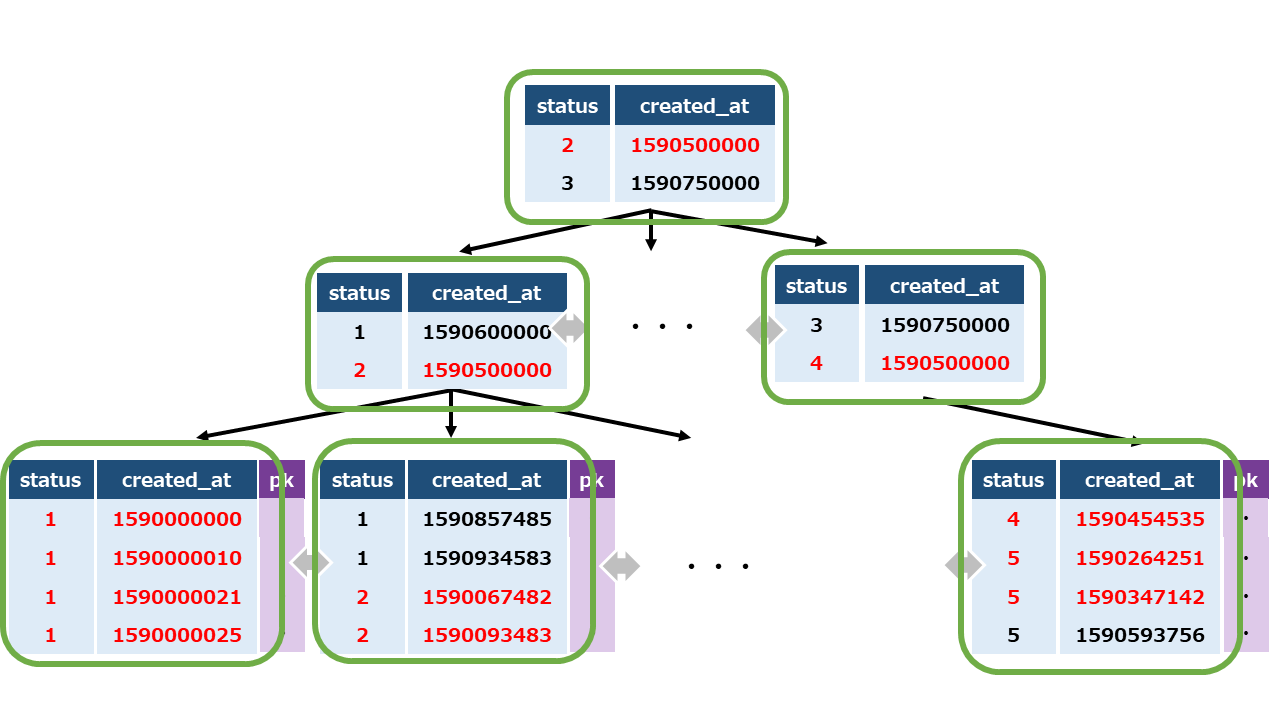
この複合インデックスの中では、created_at は部分的にソートされているだけなので、検索するに際しては、ノード同士のリンクを辿りながら多くのインデックスを読み取る必要があると思われるからです。(今回はMySQLの機能によってこれが防止されましたが)
5. (created_at, status) の複合インデックス
mysql> ALTER TABLE table1 ADD INDEX multi_idx(created_at, status);
Query OK, 0 rows affected (8.50 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW INDEX FROM table1;
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| table1 | 0 | PRIMARY | 1 | id | A | 1045228 | NULL | NULL | | BTREE | | | YES | NULL |
| table1 | 1 | multi_idx | 1 | created_at | A | 626658 | NULL | NULL | YES | BTREE | | | YES | NULL |
| table1 | 1 | multi_idx | 2 | status | A | 910291 | NULL | NULL | YES | BTREE | | | YES | NULL |
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3 rows in set (0.02 sec)
次は複合インデックスの順序を変えて、created_at をさきに持ってきました。
5.1 インデックス内のすべてのカラムを指定
この状態で、さきほど 4.1 で実行したものと同じ EXPLAIN を実行してみます。
mysql> explain select * from table1 where created_at < 1590505600 and status = 5;
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | table1 | NULL | range | multi_idx | multi_idx | 5 | NULL | 522614 | 10.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
すると、type は同じく range ですが、4.1 の時には 2 件しかなかった rows が大幅に増えています。
今回の実行例では status の等価比較により十分絞り込めることが期待できるので、(created_at, status) の順序の複合インデックスとは相性が悪いことがわかります。
5.2 インデックスの前半だけ指定
mysql> explain select * from table1 where created_at < 1590505600;
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | table1 | NULL | range | multi_idx | multi_idx | 5 | NULL | 522614 | 100.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
4.3 と同じ SELECT を実行しています。
4.3 では、created_at がインデックスの後半にあったので、基本的には望ましくないと思われる実行の仕方でしたが、skip scan という機能によって、type = range の検索が可能になっていました。
対して今回は、インデックスの前半部分を指定した検索ですから、通常通り、インデックスを利用した検索が見込めます。
EXPLAIN を見ると、type = range で、Using index とありますから、インデックスを利用した範囲検索ができています。
5.3 インデックスの後半だけ指定
mysql> explain select * from table1 where status = 5;
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+---------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+---------+----------+--------------------------+
| 1 | SIMPLE | table1 | NULL | index | multi_idx | multi_idx | 10 | NULL | 1045228 | 10.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+-----------+---------+------+---------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
4.2 と同じ SELECT を実行しています。
望んでいたものがでました!
type = index となっていて、インデックスフルスキャンになっていることが確認できます。
インデックスを利用してはいるものの、B+Tree のリーフからリーフへと、リンクをたどってすべて読み込むような処理をして、結局ほぼすべてのインデックスを読み込んでいるために、インデックスが速度向上にほとんど役立っていないような状況だとおもいます。
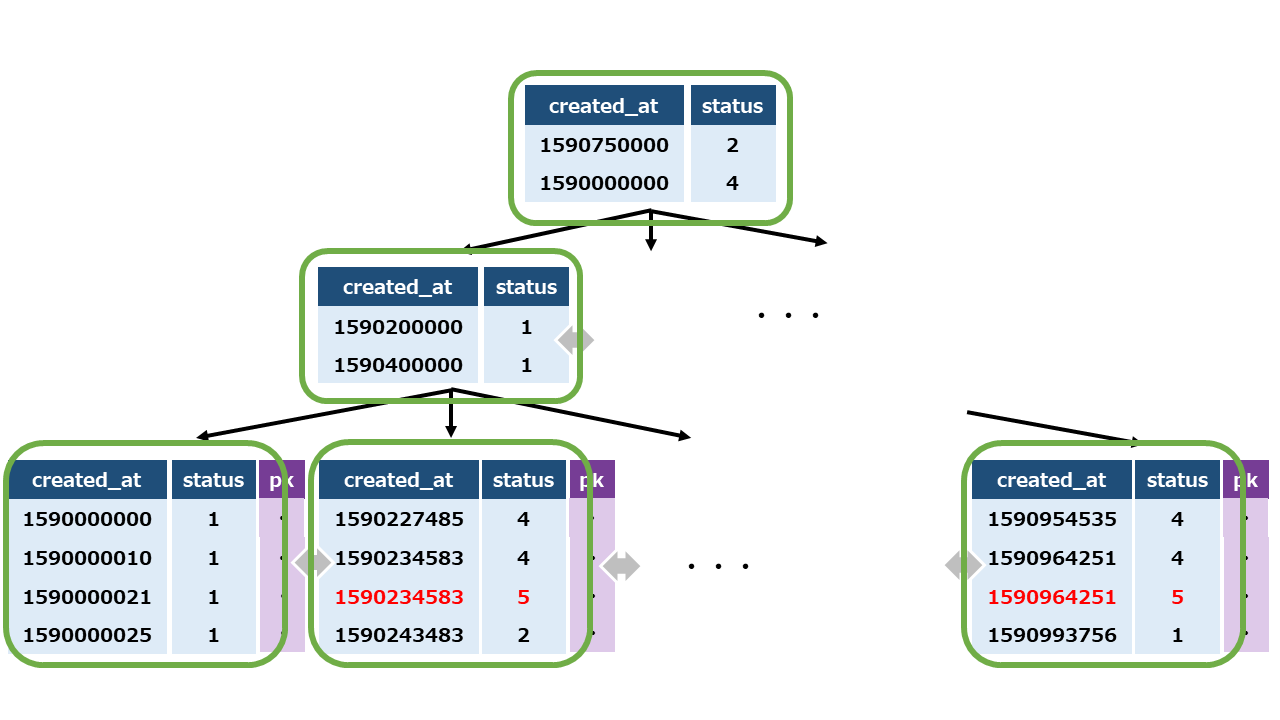
この複合インデックスは created_at、status の順に作られているので、このインデックスを使って status を効率的に検索することは難しいです。
通常、インデックスを効率的に利用できている場合には、データの量が増えても検索コストは緩やかにしか増えませんが、インデックスフルスキャンになっていると、データの増大に比例して検索コストが増大していきます。
物理テーブルを読み込まない分だけテーブルスキャンよりましではありますが、インデックスが想定した使われかたをしていない状態ですので、インデックスフルスキャンを見つけた場合にはインデックスを再度チューニングする必要があるものとおもいます。
チューニング指針
インデックスを効率的に利用するための指針として、以下のようなものがあるとおもいます。
-
EXPLAINのtypeがALLやindexになっていたら効率アップの余地がありそう。 -
EXPLAINのtypeがconst、ref、range等であればおおむね効率的なインデックス利用ができている。(ただ、rowsが大きければ注意) - 各カラムには数パターンの値しか格納されないのか、もしくは様々な値が格納されるのかといった値の多様性も考慮にいれて、より絞り込めるインデックスをつくる。
- 複合インデックスをつくるとき、
WHERE句にてイコールで絞り込むカラムを前半に配置する。 - 複合インデックスをつくるとき、
WHERE句で使うカラムを並べるだけでなく、どう絞り込むかということが、インデックスの使われ方に影響することに注意する。 - オプティマイザの処理は繊細で、SQLの不等号を逆にしただけで突然遅くなることもありえるので、アプリ改修とともにチューニングし続ける。