PostgreSQLのEXPLAIN ANALYZEの結果からactual timeを取り出す方法を紹介します。
ここでは正規表現の操作にサクラエディタを使用します。
1. 環境
- サクラエディタ Ver. 2.2.0.1
2. 正規表現を使用する対象のQUERY PLAN
PostgreSQLはSQLで、EXPLAINのANALYZEオプションを使用すると、プランナが推定するコストの精度を点検することができます。
以下のようにSELECT文等のSQL文の前に「EXPLAIN ANALYZE」を付けて実行すると、QUERY PLANを取得することができます。
EXPLAIN ANALYZE SELECT * FROM tenk1 t1, tenk2 t2
WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2 ORDER BY t1.fivethous;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=717.34..717.59 rows=101 width=488) (actual time=7.761..7.774 rows=100 loops=1)
Sort Key: t1.fivethous
Sort Method: quicksort Memory: 77kB
-> Hash Join (cost=230.47..713.98 rows=101 width=488) (actual time=0.711..7.427 rows=100 loops=1)
Hash Cond: (t2.unique2 = t1.unique2)
-> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244) (actual time=0.007..2.583 rows=10000 loops=1)
-> Hash (cost=229.20..229.20 rows=101 width=244) (actual time=0.659..0.659 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 28kB
-> Bitmap Heap Scan on tenk1 t1 (cost=5.07..229.20 rows=101 width=244) (actual time=0.080..0.526 rows=100 loops=1)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) (actual time=0.049..0.049 rows=100 loops=1)
Index Cond: (unique1 < 100)
Planning time: 0.194 ms
Execution time: 8.008 ms
テキストの途中に
actual time=7.761..7.774
と
「actual time=初期処理の実時間..全体の実時間(ミリ秒)」
の形式で出力されています。
今回は、この全体のテキストの中から、actual timeの後の値(上記では7.774)の「全体の実時間(ミリ秒)」を正規表現を使って抽出します。
3. 「actual time=初期処理の実時間..全体の実時間(ミリ秒)」の「全体の実時間(ミリ秒)」の抽出
3.1. 「actual time=数値..数値」が存在しない行の置換(先頭にタブを追加)
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=717.34..717.59 rows=101 width=488) (actual time=7.761..7.774 rows=100 loops=1)
Sort Key: t1.fivethous
Sort Method: quicksort Memory: 77kB
-> Hash Join (cost=230.47..713.98 rows=101 width=488) (actual time=0.711..7.427 rows=100 loops=1)
Hash Cond: (t2.unique2 = t1.unique2)
-> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244) (actual time=0.007..2.583 rows=10000 loops=1)
-> Hash (cost=229.20..229.20 rows=101 width=244) (actual time=0.659..0.659 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 28kB
-> Bitmap Heap Scan on tenk1 t1 (cost=5.07..229.20 rows=101 width=244) (actual time=0.080..0.526 rows=100 loops=1)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) (actual time=0.049..0.049 rows=100 loops=1)
Index Cond: (unique1 < 100)
Planning time: 0.194 ms
Execution time: 8.008 ms
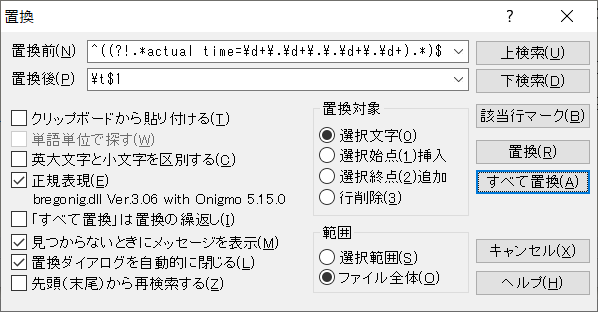
置換前:^((?!.*actual time=\d+\.\d+\.\.\d+\.\d+).*)$
置換後:\t$1
2025/01/22記載 以下の正規表現のほうが簡単でわかりやすかったです。
置換前:^(?!.*actual time=)(.*)
置換後:\t$1
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=717.34..717.59 rows=101 width=488) (actual time=7.761..7.774 rows=100 loops=1)
Sort Key: t1.fivethous
Sort Method: quicksort Memory: 77kB
-> Hash Join (cost=230.47..713.98 rows=101 width=488) (actual time=0.711..7.427 rows=100 loops=1)
Hash Cond: (t2.unique2 = t1.unique2)
-> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244) (actual time=0.007..2.583 rows=10000 loops=1)
-> Hash (cost=229.20..229.20 rows=101 width=244) (actual time=0.659..0.659 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 28kB
-> Bitmap Heap Scan on tenk1 t1 (cost=5.07..229.20 rows=101 width=244) (actual time=0.080..0.526 rows=100 loops=1)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) (actual time=0.049..0.049 rows=100 loops=1)
Index Cond: (unique1 < 100)
Planning time: 0.194 ms
Execution time: 8.008 ms
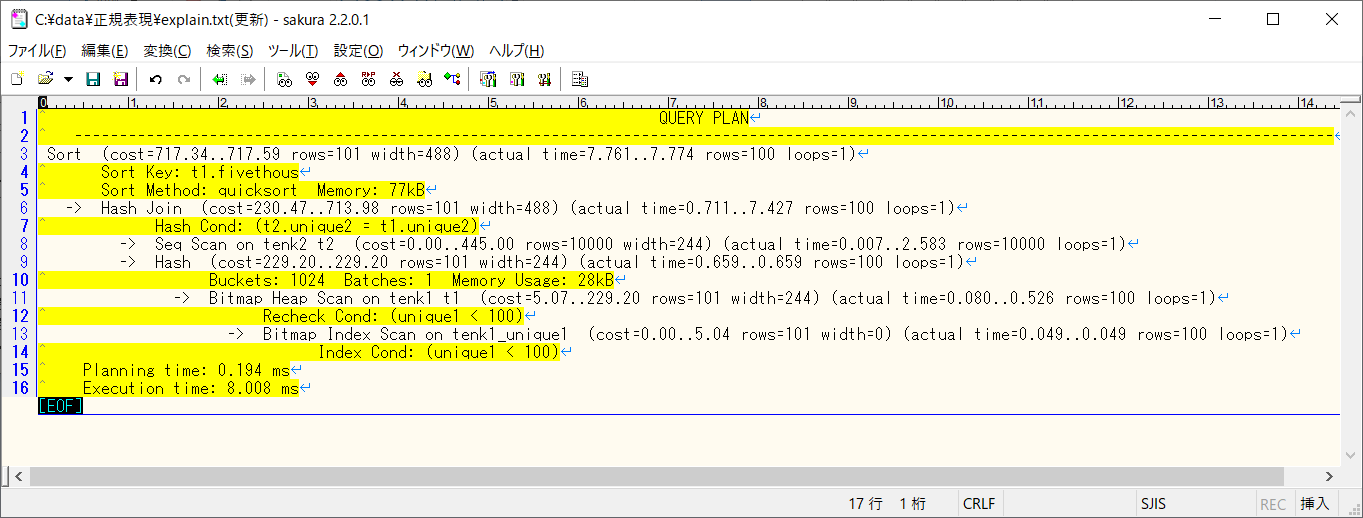
3.2. 「actual time=数値..数値」が存在する行の置換(先頭に数値 + タブ を追加)
置換前:^(.*actual time=\d+\.\d+\.\.)(\d+\.\d+)(.*)$
置換後:$2\t$1$2$3
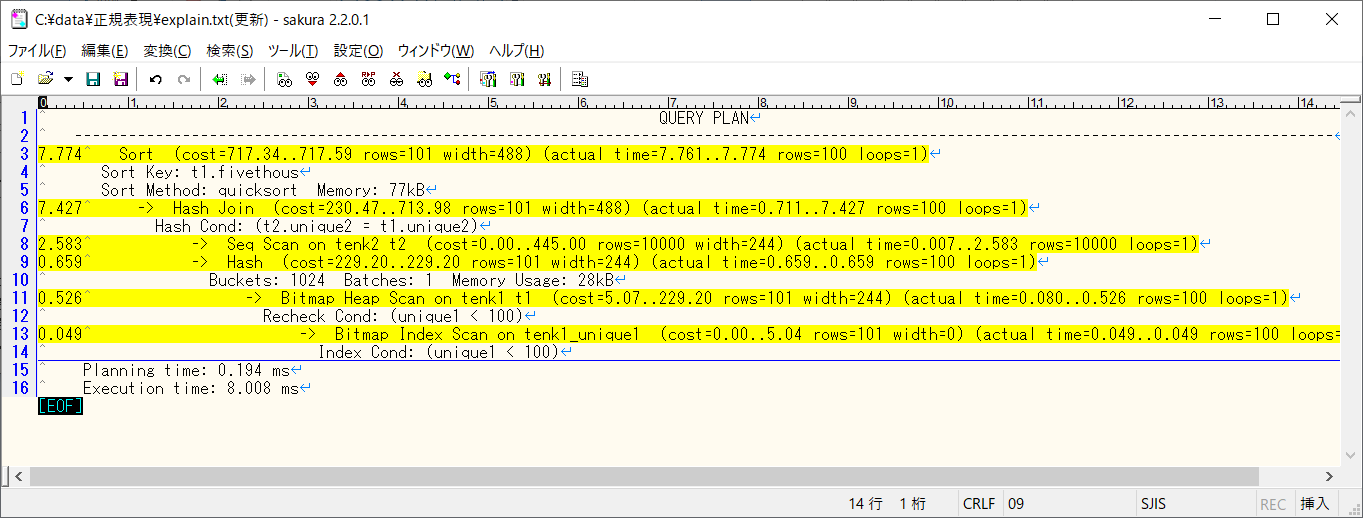
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
7.774 Sort (cost=717.34..717.59 rows=101 width=488) (actual time=7.761..7.774 rows=100 loops=1)
Sort Key: t1.fivethous
Sort Method: quicksort Memory: 77kB
7.427 -> Hash Join (cost=230.47..713.98 rows=101 width=488) (actual time=0.711..7.427 rows=100 loops=1)
Hash Cond: (t2.unique2 = t1.unique2)
2.583 -> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244) (actual time=0.007..2.583 rows=10000 loops=1)
0.659 -> Hash (cost=229.20..229.20 rows=101 width=244) (actual time=0.659..0.659 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 28kB
0.526 -> Bitmap Heap Scan on tenk1 t1 (cost=5.07..229.20 rows=101 width=244) (actual time=0.080..0.526 rows=100 loops=1)
Recheck Cond: (unique1 < 100)
0.049 -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) (actual time=0.049..0.049 rows=100 loops=1)
Index Cond: (unique1 < 100)
Planning time: 0.194 ms
Execution time: 8.008 ms
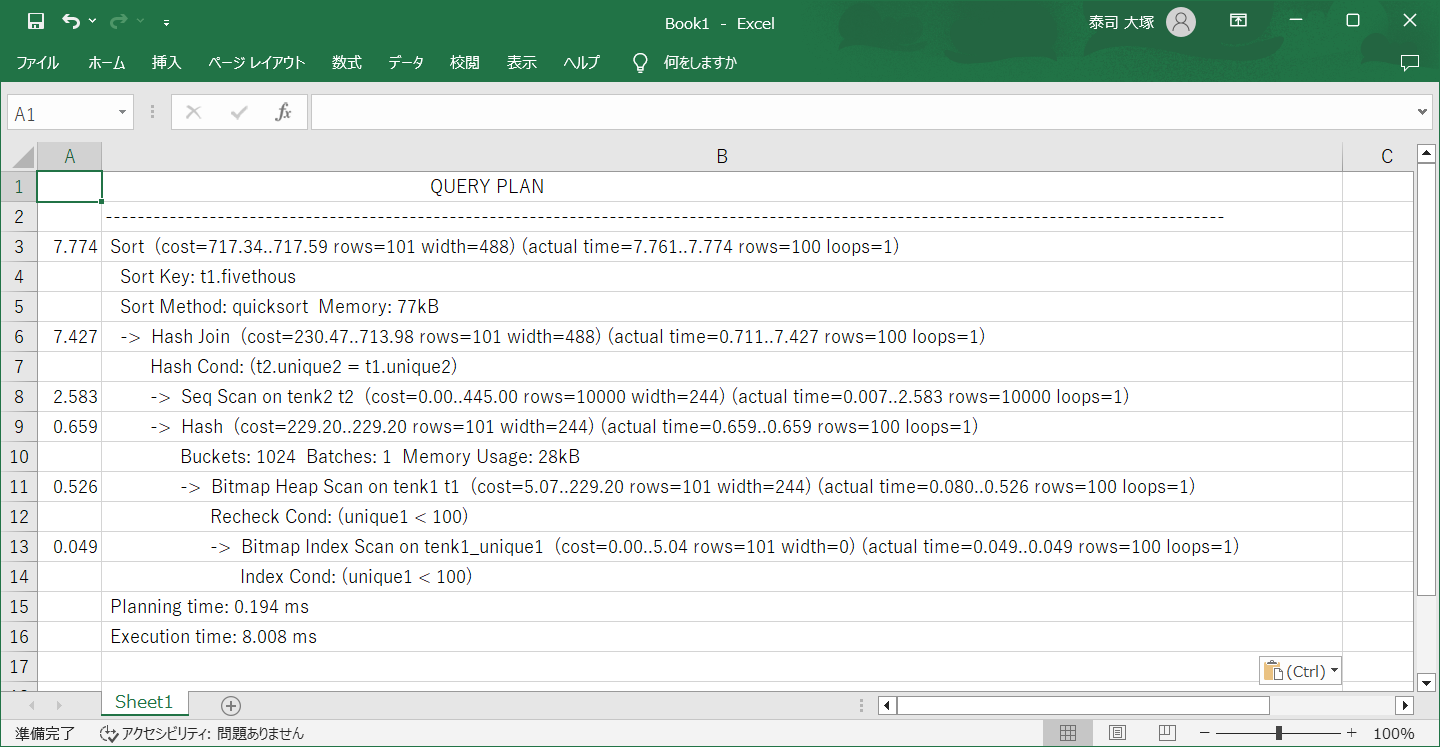
置換したテキストはタブ区切りなので、そのままExcelに張り付けると列がわかれてくれます。
A列がactual timeの「全体の実時間(ミリ秒)」、B列がもとの文字列 となっています。
4. 正規表現の説明
4.1. 1回目の置換の正規表現
置換前:^((?!.*actual time=\d+\.\d+\.\.\d+\.\d+).*)$
置換後:\t$1
actual time=小数点有り数値..小数点有り数値を含まない行をマッチさせるには、以下で検索します。
^(?!.*actual time=\d+\.\d+\.\.\d+\.\d+).*$
ここで
-
^:先頭 -
(?!xxx):xxxが存在しない -
.*:任意の文字列の0回以上の繰り返し -
actual time=:「actual time=」の文字列 -
\d+:数字の1回以上の繰り返し -
\.:「.」の文字(エスケープ) -
\d+:数字の1回以上の繰り返し -
\.:「.」の文字(エスケープ) -
\.:「.」の文字(エスケープ) -
\d+:数字の1回以上の繰り返し -
\.:「.」の文字(エスケープ) -
\d+:数字の1回以上の繰り返し -
.*:任意の文字列の0回以上の繰り返し -
$:行末
となります。
置換後に元の文字列を取得したいため、()を付与します。
^((?!.*actual time=\d+\.\d+\.\.\d+\.\d+).*)$
そうすると、先頭から行末の間の文字列を$1で受け取ることができます。
置換後の文字列を\t$1とすることで、タブ + 元の文字列に置換します。
4.2. 2回目の置換の正規表現
置換前:^(.*actual time=\d+\.\d+\.\.)(\d+\.\d+)(.*)$
置換後:$2\t$1$2$3
actual time=小数点有り数値..小数点有り数値を含む行をマッチさせるには、以下で検索します。
^.*actual time=\d+\.\d+\.\.\d+\.\d+.*$
ここで
-
^:先頭 -
.*:任意の文字列の0回以上の繰り返し -
actual time=:「actual time=」の文字列 -
\d+:数字の1回以上の繰り返し -
\.:「.」の文字(エスケープ) -
\d+:数字の1回以上の繰り返し -
\.:「.」の文字(エスケープ) -
\.:「.」の文字(エスケープ) -
\d+:数字の1回以上の繰り返し -
\.:「.」の文字(エスケープ) -
\d+:数字の1回以上の繰り返し -
.*:任意の文字列の0回以上の繰り返し -
$:行末
となります。
actual timeの2つ目の数値と元の文字列を取得したいため、()を付与します。
^(.*actual time=\d+\.\d+\.\.)(\d+\.\d+)(.*)$
置換後の文字列を$2\t$1$2$3とすることで、
actual timeの2つ目の数値 + タブ + 元の文字列
に置換します。
($1:1つ目の()内の文字列、$2:2つ目の()内の文字列、$3:3つ目の()内の文字列)
以上