最近、X で話題になっていた NVIDIA SLANG(HLSLに似た言語からさまざまなターゲットシェーディング言語にコンパイル可能)に興味を持ち、調査と実験を行いました。
今回は、変換結果がわかりやすいGLSL(Shadertoyフォーマット)を対象に試してみました。
テスト環境
- OS: macOS Sequoia 15.1
テスト内容
フラグメントシェーダーを使用した例で以下の手順を行いました:
- SLANG から GLSL に変換。
- Shadertoy 用の GLSL に調整(半手動での編集)。
SLANG は頂点シェーダーやコンピュートシェーダーの変換もサポートしており、Metal の Mesh Shader 変換にも対応しています。
SLANG 公式サイト
SLANG の書き方
SLANG の記述方法は、HLSL とほぼ同一です。
SLANG コンパイラーのダウンロード
注意点
シェーダーの種類を明示するため、imageMain 関数の前に以下を追加する必要があります:
-
フラグメントシェーダー:
[shader("fragment")] -
頂点シェーダー:
[shader("vertex")] -
コンピュートシェーダー:
[shader("compute")]
これを指定しないと、slangc コマンド実行時にエラーが発生します。
テスト用シェーダー: test.slang
以下は、UV を極座標変換し、「PY」ロゴを距離関数で描画・アニメーション化したフラグメントシェーダーの例です:
cbuffer TimeBuffer
{
float iTime;
}
#define T iTime
#define Rot(a) float2x2(cos(a - float4(0,11,33,0)))
#define B(p,s) max(abs(p).x-s.x,abs(p).y-s.y)
#define PUV(p) float2(log(length(p)),atan(p.y/p.x))
float mod2(float a, float b) {
return a - b * floor(a / b);
}
float Hash(float2 p){
float2 randP = fract(sin(p*123.456)*567.89);
randP += dot(randP,randP*34.56);
float n = fract(randP.x*randP.y);
return n;
}
// thx iq! https://iquilezles.org/articles/distfunctions2d/
float sdBox( float2 p, in float2 b )
{
float2 d = abs(p)-b;
return length(max(d,0.0)) + min(max(d.x,d.y),0.0);
}
// thx iq! https://iquilezles.org/articles/distfunctions2d/
float sdRoundedBox( float2 p, in float2 b, float4 r )
{
r.xy = (p.x>0.0)?r.xy : r.zw;
r.x = (p.y>0.0)?r.x : r.y;
float2 q = abs(p)-b+r.x;
return min(max(q.x,q.y),0.0) + length(max(q,0.0)) - r.x;
}
// thx iq! https://iquilezles.org/articles/distfunctions/
float opSmoothSubtraction( float d1, float d2, float k )
{
float h = clamp( 0.5 - 0.5*(d2+d1)/k, 0.0, 1.0 );
return lerp( d2, -d1, h ) + k*h*(1.0-h);
}
float stripes(float2 p, float dir, float space, float s){
float2 prevP = p;
p = mul(p,Rot(radians(30.)));
p.x += T*0.1*dir;
p.x = mod2(p.x,space)-(space*0.5);
float d = B(p,float2(s,20.));
return d;
}
float dots(float2 p){
float space = 0.1;
p -= T*0.1;
p.x = mod2(p.x,space)-(space*0.5);
p.y = mod2(p.y,space)-(space*0.5);
float d = length(p)-0.03;
return d;
}
float charP(float2 p){
float d = sdBox(p,float2(0.015,0.08));
p -= float2(0.0,0.03);
float d2 = abs(sdRoundedBox(p,float2(0.08,0.035),float4(0.035,0.035,0.0,0.0)))-0.015;
d2 = max(-p.x,d2);
d = min(d,d2);
return d-0.003;
}
float charY(float2 p){
float2 prevP = p;
p += float2(0.0,0.05);
float d = sdBox(p,float2(0.015,0.03));
p = prevP;
p -= float2(0.0,0.03);
float d2 = sdBox(p,float2(0.08,0.05));
float a = radians(-30.0);
p -= float2(0.014,0.0);
d2 = opSmoothSubtraction(dot(p,float2(cos(a),sin(a))),d2,0.003);
p = prevP;
p -= float2(0.027,0.0);
d2 = opSmoothSubtraction(-dot(p,float2(cos(a),sin(a))),d2,0.003);
d = min(d,d2);
return d-0.003;
}
float py(float2 p){
p*=0.28;
p = mul(p,Rot(radians(-90.0)));
float2 prevP = p;
p -= float2(-0.06,0.0);
float d = charP(p);
p = prevP;
p -= float2(0.06,0.0);
float d2 = charY(p);
d = min(d,d2);
return d;
}
float largeP(float2 p){
p*=0.25;
p = mul(p,Rot(radians(-90.0)));
float d = charP(p);
return d;
}
float largeY(float2 p){
p*=0.25;
p = mul(p,Rot(radians(-90.0)));
float d = charY(p);
return d;
}
float pys(float2 p, float n){
float time = T;
p.y += time*n*0.3;
p.y+=0.5;
p.y = fmod(p.y,1.0)-0.5;
p*=2.0;
float2 prevP = p;
p = abs(p)-0.5;
p*=float2(sign(prevP.x),sign(prevP.y));
float d = py(p);
return d;
}
float bg(float2 p){
p = mul(p,Rot(radians(10.*T)));
p = PUV(p);
p.x-=T*0.25;
p*=2.54*5.;
float2 id = floor(p);
p = fract(p)-0.5;
float n = Hash(id);
float lineW = 0.1;
n*=0.5;
n += Hash(id)*0.5;
if(n<0.5 || n>=0.8){
float dir = (n>=0.8)?1.0:-1.0;
p = mul(p,Rot(radians(dir*45.0)));
p.x = abs(p.x);
p.x-=0.355;
lineW = 0.1;
}
lineW*=0.5;
float d = max(-(p.x+(lineW*0.5)),(p.x-(lineW*0.5)));
return d;
}
float draw(float2 p){
float time = T;
p = mul(p,Rot(radians(10.*time)));
p = PUV(p);
p.x-=time*0.2;
p*=2.54;
float2 id = floor(p);
float n = clamp(Hash(id),0.2,1.0);
p = fract(p)-0.5;
float d = py(p);
if(n<=0.6){
d = lerp(d,largeP(p),clamp(sin(3.*time*n),0.0,1.0));
if(n>=0.5){
float d2 = d;
d = max(dots(p),d);
d = min(d,abs(d2)-0.002);
}
} else if(n>=0.6 && n<0.9) {
d = lerp(d,largeY(p),clamp(sin(3.*time*n),0.0,1.0));
d = max(stripes(p,-1.0,0.05,0.005),d);
} else if(n>=0.9) {
d = pys(p,n*0.5);
}
return d;
}
[shader("fragment")]
float4 imageMain(uint2 dispatchThreadID, int2 screenSize)
{
float2 p = (dispatchThreadID.xy - 0.5 * screenSize.xy) / (float)screenSize.y;
float3 col = float3(0.0,0.0,0.0);
float d = bg(p);
col = lerp(col,float3(0.3,0.3,0.3),1.0-smoothstep(-1.2,1.2, d*(float)screenSize.y));
d = draw(p);
col = lerp(col,float3(1.0,1.0,1.0),1.0-smoothstep(-1.2,1.2, d*(float)screenSize.y));
d = length(p)-0.05;
col = lerp(col,float3(0.0,0.0,0.0),1.0-smoothstep(0.,0.3,d));
return float4(col.r, col.g, col.b, 1.0);
}
Playground でのテスト
SLANG Playground を使用して動作確認が可能です。テストするには、xxx.slang の内容を以下のポイントを参考に調整してください。
-
import playgroundを追加。 -
cbuffer TimeBufferの箇所を削除。 -
time変数をマクロ関数で定義(例:#define T getTime())。 -
[shader("fragment")]を削除。
また、ブラウザの WebGPU 設定が OFF になっている場合、動作しないことがあります。その場合は WebGPU を ON に設定して再確認してください。最新の Chrome では、特に設定を変更せずに動作することを確認しました。
GLSL への変換手順
- ダウンロードしたコンパイラーは
bin/ディレクトリに保存されています。 - ターミナルで
bin/に移動し、以下のコマンドを実行します:
./slangc test.slang -profile glsl_150 -target glsl -o test.glsl -entry imageMain -line-directive-mode none
.metalで書き出す場合 参考:
./slangc test.slang -target metal -o test.metal -entry imageMain -line-directive-mode none
3.生成された GLSL コードからShadertoy用の
フォーマットに変換(slangに記載したコメントは自動で削除されて出力されるみたいです。):
sed -e '/^ *[a-z]* layout\(.*\);*$/d' \
-e '/^ *[a-z]* layout.*$/d' \
-e '/^ *layout.*$/d' \
-e 's/dispatchThreadID_0/fragCoord/g' \
-e 's/screenSize_0/iResolution/g' \
-e 's/TimeBuffer_0.iTime_0/iTime/g' \
-e 's/^void main()/void mainImage(out vec4 fragColor, in vec2 fragCoord)/' test.glsl > test_output.glsl
Shadertoy用最終コード
出力されたコードからShadertoy用のフォーマットに変換し、手動で調整した結果、以下の GLSL コードが完成しました。このコードを Shadertoy にコピー&ペーストすることで動作を確認できます:
float Hash_0(vec2 p_0)
{
vec2 _S1 = fract(sin(p_0 * 123.45600128173828125) * 567.8900146484375);
vec2 randP_0 = _S1 + dot(_S1, _S1 * 34.56000137329101562);
return fract(randP_0.x * randP_0.y);
}
float bg_0(vec2 p_1)
{
vec2 _S2 = p_1;
const vec4 _S3 = vec4(0.0, 11.0, 33.0, 0.0);
vec4 _S4 = cos(radians(10.0 * iTime) - _S3);
mat2x2 _S5;
_S5[0] = _S4.xy;
_S5[1] = _S4.zw;
vec2 _S6 = (((_S5) * (p_1)));
_S2 = vec2(log(length(_S6)), atan(_S6.y / _S6.x));
_S2[0] = _S2[0] - iTime * 0.25;
vec2 _S7 = _S2 * 12.69999980926513672;
vec2 id_0 = floor(_S7);
_S2 = fract(_S7) - 0.5;
float n_0 = Hash_0(id_0) * 0.5;
float n_1 = n_0 + n_0;
bool _S8;
if(n_1 < 0.5)
{
_S8 = true;
}
else
{
_S8 = n_1 >= 0.80000001192092896;
}
if(_S8)
{
float dir_0;
if(n_1 >= 0.80000001192092896)
{
dir_0 = 1.0;
}
else
{
dir_0 = -1.0;
}
vec4 _S9 = cos(radians(dir_0 * 45.0) - _S3);
mat2x2 _S10;
_S10[0] = _S9.xy;
_S10[1] = _S9.zw;
vec2 _S11 = (((_S10) * (_S2)));
_S2 = _S11;
_S2[0] = abs(_S11.x) - 0.35499998927116394;
}
return max(- (_S2.x + 0.02500000037252903), _S2.x - 0.02500000037252903);
}
float sdBox_0(vec2 p_2, vec2 b_0)
{
vec2 d_0 = abs(p_2) - b_0;
return length(max(d_0, vec2(0.0))) + min(max(d_0.x, d_0.y), 0.0);
}
float sdRoundedBox_0(vec2 p_3, vec2 b_1, vec4 r_0)
{
vec4 _S12 = r_0;
vec2 _S13;
if(p_3.x > 0.0)
{
_S13 = _S12.xy;
}
else
{
_S13 = _S12.zw;
}
_S12.xy = _S13;
float _S14;
if(p_3.y > 0.0)
{
_S14 = _S12.x;
}
else
{
_S14 = _S12.y;
}
_S12[0] = _S14;
vec2 q_0 = abs(p_3) - b_1 + _S12.x;
return min(max(q_0.x, q_0.y), 0.0) + length(max(q_0, vec2(0.0))) - _S12.x;
}
float charP_0(vec2 p_4)
{
vec2 _S15 = p_4 - vec2(0.0, 0.02999999932944775);
return min(sdBox_0(p_4, vec2(0.01499999966472387, 0.07999999821186066)), max(- _S15.x, abs(sdRoundedBox_0(_S15, vec2(0.07999999821186066, 0.03500000014901161), vec4(0.03500000014901161, 0.03500000014901161, 0.0, 0.0))) - 0.01499999966472387)) - 0.00300000002607703;
}
float opSmoothSubtraction_0(float d1_0, float d2_0, float k_0)
{
float h_0 = clamp(0.5 - 0.5 * (d2_0 + d1_0) / k_0, 0.0, 1.0);
return mix(d2_0, - d1_0, h_0) + k_0 * h_0 * (1.0 - h_0);
}
float charY_0(vec2 p_5)
{
vec2 _S16 = p_5 - vec2(0.0, 0.02999999932944775);
float a_0 = radians(-30.0);
vec2 _S17 = vec2(cos(a_0), sin(a_0));
return min(sdBox_0(p_5 + vec2(0.0, 0.05000000074505806), vec2(0.01499999966472387, 0.02999999932944775)), opSmoothSubtraction_0(- dot(p_5 - vec2(0.02700000070035458, 0.0), _S17), opSmoothSubtraction_0(dot(_S16 - vec2(0.01400000043213367, 0.0), _S17), sdBox_0(_S16, vec2(0.07999999821186066, 0.05000000074505806)), 0.00300000002607703), 0.00300000002607703)) - 0.00300000002607703;
}
float py_0(vec2 p_6)
{
vec2 _S18 = p_6 * 0.2800000011920929;
vec4 _S19 = cos(radians(-90.0) - vec4(0.0, 11.0, 33.0, 0.0));
mat2x2 _S20;
_S20[0] = _S19.xy;
_S20[1] = _S19.zw;
vec2 _S21 = (((_S20) * (_S18)));
return min(charP_0(_S21 - vec2(-0.05999999865889549, 0.0)), charY_0(_S21 - vec2(0.05999999865889549, 0.0)));
}
float largeP_0(vec2 p_7)
{
vec2 _S22 = p_7 * 0.25;
vec4 _S23 = cos(radians(-90.0) - vec4(0.0, 11.0, 33.0, 0.0));
mat2x2 _S24;
_S24[0] = _S23.xy;
_S24[1] = _S23.zw;
return charP_0((((_S24) * (_S22))));
}
float mod2_0(float a_1, float b_2)
{
return a_1 - b_2 * floor(a_1 / b_2);
}
float dots_0(vec2 p_8)
{
vec2 _S25 = p_8;
vec2 _S26 = p_8 - iTime * 0.10000000149011612;
_S25 = _S26;
_S25[0] = mod2_0(_S26.x, 0.10000000149011612) - 0.05000000074505806;
_S25[1] = mod2_0(_S25.y, 0.10000000149011612) - 0.05000000074505806;
return length(_S25) - 0.02999999932944775;
}
float largeY_0(vec2 p_9)
{
vec2 _S27 = p_9 * 0.25;
vec4 _S28 = cos(radians(-90.0) - vec4(0.0, 11.0, 33.0, 0.0));
mat2x2 _S29;
_S29[0] = _S28.xy;
_S29[1] = _S28.zw;
return charY_0((((_S29) * (_S27))));
}
float stripes_0(vec2 p_10, float dir_1, float space_0, float s_0)
{
vec4 _S30 = cos(radians(30.0) - vec4(0.0, 11.0, 33.0, 0.0));
mat2x2 _S31;
_S31[0] = _S30.xy;
_S31[1] = _S30.zw;
vec2 _S32 = (((_S31) * (p_10)));
_S32[0] = _S32[0] + iTime * 0.10000000149011612 * dir_1;
_S32[0] = mod2_0(_S32.x, space_0) - space_0 * 0.5;
return max(abs(_S32).x - s_0, abs(_S32).y - 20.0);
}
float pys_0(vec2 p_11, float n_2)
{
vec2 _S33 = p_11;
_S33[1] = _S33[1] + iTime * n_2 * 0.30000001192092896 + 0.5;
float _S34 = _S33.y;
_S33[1] = ((((_S34) < 0.0) ? -mod(-(_S34),abs((1.0))) : mod((_S34),abs((1.0))))) - 0.5;
vec2 _S35 = _S33 * 2.0;
vec2 _S36 = (abs(_S35) - 0.5) * vec2(float((int(sign((_S35.x))))), float((int(sign((_S35.y))))));
_S33 = _S36;
return py_0(_S36);
}
float draw_0(vec2 p_12)
{
vec2 _S37 = p_12;
float time_0 = iTime;
vec4 _S38 = cos(radians(10.0 * iTime) - vec4(0.0, 11.0, 33.0, 0.0));
mat2x2 _S39;
_S39[0] = _S38.xy;
_S39[1] = _S38.zw;
vec2 _S40 = (((_S39) * (p_12)));
_S37 = vec2(log(length(_S40)), atan(_S40.y / _S40.x));
_S37[0] = _S37[0] - time_0 * 0.20000000298023224;
vec2 _S41 = _S37 * 2.53999996185302734;
float n_3 = clamp(Hash_0(floor(_S41)), 0.20000000298023224, 1.0);
vec2 _S42 = fract(_S41) - 0.5;
_S37 = _S42;
float d_1 = py_0(_S42);
float d_2;
if(n_3 <= 0.60000002384185791)
{
float d_3 = mix(d_1, largeP_0(_S37), clamp(sin(3.0 * time_0 * n_3), 0.0, 1.0));
if(n_3 >= 0.5)
{
d_2 = min(max(dots_0(_S37), d_3), abs(d_3) - 0.0020000000949949);
}
else
{
d_2 = d_3;
}
}
else
{
bool _S43;
if(n_3 >= 0.60000002384185791)
{
_S43 = n_3 < 0.89999997615814209;
}
else
{
_S43 = false;
}
if(_S43)
{
d_2 = max(stripes_0(_S37, -1.0, 0.05000000074505806, 0.00499999988824129), mix(d_1, largeY_0(_S37), clamp(sin(3.0 * time_0 * n_3), 0.0, 1.0)));
}
else
{
if(n_3 >= 0.89999997615814209)
{
d_2 = pys_0(_S37, n_3 * 0.5);
}
else
{
d_2 = d_1;
}
}
}
return d_2;
}
void mainImage(out vec4 fragColor, in vec2 fragCoord)
{
float _S44 = float(iResolution.y);
vec2 p_13 = (vec2(fragCoord.xy) - 0.5 * vec2(iResolution.xy)) / _S44;
const vec3 col_0 = vec3(0.0, 0.0, 0.0);
vec3 col_1 = mix(mix(mix(col_0, vec3(0.30000001192092896, 0.30000001192092896, 0.30000001192092896), vec3(1.0 - smoothstep(-1.20000004768371582, 1.20000004768371582, bg_0(p_13) * _S44))), vec3(1.0, 1.0, 1.0), vec3(1.0 - smoothstep(-1.20000004768371582, 1.20000004768371582, draw_0(p_13) * _S44))), col_0, vec3(1.0 - smoothstep(0.0, 0.30000001192092896, length(p_13) - 0.05000000074505806)));
fragColor = vec4(col_1.x, col_1.y, col_1.z, 1.0);
return;
}
変換されたGLSLコードを見ると、マクロ関数がそのまま展開され、コード量が増加していることが分かります。そのため、xxx.slangを記述する際には、マクロ化を避け、再利用可能な通常の関数として定義する方が良いかもしれません。こうすることで、変換後のコード量を抑えることが可能です。また、コマンドオプションでこの問題を回避する設定があるかもしれません。さらに、NVIDIAのドキュメントには具体的な対応策が記載されている可能性があるため、興味のある方はぜひ詳細を確認してみてください。
Shadertoyでの実行結果:
PYロゴアニメーション

SPIR-V
SPIR-V を利用して変換を行う方法もあります。SPIR-V に変換し、その後、以下のクロスコンパイラを使用してコンパイルを行うことで、直接活用することが可能そうです。詳細については、以下を参考にしてください:
SPIR-V Cross
おまけ
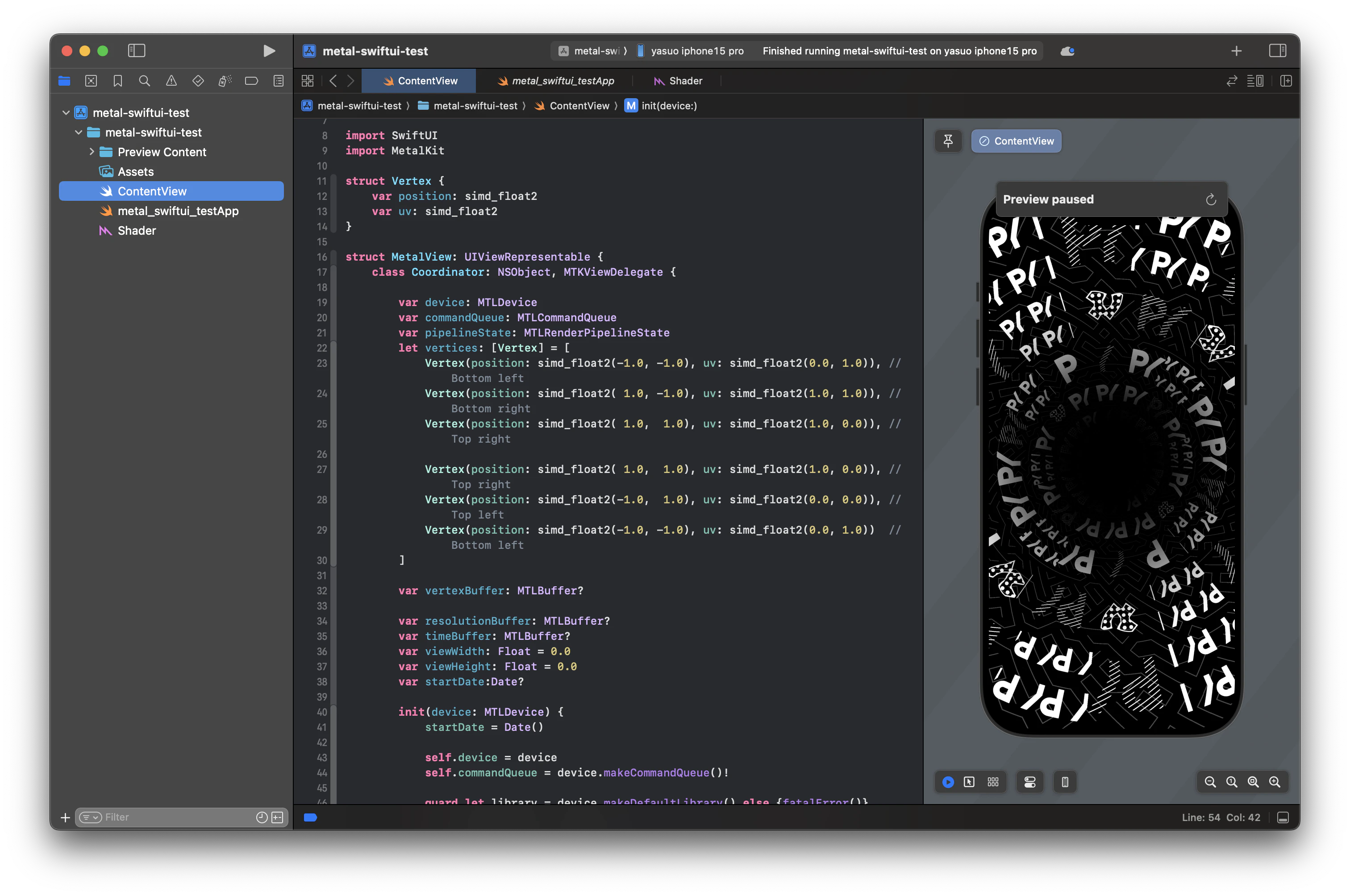
試しに、Metalで書き出し、SwiftUIを使って、Slangで変換されたファイルをQuadに描画してみました。Metal側の実装をSlangで書き出された形式に合わせる必要があったため、今回はこちらで実装したMetalの描画に適した形にファイルを調整し、出力を行いました。
完全に手作業でMetalシェーダーにポートするよりも手間が少なく、Metalシェーダーとして活用できる点で、これでも悪くない方法だと感じました。
まとめ
HLSL をベースに他のシェーダー言語へ変換できる SLANG は、既存の HLSL 資産を活用できる点で非常に魅力的です。これまでは SPIR-V 経由や Python などのツールを用いて独自に変換作業を行う必要がありましたが、SLANG を導入することで、シェーダー言語の変換がより効率的に行える可能性を感じました。