概要
SBC(Single Board Computer)ですので、Deep Learningといってもトレーニングのパフォーマンスではなく主にインファレンス(推定)の速度が気になります。インファレンスはできるだけ、実際のイベントの近くで実行したいという思いがあります。ただ、インファレンスといってもDeep Learningの場合、モデルが大きく、メモリやCPUの速度は必要です。できるだけチューニングして、インファレンスの速度を比較してみました。
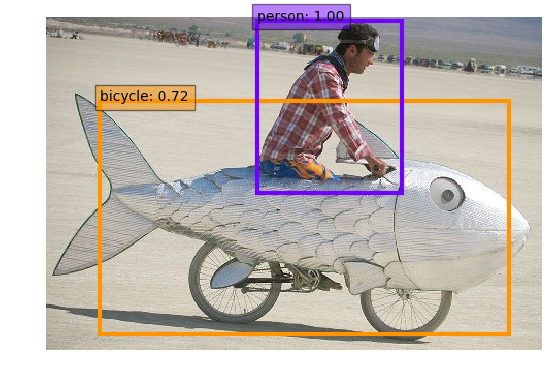
MXNET上の実装のSSD(Single Shut Mutibox Detector)になります。
以下からクローンしてビルドします。
https://githhub.com/zreshold/mxnet-ssd
手順はこちらを参照ください
また、SBCにはUbuntuを構成しました。(beagle born blackはUbuntu 14.04です。それ以外は16.04相当になります)
| SBC | CPU | Memory |
|---|---|---|
| Raspberry Pi3 | ARM Cortex-A53 1.2GHz 4Core | 1GB |
| pcDuino4 | ARM Cortex-A7 1.5GHz 4Core | 1GB |
| PINE64+ | ARM Cortex-A53 1.2GHz 4Core | 2GB |
| Beagle Born Black | ARM Cortex-A8 1.0GHz 1Core | 512MB |
| odroid XU4 | ARM Coretex-A15/A7 4Core/4Core | 2GB |
![WP_20170424_17_15_30_Pro[94].jpg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.amazonaws.com%2F0%2F177932%2Fe0e01511-8aad-d6c8-ba0b-3e01b63e7540.jpeg?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=2db40d3cc3e5373159a75b77fae5d035)
(左上からRaspberry Pi3 pcDuino4 PINE64 Beagle Born Black)
評価と比較
MXNETでの実装のSSDですが、パラメータをいくつか試してみましたが、openblasを使うのが一番高速でした。その結果から、以下のパラメータでビルドします。
config.mkの中で以下は下記となっていると思います。
USE_OPENMP = 1
標準での線形計算ライブラリとしてatlasが使われていますが、openblasに変更します。
UNAME_S := $(shell uname -s)
ifeq ($(UNAME_S), Darwin)
USE_BLAS = apple
else
USE_BLAS = openblas
endif
標準ではインストールされていないと思いますので、記事の手順に加えて下記を構成しておきます。
``sudo apt-get install libopenblas-dev```
demo.pyを使って、何度か実行し、平均の実行時間を下記に示します。beagle born blackはスペック的にはぎりぎりのようで、Swap領域を広げないと動作はしない状況でした。SBCではないですが、IntelのCompute Stickでの実行結果も比較のため提示しておきます。
| SBC | 実行時間 |
|---|---|
| Raspberry Pi3 | 14s |
| pcDuino4 | 34s |
| PINE64+ | 8s |
| Beagle Born Black | 180s |
| odroid XU4 | 12s |
| Intel Compute Stick(CSTK-32W) | 8s |
カタログスペック上、Raspberry Pi3とほぼ同じはずのPine64が一番高速でした。OSが64bit化されているのが大きいのかもしれません。
odroid-XU4は8Coreでスペック的には一番有利ですが、非対称であることが災いしているのか、ほとんどRaspberry Piと変わらない実行時間でした。
動画の処理には無理がありますが、10秒程度で処理が終わるのであれば、静止画で監視用途等であれば。使える領域もあると考えられます。
また一台がかなり安いですのでEdgeの配置して最低限の処理を実行させるという方向で使えそうです。