モチベーション
なぜGoogle Meetの背景ぼかしが最強なのか
ブラウザでリアルタイムストリーミングにも耐えうるMLモデルを動かした背景分離の実装は、tensorflow.jsでwebGLを使ったbodypixがありましたが、360pがやっとでそれでもCPU負荷が高い状態になっていました。しかし、Google Meetの背景ぼかし機能の初期リリース 2020.4月頃では4倍の720pで精度も十分なモデルが実装されていました。更に2020.10月のアップデートでCPU負荷が非常に低い高速になっていたことの技術的背景を掘り下げた面白い記事です。
その記事では、Background Features in Google Meet, Powered by Web MLブログの解説を更に詳細に解説されています。
コア技術には、ブラウザ上でストリーム処理時の推論を効率よく実行出来るように、MediaPipeというフレームワークでWASMとして実現していることがあげられています。その推論処理はXNNPACKやTensorflow Liteが使われ、レンダリングにはWebGLを使って背景ぼかし機能が実現されています。
MediaPipeではWebAssemblyとして、C/C++, Rustなどで作ったブラウザ用のバイナリ(WASM)に変換して実行させることが可能で、この時点でJavaScriptよりもベースのパフォーマンスが向上することになります。更に肝心の推論処理について、Tensorflow Lite+XNNPACKをベースとしたCPUに対してSIMD(ベクトル)命令など使っているという点もパフォーマンスに大きく影響しているらしいです。
という前置きから、
この記事では、TensorFlow Liteと組み合わせて使うと幸せになれそうな XNNPACKについて掘り下げて理解したいという意図から書きました。
概要
XNNPACK は、ARM、WebAssembly、およびx86プラットフォーム用のニューラルネットワーク推論において、浮動小数点での演算を高度に最適化したライブラリです。 XNNPACKは、ディープラーニングの実践者や研究者が直接使用することを目的としたものではありません。代わりに、TensorFlow Lite、TensorFlow.js、PyTorch、MediaPipeなどの高レベルの機械学習フレームワークを高速化するための低レベルのパフォーマンスプリミティブを提供します。
Supported Architectures
- ARM64 on Android, Linux, and iOS (including WatchOS and tvOS)
- ARMv7 (with NEON) on Android, Linux, and iOS (including WatchOS)
- x86 and x86-64 (up to AVX512) on Windows, Linux, macOS, Android, and iOS simulator
- WebAssembly MVP
- WebAssembly SIMD (experimental)
まずはどの辺りが演算を高度に最適化してるかを調べてみました。
詳細
QNNPACKをベースにしているため、まずはQNNPACKについて
QNNPACKとは
- QNNPACKはFacebookが作った、モバイル向けに最適化された高速化カーネルライブラリ
- NNで使用する深さ方向の畳み込みなどに有効な高速化
- NNPACKを元にしている。
- Winograd変換、高速フーリエ変換のいずれかに基づく漸近的な高速な畳み込みアルゴリズムであり、neonやcuDNNにも採用されているもの
- 1x1より大きいカーネルの畳み込みの場合に使用されるim2colと呼ばれるメモリレイアウト変換を、より高速化する方法が使われている。(下で多少詳しく説明します)
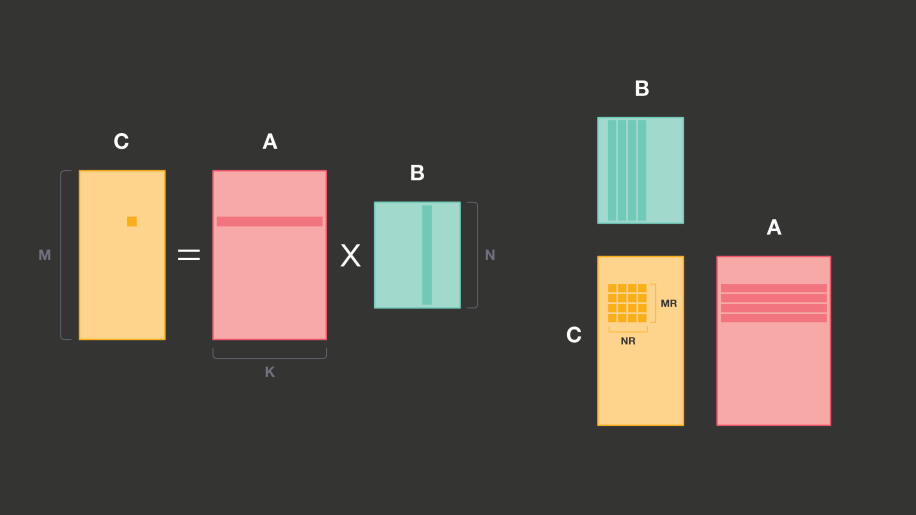
- 畳み込みNNでの効率的な推論の問題は、主に行列×行列乗算の効率的な実装の問題であり、線形代数ライブラリ(BLAS)ではGEMM(General matrix multiply)という
行列×行列乗算の実装
PDOT(panel dot product) microkernel: 行列x行列乗算において、各要素毎の積をベクトル演算命令(最大値はレジスタの数やプロセッサアーキテクチャによって制限あり)をうまく使って、行列内の小さいpanel毎(MR x NR)に積を取る
量子化
-
低精度の整数演算を使用して推論する。単精度、半精度の浮動小数点に比べてフットプリントが小さく、モバイルプロセッサの小さなキャッシュにNNモデルを保持出来る。メモリ帯域幅に制限された操作のパフォーマンスやエネルギー効率が向上し、計算スループットが高くなる。Android Neural Networks APIと互換性ある線形量子化スキームを使っている。
-
$ r[i]=scale * (q[i] - \texttt{zero_point}) $ 量子化された値 $q[i]$ は8ビットの符号なし整数 $r[i]$ として表される。$scale$ は正の浮動小数点数であり、zero_point は同様に符号なし8ビット整数 $q[i]$
-
他のBLASライブラリのPDOT microkernelは倍精度だが、このQNNPACKは低精度の計算に最適化されている。
-
モバイルプロセッサのアーキテクチャの制約により、PDOT microkernelのMRとNRは8を超えないレンジであり、最大1024チャネルのモデルでも、メモリブロック全体は最大16KBでレベル1キャッシュに収まる。これが他のGEMM実装(設計思想)の重要な違い。
-
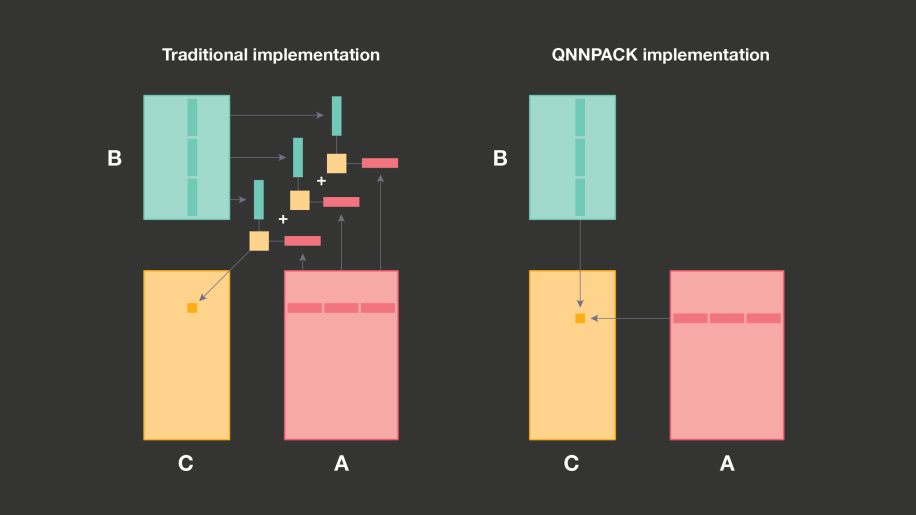
QNNPACKは、AとBのパネルがL1キャッシュに収まり、計算に必要ではないすべてのメモリ変換を削除することを目的としている。
-
従来は大きな行列サイズに最適化されていて、キャッシュ階層を効率的に使用するために、パネルをK次元に沿って固定サイズに分割し、各パネルをL1キャッシュにおさめてから、各サブパネルのPDOT microkernelを呼び出している。この時に32ビットの中間結果を出力している。最終的には加算されて、8ビット再量子化される。
-
QNNPACKの場合はL1キャッシュに収まることは次の恩恵がある。1回のPDOT microkernelの呼び出しでパネル全体を処理し、外部に32ビットの中間結果を蓄積する必要がなく、再量子化をmicrokernelに融合して8ビット値を書き出す。メモリ帯域幅とキャッシュプリントが節約される。
畳み込みの行列乗算への効率的なマッピング
im2col(ゼロから作るDeepLearningに実装ガイドあり、畳み込みで入力パッチ(input tensor)を2D行列に並び替えてforループ回数を減らす実装)において、効率良いアルゴリズム実装を導入している。2Dへの並び替えで、im2col bufferにコピーするのではなく、各出力ピクセルの計算に関係する入力の行へのポインターを使用して間接バッファー(indirection buffer)を設定している。
値コピーではなくて、ポインターを使っているところがミソ。
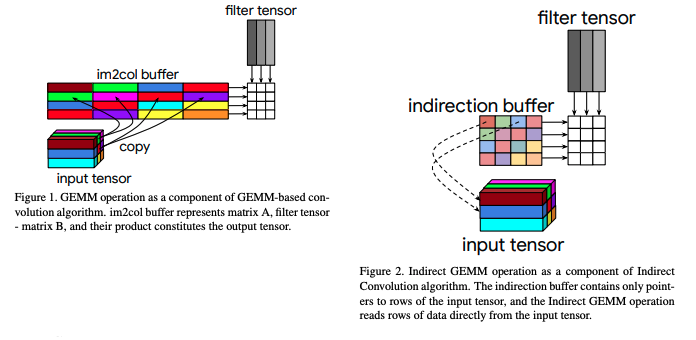
arxiv: 1907.02129 The Indirect Convolution Algorithm
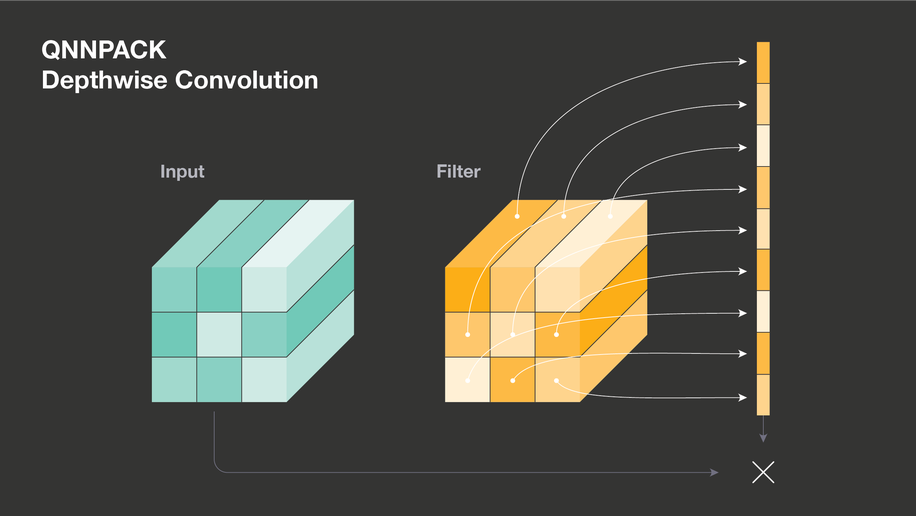
depthwise convolution
推論時にはフィルタの値が更新されないことから、1行の配列に並べて最初のポインターだけ汎用レジスタにロードすることで、ループ内のアドレスレジスタのリロードを回避している。
ここまでがQNNPACKについてです。
XNNPACKでカバーしているNNのオペレーターについてはgithubのREADMEに数多く列挙されていますが、
論文としてピックアップされている次の機能について注目して見ていきます。
高速スパース畳み込み
arXiv: 1911.09723 Fast Sparse Conv Nets
- MobileNet v1の Depthwise Separable Convolution, v2の Inverted Residual, v3の Squeeze and Excitation で採用されたスパース性に着目した、より一般的な高速スパース-密行列乗算(SpMM)用の高速カーネルの紹介
- arXiv: 1803.08601 Design Principles for Sparse Matrix Maltiplication on the GPU
- cuSPARSEで採用されているアルゴリズム
- merge-based load-balancing
- row-major coalesced memory access
softmaxの実装改良
arXiv: 2001.04438 The Two-Pass Softmax Algorithm
実数値スコアを確率分布に正規化するsoftmax関数において、従来の3-pass アルゴリズムから更に浮動小数点のオーバーフローと、余分な正規化計算を回避した2-pass アルゴリズムの紹介
- クラス分類などで良く使うsoftmax関数について
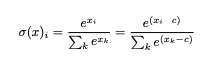
* 従来の3-pass アルゴリズム
pass 1で入力に対する最大値を見つけてから正規化し、オーバーフロー対策としている。この時の最大値を見つけるためにメモリを使っているが、それを使わずに浮動小数点の安定性を得ることが出来ていることがポイント
* 改良した2-pass アルゴリズム
キーアイディアは、浮動小数点を と表現し直し、(m, n)は、(仮数部, 指数部)というように保持することで、浮動小数点の安定性を保ちつつ、最大値を見つけることが出来るようになったこと。 pass 1で、実行中の最大値を追跡し、指数部をnに格納する。仮数部のmはスケーリングされた累積になっている。スケーリングすることでオーバーフローを回避している。
NN推論のための効率的なメモリ管理
arXiv: 2001.03288 Efficient Memory Management for Deep Neural Net Inference
エッジでの推論のメモリフットプリントを最小化するために、NNの中間テンソル間でメモリバッファを効率的に共有する2つの戦略について
- 各メモリバッファ(共有オブジェクト)が特定の時間に中間テンソルに割り当てられる最初の共有オブジェクトを呼び出す。共有オブジェクトのサイズは、割り当てられているすべてのテンソルサイズの最大値。主な目的は、これらの共有オブジェクトの合計サイズを最小化すること。
- 1つ目は、演算子の幅やテンソルサイズにおいて、より広いサイズを優先して実行中にメモリに存在する必要のあるテンソルの割り当てから開始する。それらの改良版も紹介されている。
- 2つ目は、オフセット計算アプローチ。中間テンソルにメモリブロック内のオフセットによってメモリの一部が割り当てられる。共有オブジェクトをメモリに連続して配置することで、オフセット計算問題として解決している。
使用方法
肝心の使用方法は、Tensorflow Liteなどと一緒に使うことになるのだが、リビルドが要るのか設定をいじる必要があるのか。
XNNPACK backend for Tensorflow Lite
Android/Java, iOS/Swift, iOS/Objective-C
Android/Java, iOS/Swift, iOS/Objective-C においては、ビルド済みのTensorflow Lite 2.3以降のバイナリに既にXNNPACKが含まれているとのことで、明示的にxnnpackを有効にする設定をコードに記述すれば利用可能になる。
/// Swift API on iOS
var options = InterpreterOptions()
options.isXNNPackEnabled = true
var interpreter = try Interpreter(modelPath: "model/path", options: options)
将来のリリースでは、デフォルトで有効にするように取り組んでいるとのこと。
desktop, others
Windows, Linux, MacOSなどで使う場合にはBazelでTF-Liteをビルドする際に --define tflite_with_xnnpack=true のフラグを有効しないといけない。
# enable XNNPACK via Bazel build flags
bazel build -c opt --fat_apk_cpu=x86,x86_64,arm64-v8a,armeabi-v7a \
--host_crosstool_top=@bazel_tools//tools/cpp:toolchain \
--define tflite_with_xnnpack=true \
//tensorflow/lite/java:tensorflow-lite
Sparse Inference (experimental)
また、Fast Sparse ConvNetsのスパース推論をサポートさせるには、Bazelのビルドで --define xnn_enable_sparse=true オプションが要るとのこと。
性能
(自ら実験しておりません、READMEからの抜粋です)
Android Pixelにおける、XNNPACKライブラリのシングルスレッドとマルチスレッドのパフォーマンスを示した結果。
- シングルスレッド

* マルチスレッド
SIMDとマルチスレッド処理により2倍近い高速化が図られていることが分かります。
- ラズパイ上でのマルチスレッドのパフォーマンス結果

関連したリンク
ブラウザ上での推論におけるMLモデルのWASMデプロイについては、以下の記事がとても参考になりそうです。
性能に関する記事
- Accelerating TensorFlow Lite with XNNPACK Integration
- SIMD およびマルチスレッド処理で TensorFlow.js WebAssembly バックエンドを高速化する
"Wasm バックエンドは最大 10 倍高速になっています。これは、ニューラル ネットワーク演算用に高度に最適化されたライブラリである XNNPACK を通して SIMD(ベクター)命令とマルチスレッド処理を活用することで実現しました。"