0. はじめに
CNN(畳み込みニューラルネットワーク)の「畳み込み処理」のうち、im2col周りを中心に説明します。サンプルソースはpythonで書かれているわけで、python素人には難易度が高い!筆者の理解の過程を共有します。
全体を通して、以下書籍を参考にしながら記載をしています。
「ゼロからつくるDeepLearning」斎藤 康毅著 オライリージャパン
誰もが知るすばらしい本です。説明がめちゃめちゃわかりやすいです。
尚、本ページに変な記載があったら、すべて私の無知・誤りによるのものです。
1. 全体像
1.1. CNNとは
・・・について、細かい説明は省きます(これを読んでいる人がCNN知らないことはないと思いますので)。
【参考ページ】
Convolutional Neural Networkとは何なのか
1.2. 扱う範囲
CNNのうち、「画像データから最初に畳み込む」部分のみです。im2colについても記載します。
pythonでどう実装しているのか、に焦点をあてています。
1.3. 畳み込みとは
パディング処理を施した画像データに対し、ストライド幅でフィルタを掛け合わせて特徴マップを作る処理です。
上述参考ページのほか、以下ページもわかりやすかったです。
・・・ということで、説明は省きます。
【参考ページ】
畳み込みニューラルネットワーク(Convolutional neural network)
2. 前提知識:numpyの配列
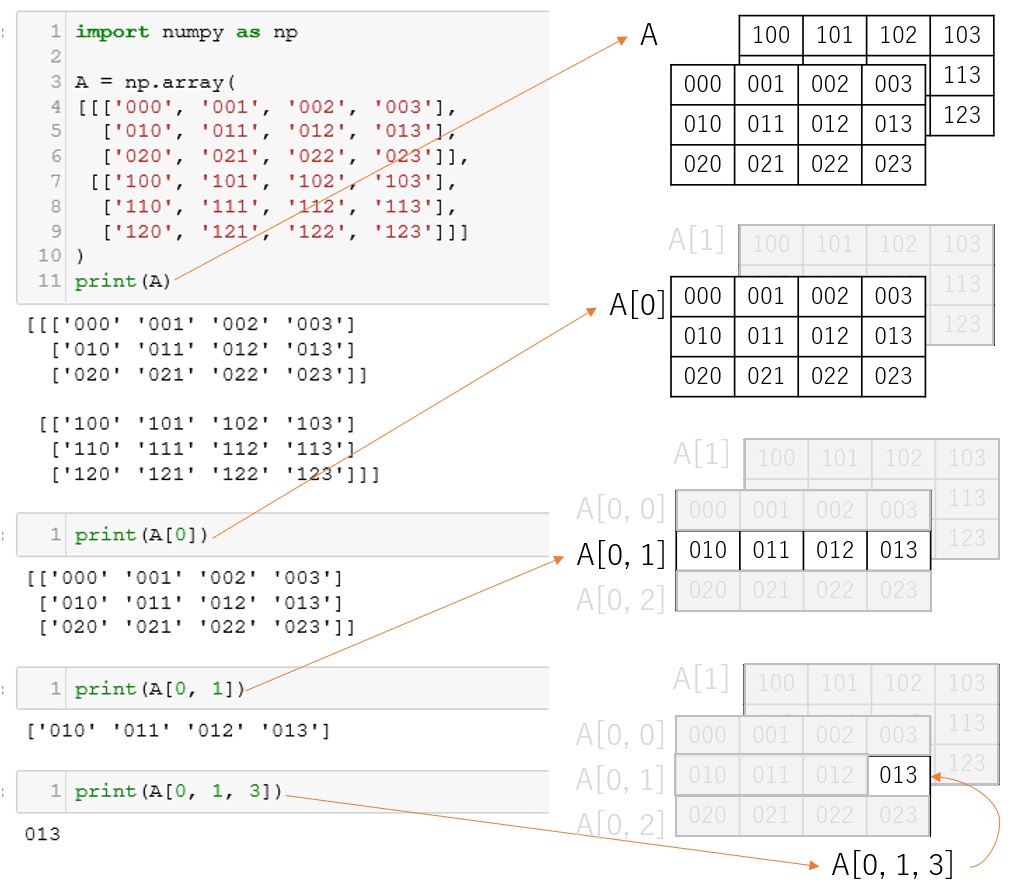
2.1. 高次元配列のデータ指定方法
以下で、「配列の指定方法」と「それがどこを指すのかのイメージ」を持っておきます。
例は、3次元配列の場合です。
2.2. 配列の形式変換(reshape)
配列を変換したとき、値がどのような順番で格納されるかをみてみます。
例は、3次元配列を1次元配列にしています。
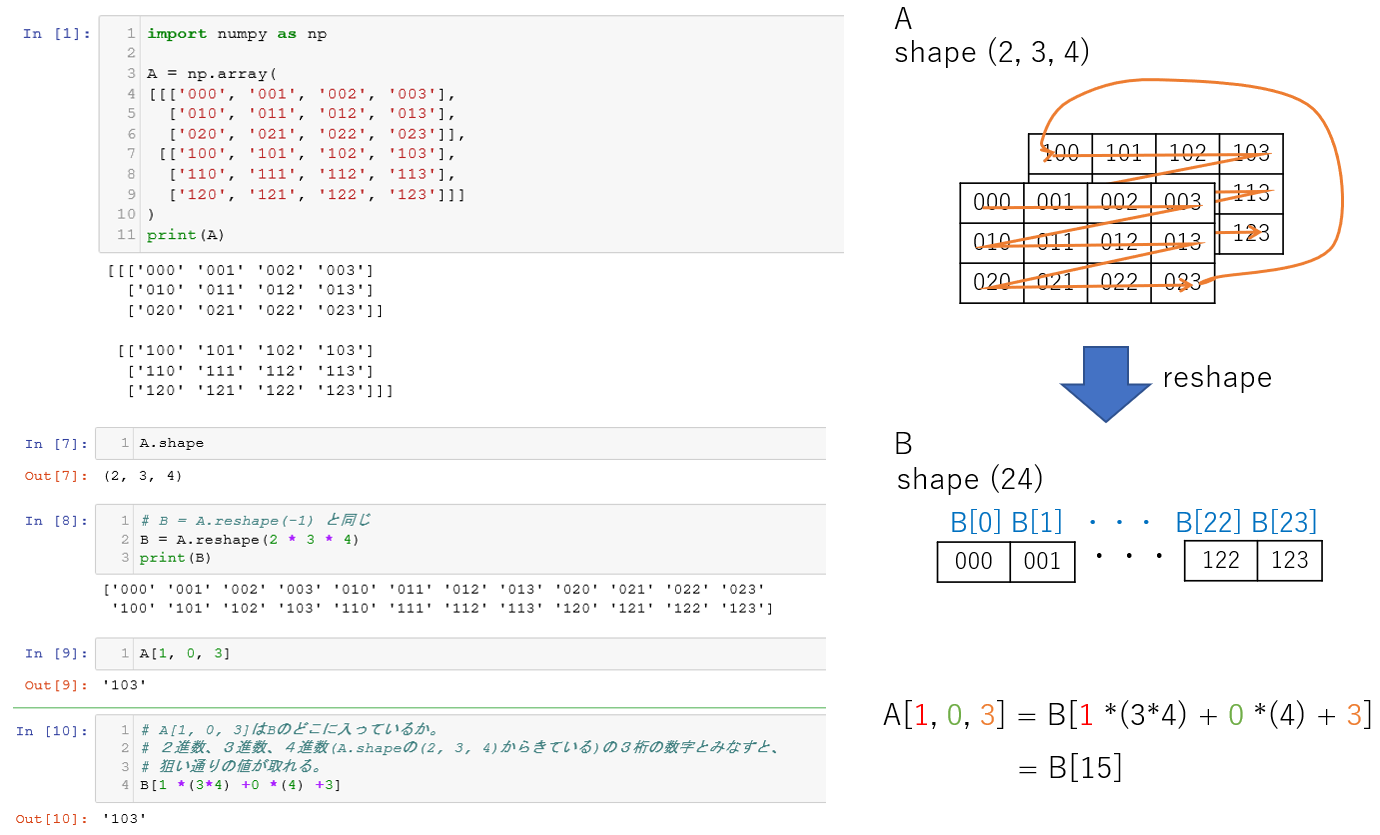
A.shapeが(2, 3, 4)、Aを1次元配列にしたB.shapeが(24)で、
A[1, 0, 3] =B[1*(34) + 0(3) + 3] = B[15] となる点がポイントです。
値(インデックス)の指定方法、格納のされかた、上述のイメージ図を関連づけて理解しておくとよいと思います。
説明やプログラムの中でreshape(ABC, -1)などと書く際、引数の掛け算の順は、上記の値の取り方を考慮して記載します(約束事なのではと思います)。
2.3. 補足
配列の並び順(reshapeでどの順で並ぶか)については、ndarrayのデフォルト設定を前提としています。
reshapeでorderという引数を使うと、reshape時の値の取る順番が変わります。詳しくは以下にて。
【参考ページ】
配列を形状変換するNumPyのreshapeの使い方
3. 畳み込み処理
3.1. やっていること
画像データに対し、フィルタを適用させて(畳み込み)、データの特徴を抽出します。
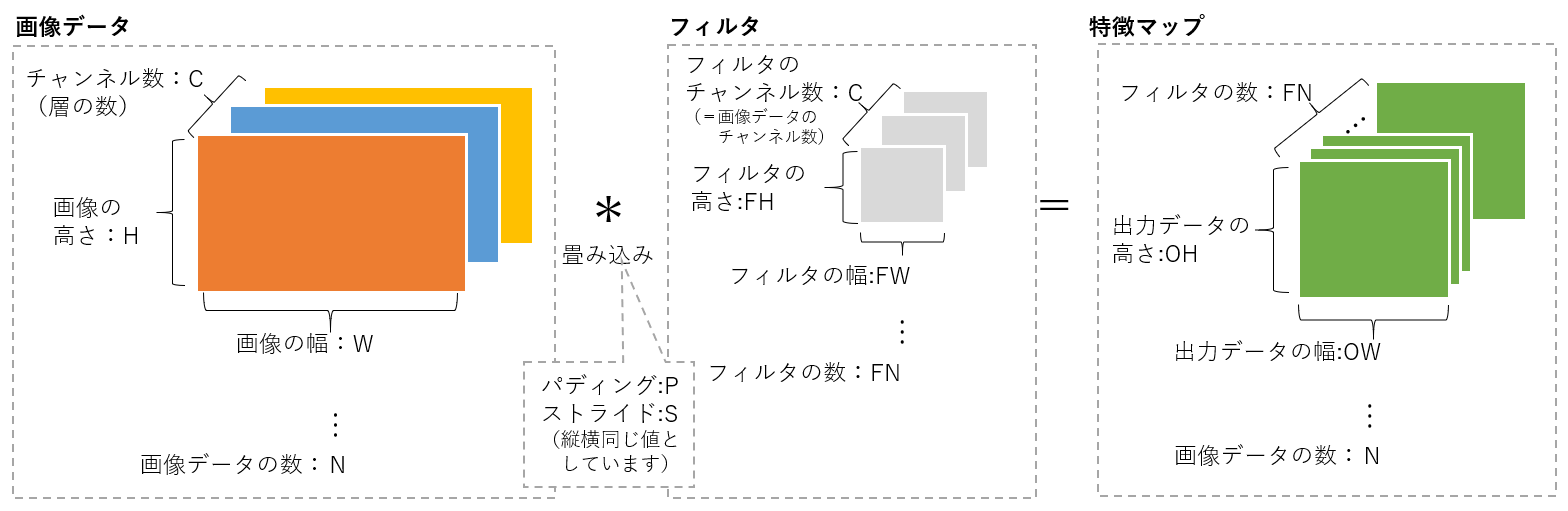
3.2. 処理高速化→行列演算化→im2col
画像データにフィルタをそのまま直感的にコーディングすると計算時間がかかります(、みたいですね)。
numpyは行列計算が高速にできるようになっており、逆にfor文には時間がかかるとされています。
そこで、これを極力行列演算で実現しよう!という発想になります。
おおよそ、
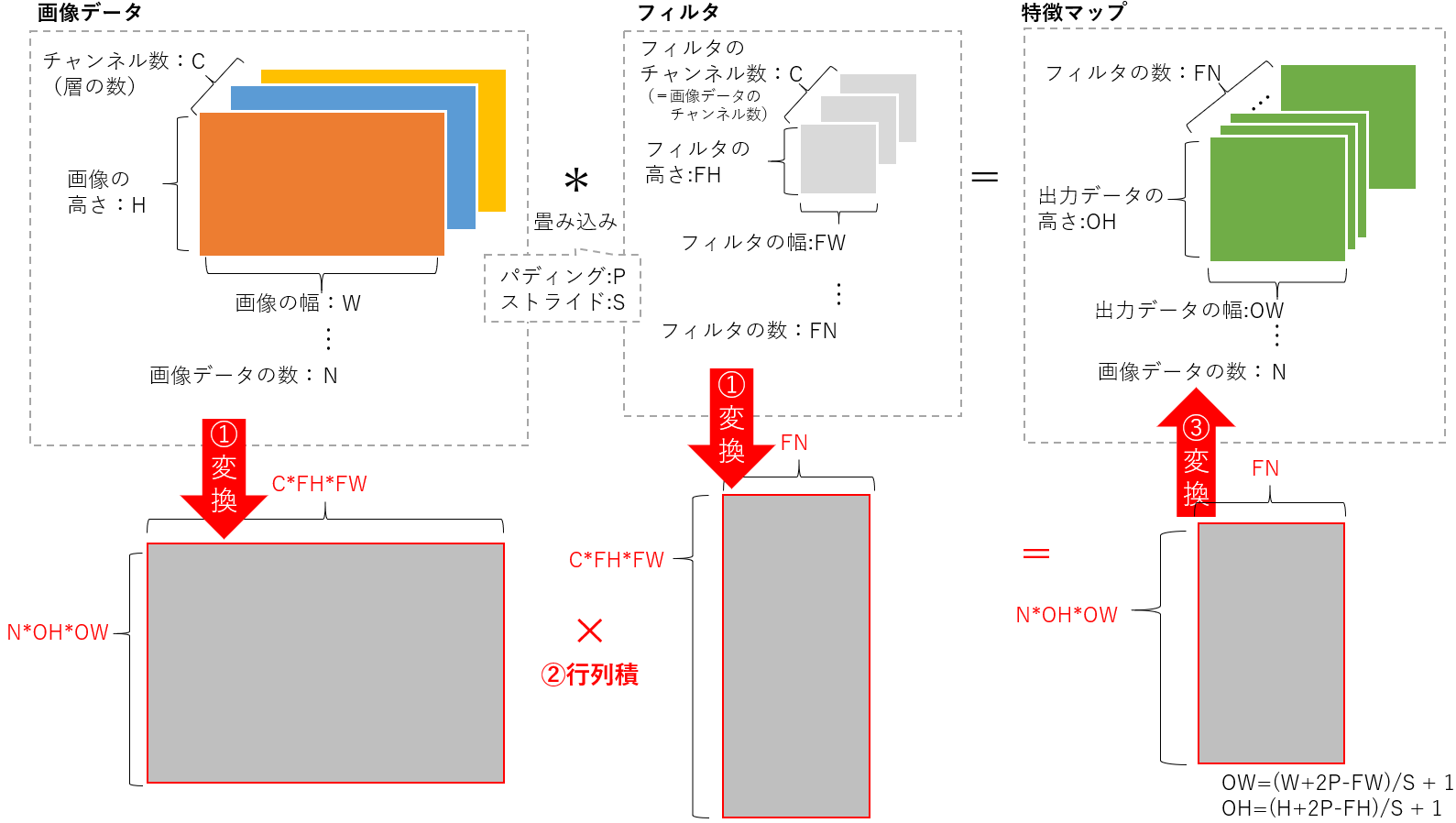
①高次元配列を行列(二次元配列)に変換する。
②行列積を求める。
③行列を高次元配列に変換する。
となります。
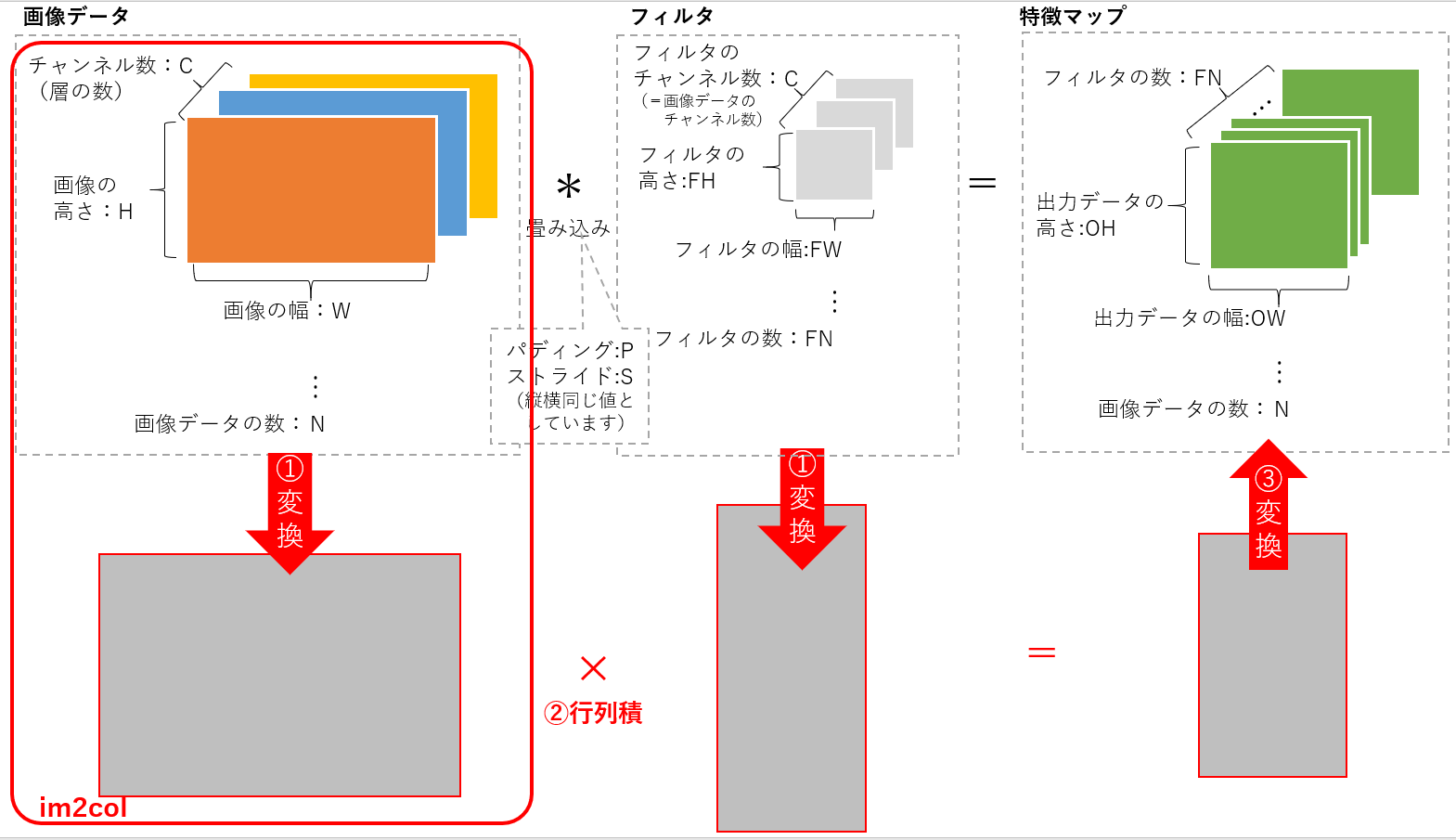
im2colは、画像データ(の集まり)を1つの行列にする、という関数になります。
4. im2col
4.1. フィルタの行列変換
フィルタのデータも多次元です。im2colを考える前に、このフィルタをどのように行列化するかを考えます。
前節でみた図を、まずは配列表記にしましょう。filter_org(FN, C, FH, FW)と記載することとします。
フィルタの数がFN個あり、これらを画像データ群に適用させる必要があります。
直感的に「一つのフィルタの情報」×「フィルタの数」と考えるのがシンプルです。
画像データの配列と行列積をなすためには、縦方向に「一つのフィルタの情報」を格納し、そのフィルタ情報を横に並べる形をとります。
行列の縦方向は「フィルタのデータ(CFHFW)」が入ります。
つまり、フィルタの行列としては、filter_col(CFHFW, FN)としたいわけです。
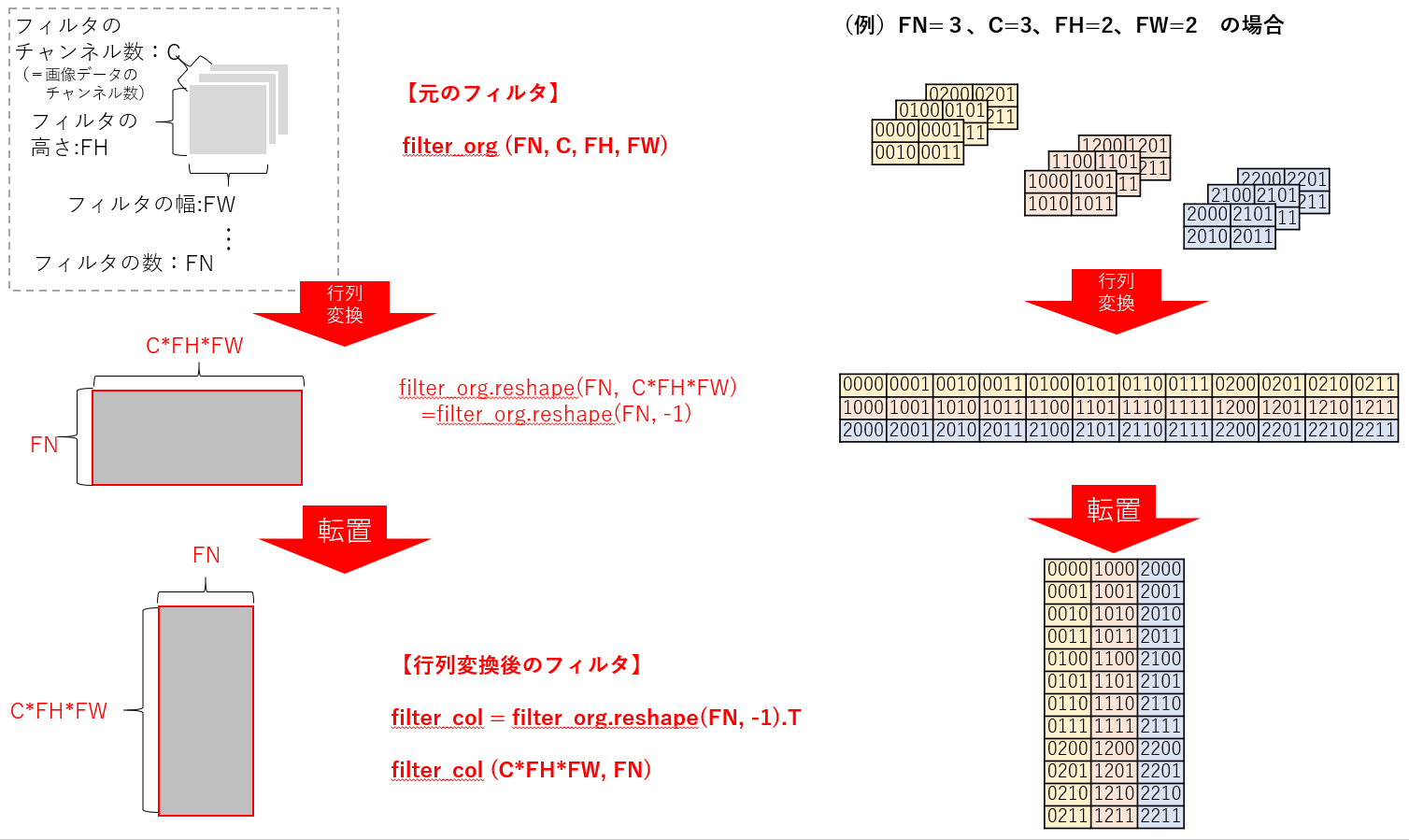
結論として、フィルタの行列変換は
filter_col = filter_org.reshape(FN, -1).T
となります。いきなり、filter_org.reshape(-1, FN)としてはいけません。2.の前提知識でふれたとおり、(FN, C, FH, FW)の順番を考慮せずにreshapeすると、思った通りに値が取り出せなくなります。
im2colはこのフィルタの形式ありき、という点を覚えておいてください。
4.2. 画像データの行列変換
どのようなサイズの行列にすべきかを考えます。
先ほど行列の形式はフィルタの形式ありきといいましたが、フィルタのサイズはfilter_col(CFHFW, FN)です。行列変換後の画像ファイルをim_colとすると、im_colとfilter_colとの行列積を求めるためには、im_colの列のサイズはfilter_colの行のサイズと等しくする必要があります。つまり、CFHFWです。
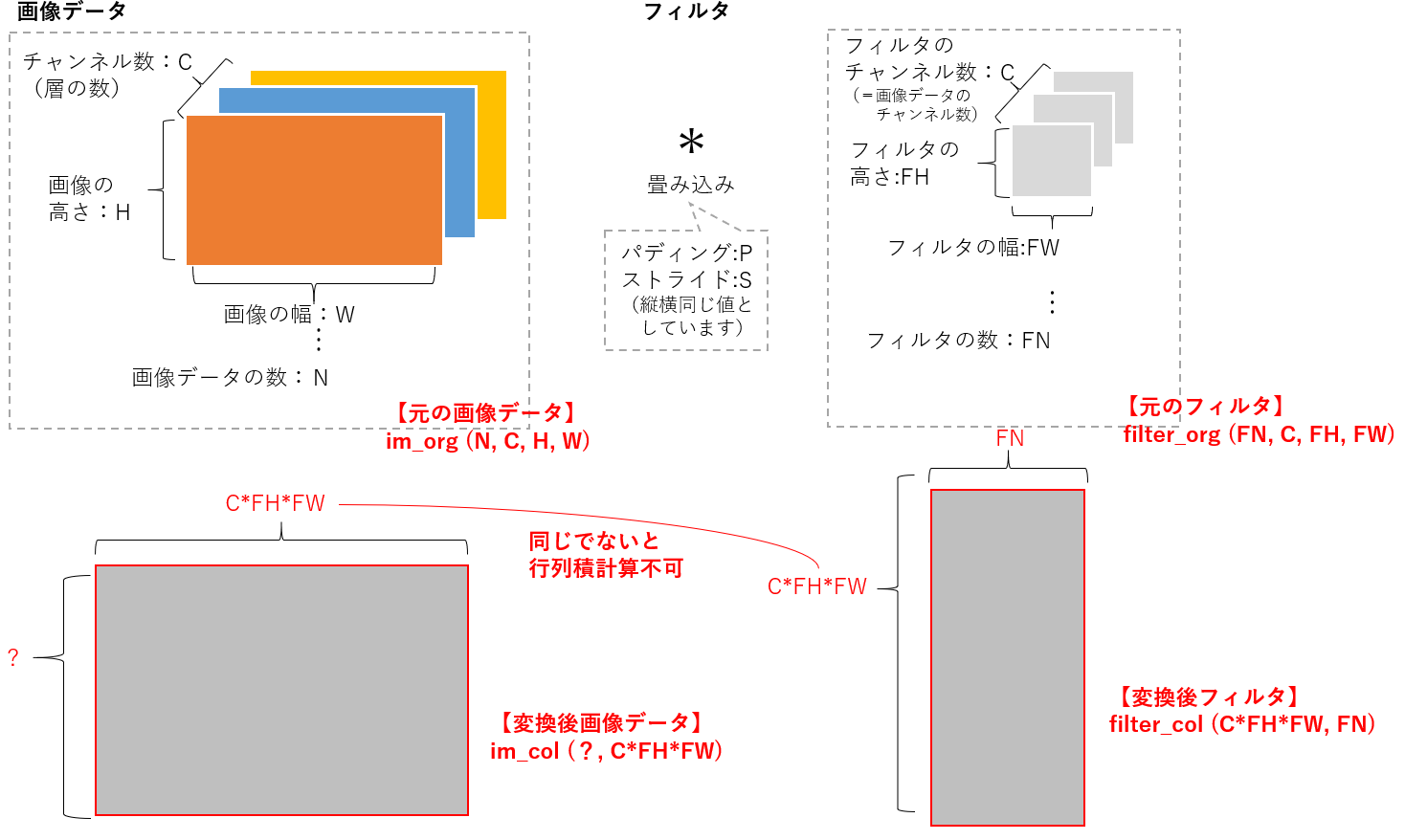
次に、im_colの縦方向にはどのような値を入れるのがふさわしいかを考えます。
filter_colの行列積を取ることを考えると、1列目にはフィルタ"0000"が掛け合わされます。2列目にはフィルタ"0001”、3列目は、・・・・というふうにつながります。
1列目を例にとると、フィルタ"0000"と掛け合わされる画像データを上から順に格納する必要があります。つまり、畳み込みの計算方法を考えると、画像データの最初から、フィルタ"0000"を縦横にストライド分飛ばした値を並べたものになります。
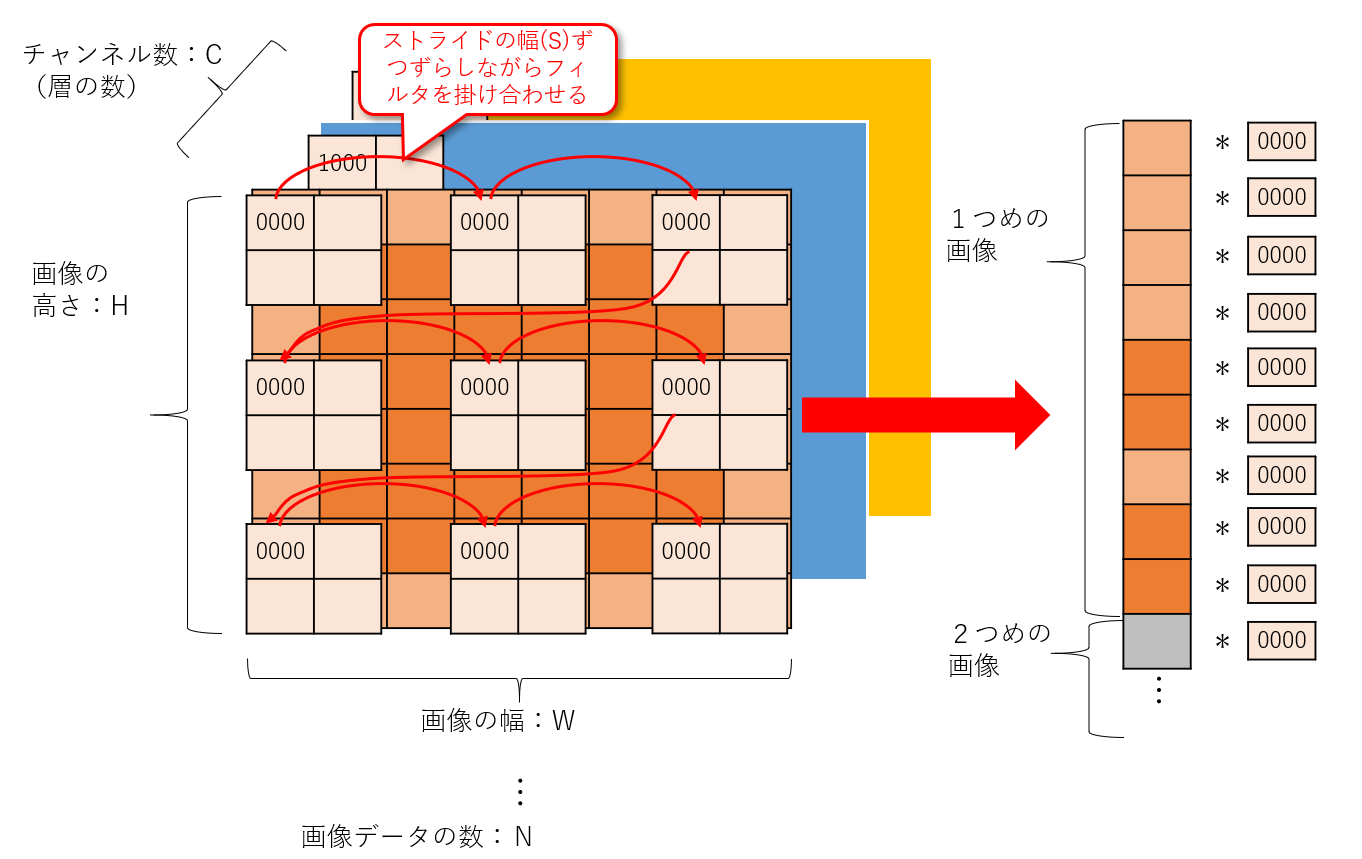
値の個数はいくつでしょうか。それは(NOHOW)です。
Nは画像データの数です。OH,OWですが、これは畳み込み後のデータサイズ(の縦と横)を表します。
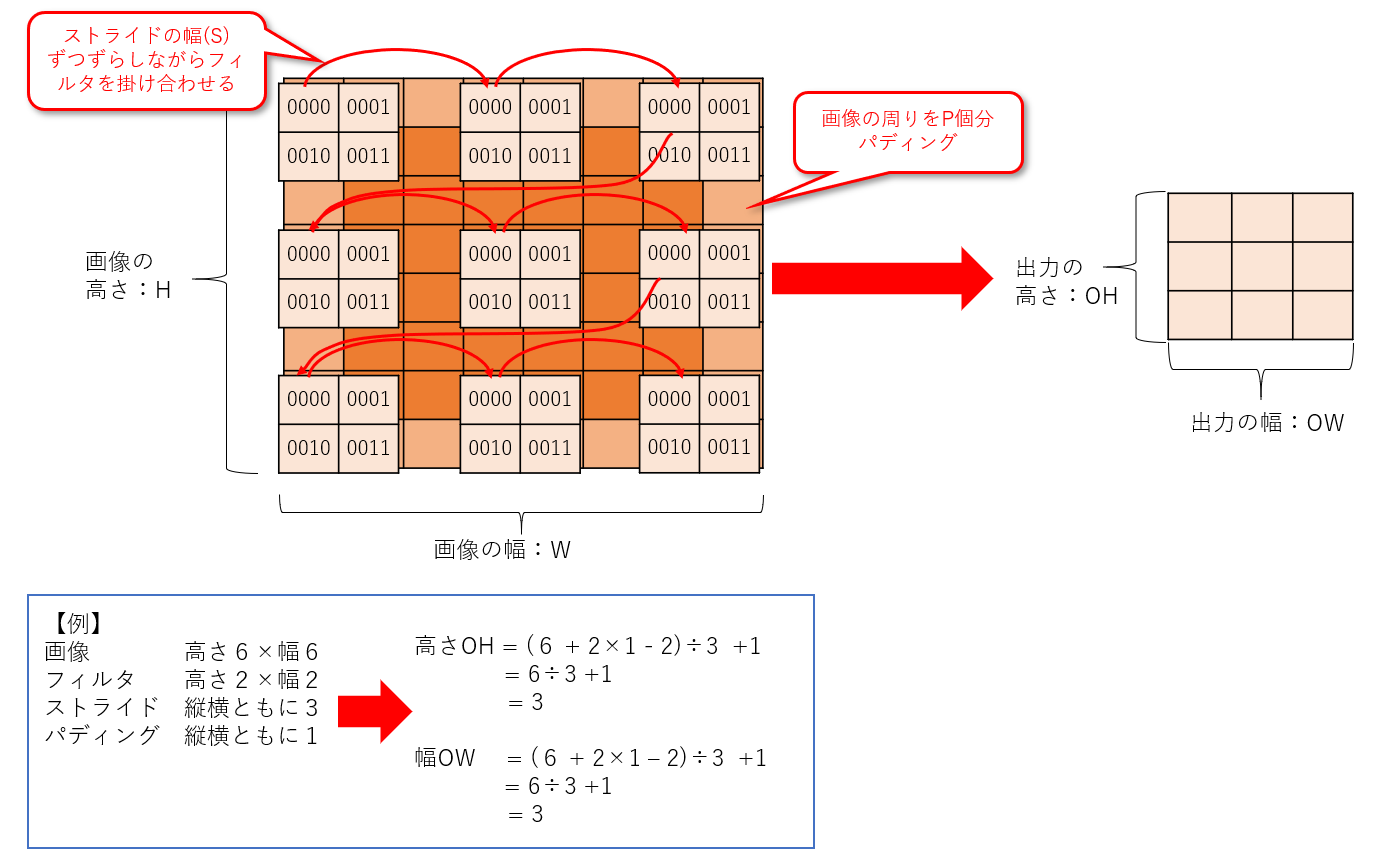
- 画像 高さH×幅W
- フィルタ 高さFH×幅FH
- ストライド 縦横ともにS
- パディング 縦横ともにP
のとき、畳み込み後のサイズは、以下で求められます。
- OH = (H + 2P - FH)/S +1
- OW = (W + 2P - FW)/S +1
結論として、画像データの変換後サイズは im_col(NOHOW, CFHFW) となります。
ここまでくれば、im2colの実装が読めてきます(長かった・・・!)
4.3. im2colの実装
以上を踏まえてim2colです。
よく知られた実装ではありますが、キーとなるところだけコードで記載します。雰囲気だけつかんでください。実装は「ゼロつく本」などでご確認ください。
まず、関数とその引数です。
# 関数の引数は
# 画像データ群、フィルタの高さ、フィルタの幅、縦横のストライド、縦横のパディング
def im2col(im_org, FH, FW, S, P):
各データのサイズを規定しましょう。
N, C, H, W = im_org.shape
OH = (H + 2 * P - FH)//S + 1
OW = (W + 2 * P - FW)//S + 1
画像データはパディングしておきます。
画像データフィルタを適用させます。
まず、im2colの戻り値を定義しておきます。
im_col = np.zeros((N, C, FH, FW, OH, OW))
フィルタの各要素(FH、FWの二次元データ)に適用させる画像データを、
ストライドずつづらしながら取得(OH、OWの二次元データ)し、im_colに格納します。
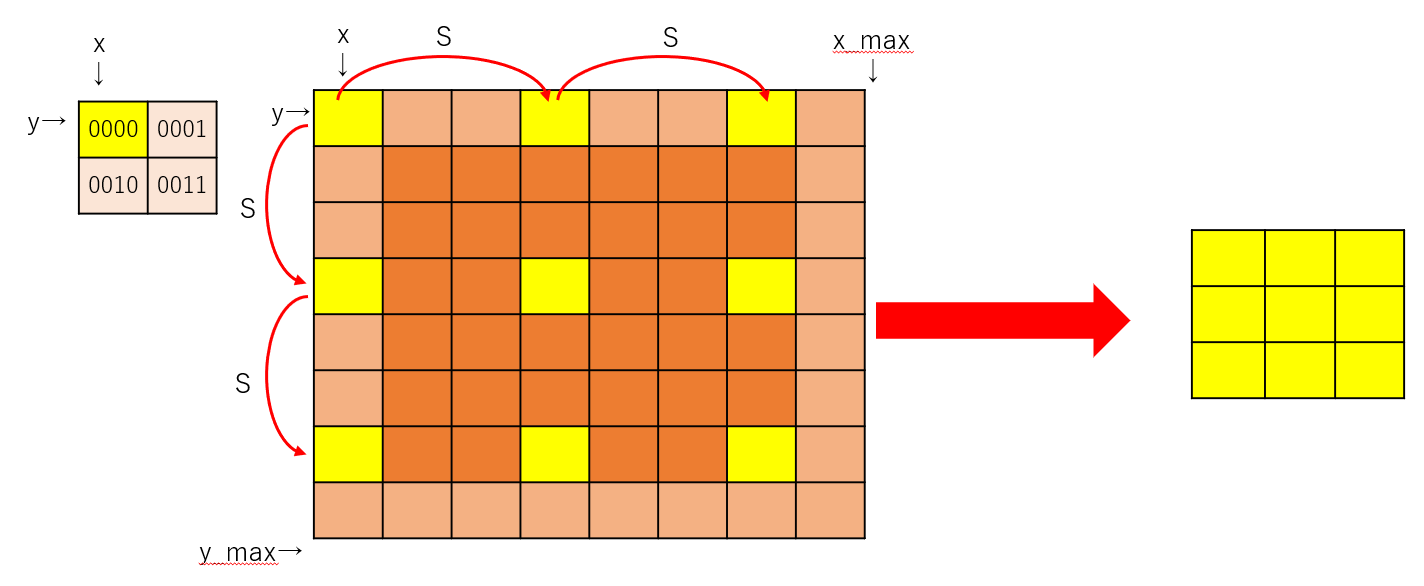
# (y,x)は(FH,FW)のフィルタの各要素。
for y in range(FH):
y_max = y + S * OH
for x in range(FW):
x_max = x + S * OW
im_col[:, :, y, x, :, :] = img_org[:, :, y:y_max:S, x:x_max:S]
for文の一番内側では、以下の黄色部分を取得していることになります。
あとは、目的の形に変形しておしまいです。
# (N, C, FH, FW, OH, OW) →軸入替→ (N, OH, OW, C, FH, FW)
# →形式変換→ (N*OH*CH, C*FH*FW)
im_col = im_col.transpose(0, 4, 5, 1, 2, 3)
im_col = im_col.reshape(N * out_h * out_w, -1)
return im_col
5. im2colの後
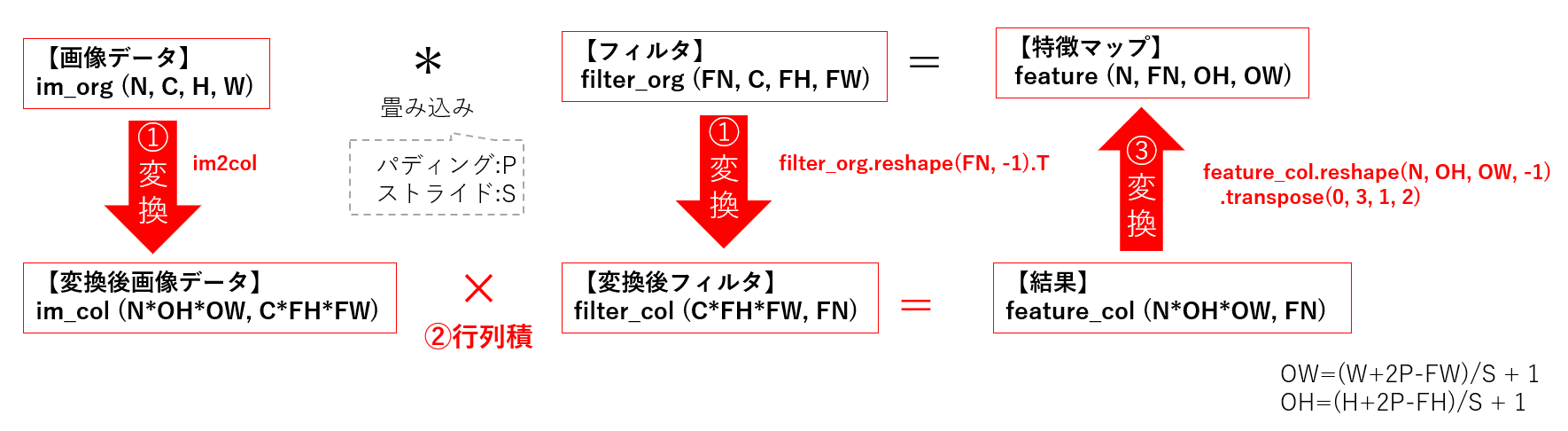
あとは、フィルタを行列変換し、掛け合わせて、結果の行列を多次元配列に戻します。
要はこういうことです(雑!)。
6. おわりに(蛇足)
im2col本当に難しかったんです、私には…。忘れる前にまとめられてよかったです。
機械学習において、python,numpyの理解は大事やな、と痛感しております。