AWS Lambdaを利用していて、コールドスタートに苦しめられた事はありませんか?
私はWebアプリケーションのバックエンドの開発をする場合、Amazon API Gateway と AWS Lambda(Python) の構成でシステムを構築する事がほとんどなのですが、開発終盤で期待していたようなパフォーマンスが出ない事に気付き、仕方なくProvisioned Concurrencyの設定を追加した経験があります。
その時はLambdaのメモリを増強することでパフォーマンスの改善を試みたのですが、期待通りにパフォーマンスが改善したケースと、ほとんど効果がなかったケースがあり、それぞれのケースで何が違うのかよく分かりませんでした。(I/Oバウンドな処理がLambdaのメモリサイズに依存しないのは分かるのですが、ライブラリのimportにかかる時間なども短くならないように見えたので、その理由がよく分かりませんでした。)
今回は、Lambdaのパフォーマンス(Duration)がLambdaのメモリサイズを始めとした様々な要素によってどのように変化するかを検証することによって、LambdaのDuration、特にコールドスタート部分を短くする方法を探っていきたいと思います。
なお、コールドスタートを緩和する方法としてProvisioned Concurrencyがありますが、使わないで済むなら使わない方が良い機能ですので(コストがかかるので)、今回は検討の対象外とさせて頂きます。
コールドスタートについて
Lambda 実行環境のライフサイクルやコールドスタートについては、AWSの公式ブログで詳しく説明されていますが、この記事を読む上ではLambdaがリクエストを受け取った後、以下のステップで処理が実行される事を理解していれば十分です。
- 関数コードのダウンロード
- 新しい実行環境の開始
- 関数コードのhandlerの外側部分の処理(Initフェーズ)
- 関数コードのhandler部分の処理(Invokeフェーズ)
今回の検証で達成したいこと
今回の検証では、Lambdaのメモリサイズやパッケージサイズを変えていった時に、LambdaのDurationがどのように変化していくか、その傾向を調査します。
特に、Lambda関数の全体のDurationを見るのではなく、いくつかのフェーズに分けてDurationを細かく調べる事によって、より詳細な傾向の把握や、フェーズ間のトレードオフの有無について理解を深めたいと考えています。
以下に、各フェーズの定義とDurationの計測方法について記載します。
AWS管理フェーズ
Lambdaがリクエストを受け付けてから、新しい実行環境が開始されるまでの間を、この記事では「AWS管理フェーズ」と呼ぶ事にします。
この部分のDurationは、AWS X-Rayで確認出来るAWS::LambdaセグメントのDurationから、InitサブセグメントのDuration と AWS::Lambda::FunctionセグメントのDuration を引いた値でおおよそ見積もる事が出来ます。
Initフェーズ
Lambdaの新しい実行環境を起動した後、関数コードのhandlerの外側部分の処理が完了するまでの間を、この記事では「Initフェーズ」と呼ぶ事にします。
この部分のDurationは、AWS X-RayのInitサブセグメントのDurationが対応します。
Invokeフェーズ
Initフェーズ後、関数コードのhandler部分の処理が完了するまでの間を、この記事では「Invokeフェーズ」と呼ぶ事にします。
この部分のDurationは、AWS X-RayのAWS::Lambda::FunctionセグメントのDurationが対応します。
検証の前提条件
今回の検証では、特に明記していなければ以下の設定で検証を行っています。
言語:Python3.12
Lambdaの形式:zip形式
VPC内/VPC外:VPC外
CPUアーキテクチャ:arm64
メモリサイズ:512MB
また、傾向を見る事が目的ですので、それぞれの条件での計測は1回のみ行っています。
検証1 Lambdaのメモリサイズによる影響
Lambdaのパフォーマンスチューニングをする際に、一番最初に検討するのはLambdaのメモリサイズの調整だと思います。Lambdaはメモリサイズと連動してCPUの性能も上がるので、CPUバウンドな処理の高速化が期待出来ます。
この検証ではLambdaのメモリサイズを256MB〜2560MBまで変えていった時の、それぞれのフェーズでのDurationを調べます。また、CPUバウンドな処理の処理時間の変化も調べたいので、handler内/外の両方に千万回のループ処理を入れています。
import time
from aws_lambda_powertools import Tracer
tracer = Tracer()
def execute_loop():
start_time = time.time()
for i in range(10000000):
pass
elapsed_time = time.time() - start_time
print(f'elapsed_time: {elapsed_time} ')
execute_loop()
@tracer.capture_lambda_handler
def lambda_handler(event, context):
execute_loop()
return {}
AWS管理フェーズ
下のグラフから分かるように、AWS管理フェーズではメモリサイズによってDurationは特に変化しない事が分かりました。個人的な予想としては、リソースの割り当てを増やすとこのフェーズのDurationは増加するような気がしていたので、少し意外な結果です。この結果を見る限り、メモリサイズを増やす時にこのフェーズへの影響を考慮する必要はなさそうです。

Initフェーズ
Initフェーズの結果はとても興味深いもので、千万回のループ処理を入れているにも関わらず、メモリサイズを増やしてもDurationはほとんど変化しませんでした。これはboost host CPUと言うLambdaの仕様によるもので、Initフェーズの間はメモリサイズに連動するスペックのCPUではなく、boost host CPUが割り当てられ、処理されるのでこのような結果になります。boost host CPUについては、公式ではありませんが、この動画で詳しく説明されています。
冒頭でお話しした、メモリサイズを増やしてもライブラリのimportにかかる時間が短縮されなかったのは、このboost host CPUの仕様の為です。
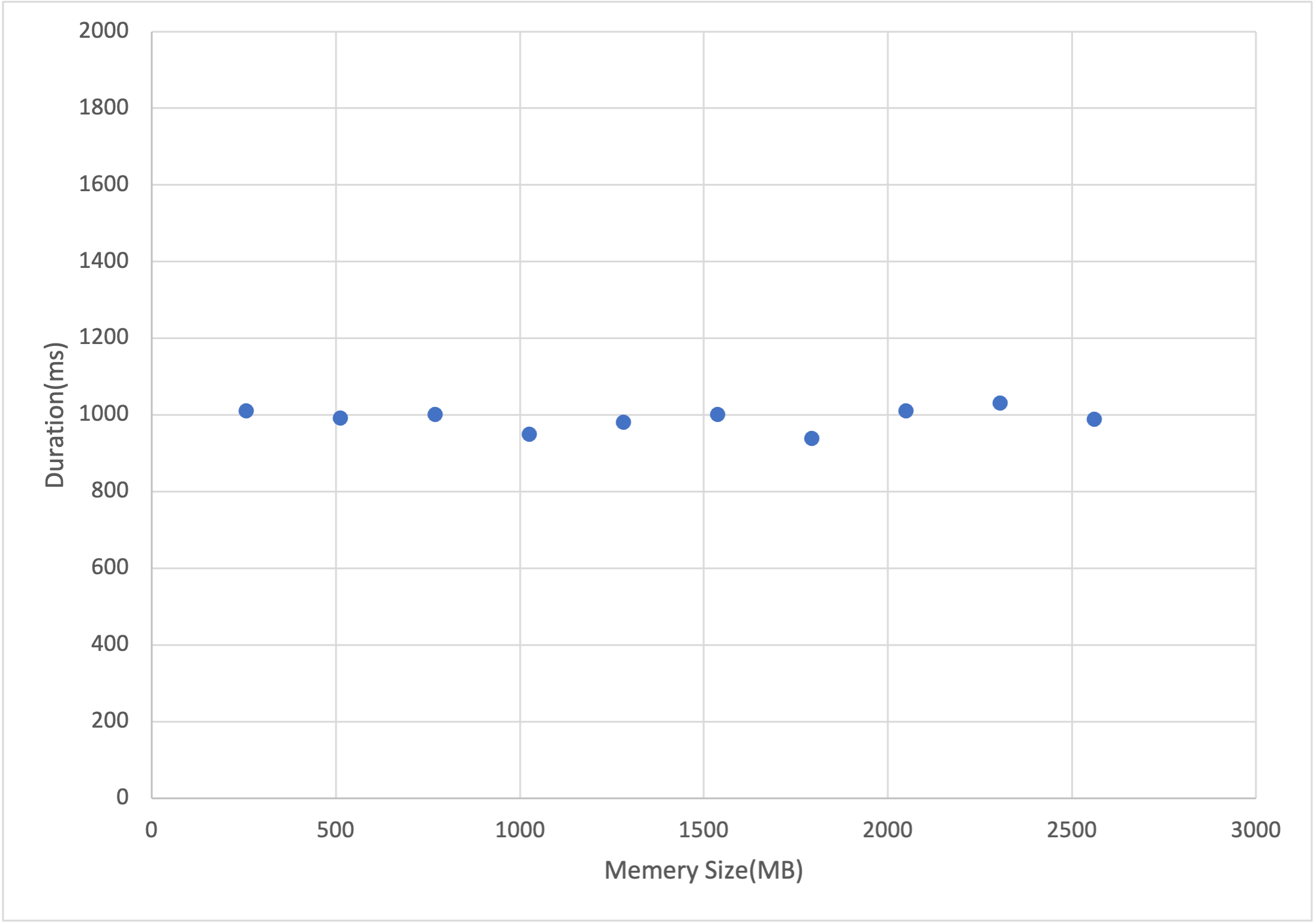
Invokeフェーズ
Invokeフェーズは、期待していた通りにメモリサイズを増やす事によってDurationが小さくなる事を確認出来ました。グラフをよく見ると、メモリサイズが1700MB付近で性能が頭打ちになっている事が分かります。※この点について検証されている記事によると、1vcpu相当のメモリ(1769MB)がシングルスレッド処理での性能限界とのことなので、ほとんどのケースでは256MB〜1769MBの間でメモリサイズを調整すれば良さそうです。

Invokeフェーズでライブラリをimportすると?
Initフェーズの間はboost host CPUが割り当てられているので、メモリサイズを増やしてもDurationが小さくならないのであれば、Invokeフェーズ(handler内)でライブラリをimportして、メモリサイズを増やす事によってライブラリのimportにかかる時間を短縮出来るのか、という点についても検証してみました。
今回は、ライブラリのimportがCPUバウンドな処理だと仮定して、handler内/外の両方で定義した千万回のループ処理の処理時間を比較してみます。

結果としては、1vcpu相当のメモリ(1769MB)付近でboost host CPUと同等の処理性能になる事が分かりました。この結果から、Invokeフェーズ(handler内)でライブラリをimportして、メモリサイズを増やすというアプローチでは、boost host CPUの性能を超える事は出来ないと考えた方が良さそうです。
検証2 利用するライブラリによる影響
これまでの検証で分かったように、Pythonでライブラリをimportする場合、boost host CPUの恩恵が受けられる、handlerの外側(Initフェーズ)でimportするのが有効です。逆に言うと、それでも遅く感じる場合はそのライブラリの採用を見直す必要があるかもしれません。
今回は、過去利用した時に遅いと感じたライブラリのimportにどれぐらいの時間がかかっているのか、いくつかピックアップして調べてみました。
| ライブラリ名 | バージョン | import時間(ms) |
|---|---|---|
| pandas | 2.2.3 | 2209 |
| Requests | 2.32.3 | 328 |
| boto3 | 1.35.66 | 603 |
上記の結果を見ると、1つのライブラリをimportするだけで、全体のDurationが非常に大きくなり得る事が分かります。その為、重いライブラリが必要な処理は非同期処理(バッチ)などに切り出す事を検討した方が良いかもしれません。
他にも、同じような機能を提供している軽量ライブラリに置き換える事でimport時間を短縮出来る場合があります。例えば、Requestsは外部のAPIをリクエストする場合などで利用しますが、urllib.requestに置き換えることでimportにかかる時間を50ms程度に短縮出来ます。
boto3に関しては、バージョンを固定せずプリインストールされたバージョンのboto3を利用する事で、import時間を60%ほど短縮する事が出来るのですが、公式ドキュメントでboto3のバージョンを固定する事を強く推奨しているので、boto3のバージョンは固定しておいた方が良いと思われます。
検証3 Lambdaのパッケージサイズによる影響
Lambdaのベストプラクティスを見ると、Lambdaのパッケージサイズを最小限にする事がプラクティスとして挙げられています。そこで、実際にLambdaのパッケージサイズを変えていく事によって、Durationがどのように変化するか検証してみました。
なお、デプロイパッケージ(Lambda Layersを含む)のダウンロードは、この記事で言うところのAWS管理フェーズで発生しますので、この検証ではAWS管理フェーズのDurationのみ計測しています。
Lambda関数(本体)のパッケージサイズによる影響
zip形式の場合、Lambda関数のデプロイパッケージはLambda Layersも含めて250MB(2024年11月時点)までなので、その間で4点ほど選んでDurationを計測してみました。なお、デプロイパッケージにコメントのみを大量に記述したファイルを追加する事で、パッケージサイズをかさ増ししています。
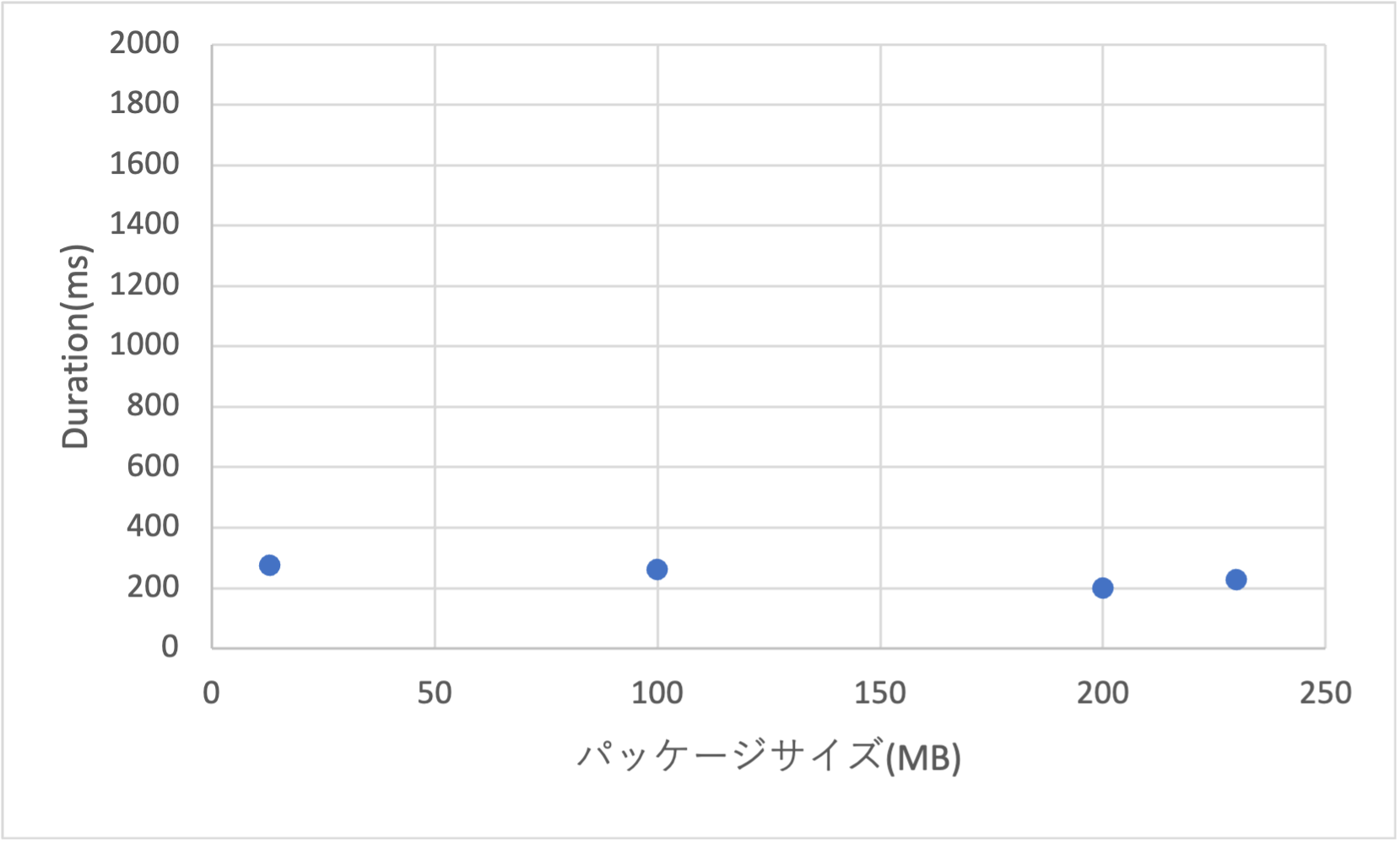
結果は、デプロイパッケージのサイズが大きくなっても、AWS管理フェーズのDurationはほとんど変わりませんでした。単純にデプロイパッケージのサイズが増えるだけなら、そこまで神経質にならなくて良さそうです。
Lambda Layersの数による影響
Lambda Layersの数が増えるとDurationが大きくなったりするのかも気になったので、ついでに検証してみました。この検証で利用するLayerは、コメントのみを大量に記述したファイル(30MB)を格納した状態になっています。
結果としては、Lambdaと紐付けるLayerを増やすだけでは、Durationはほとんど変わらない事が分かりました。

結論
今回の検証結果から、下記の3つの事が言えそうです。
- Lambdaのパッケージサイズ・Lambda Layersの数はそこまで気にしなくて良い
- ライブラリのimportにかかる時間については、ちょっと神経質になるべき
- Lambdaのメモリサイズはhandler内の処理を高速化したい場合に増やす
特にライブラリのimport処理については、boost host CPUの恩恵が受けられるhandlerの外側に書く事がほとんどだと思いますので、現実的に出来る考慮としては下記のようなものになります。
- 重いライブラリの利用は極力避ける
- 不要なライブラリはimportしない
また、メモリサイズのチューニングについては、シングルスレッドの処理がほとんどだと思いますので、256MB〜1769MBぐらいの範囲でチューニングすれば十分だと思われます。
補足1 boto3の高速化について
Lambdaでバックエンドの処理を書く場合、他のAWSサービスと一切連携しないというのはほぼ無いと思うので、boto3のimport時間は結構気になる問題です。
この問題については、AWS re:Invent 2023のセッションで、Rust Bindingsという手法が紹介されています。これは、boto3の処理をAWS SDK for Rustに置き換える事で処理を高速化するというアプローチなのですが、zip形式のLambdaでboto3のimport時間を短縮するには最も有力な方法だと思われます。もし、ご興味があれば一度見てみると良いと思います。
補足2 コンテナ形式のLambdaの利用
本記事ではzip形式のLambdaで検証を行っていますが、コンテナ形式のLambdaの場合は__pycache__を上手く活用する事で、重いライブラリなどのimport時間を短縮する事が出来ます。要件上、重いライブラリが必須の場合は、コンテナ形式のLambdaの採用を検討してみる事をお勧めします。
補足3 AWS Lambda SnapStart
つい最近、PythonもSnapStartに対応しましたね。Javaと違って追加料金が発生するようなので、費用対効果を検討した上で設定する必要がありそうです。
最後に
この記事を最後まで読んで頂き、ありがとうございました。
出来るだけ正確な情報を記載するように心掛けましたが、もし誤った内容がありましたらコメントでお知らせ頂けるととてもありがたいです。