はじめに
YOLOv5を用いての物体検知について勉強したので、マスクを着用しているかどうかを検出するモデルを作成してみました。
ライブラリの準備
今回は、pytorchで書かれたyolo v5を用いるので、以下のコマンドでgitからクローンしてきます。
pythonのバージョンは3.8以上だと良いみたいです。
$ git clone https://github.com/ultralytics/yolov5.git
次に、必要なライブラリをインストールします。
$ cd yolo5
$ pip install -r requirements.txt
データの準備
アノテーション済みのマスク画像データを提供しているMask Wearing Datasetからデータをダウンロードします。
ダウンロードボタンを押して、以下の画像のように、YOLO Darknetを選択します。
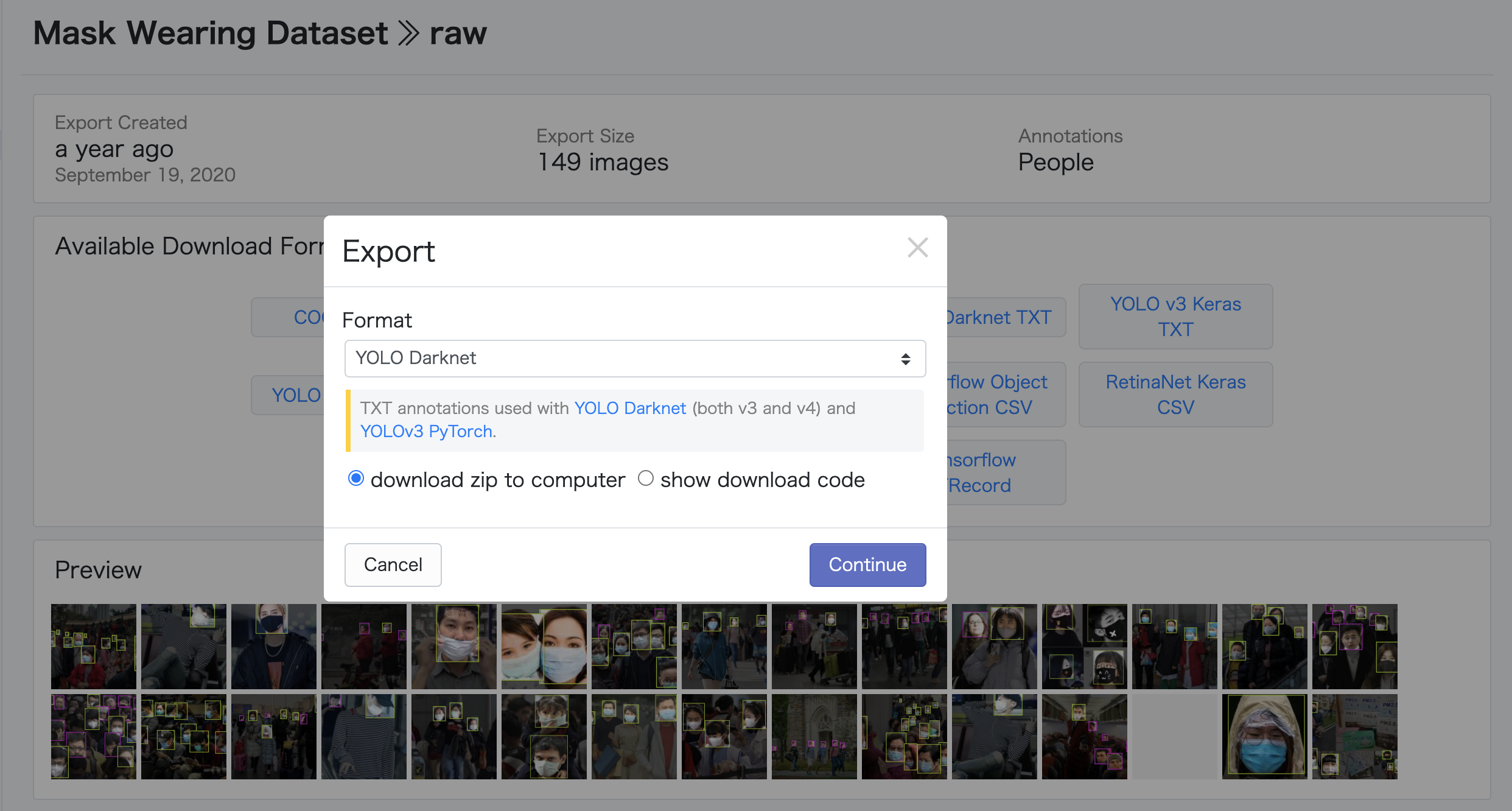
ダウンロードしたデータは、train, valid, testの3つのフォルダに分かれているので、それらのフォルダをyolo5/data/mask_data/に移動させてください。
学習
data.yamlという、学習を行う時の訓練データと検証データのパスや、検出クラス数やクラス名についてを記載するファイルを用意し、yolo5/data.yamlに置きます。
train: data/mask_data/train
val: data/mask_data/valid
nc: 2
names: ["mask", "no-mask"]
これで準備完了です。以下のコマンドで学習開始します。
$ python train.py --batch 16 --epochs 100 --data data.yaml
学習が終わると、モデルの重みが以下のファイルに保存されます。
Optimizer stripped from runs/train/exp/weights/last.pt, 14.5MB
Optimizer stripped from runs/train/exp/weights/best.pt, 14.5MB
テスト
学習した重みを用いて、以下の2つの画像のマスク着用を検知してみます。


テスト画像をyolo5/example_data/に置いて、以下のコマンドを実行します。
変数は、--source テスト画像ディレクトリ, --weights 学習モデルの重み, --conf-thres Confidense scoreの閾値を指定し、--save-txtを加えることで、検出したバウンディングボックスの位置と分類したクラスについて書かれたテキストファイルを作成してくれます。
$ python detect.py --source example_data/ --weights runs/train/exp/weights/best.pt --conf-thres 0.4 --save-txt
これによって得られた結果が以下の通りです。


1枚目はうまく検出できていますが、2枚目は誤認識が目立ちます。
今回のデータセットは149枚と少ないため、あまり精度が出なかったように考えられます。
ということで、データの水増しを行いました。
データの水増し(Data Augmentation)
前に自分が書いた記事であるImageDataGenaratorを用いた画像の水増しを使用しても良かったのですが、今回は他の方法も試してみるため、alubumentationsというライブラリを使用してみることにしました。
albumentationsについての使い方は以下の方の記事が視覚的でとてもわかりやすかったのでおすすめです。
Albumentationsのaugmentationをひたすら動かす
以下のコマンドでライブラリのインストールをします。
$ pip install albumentations
以下のようなaugmentation.pyを作成しました。
アノテーション作業が面倒なため、今回は楽をするために回転や歪み、移動などの処理での水増しを行わずに、RGB ShiftやBlurといった、座標自体の変換がない処理を加えて、アノテーションファイルを使い回しました。
import albumentations as albu
import glob
import cv2
import shutil
from PIL import Image
def get_augmentation_1():
train_transform = [
albu.Blur(p=1)
]
return albu.Compose(train_transform)
def get_augmentation_2():
train_transform = [
albu.RGBShift(p=1)
]
return albu.Compose(train_transform)
def get_augmentation_3():
train_transform = [
albu.HueSaturationValue(p=1)
]
return albu.Compose(train_transform)
IMG_DIR = './mask_data/train/'
imgs = glob.glob(IMG_DIR + '*.jpg')
txts = glob.glob(IMG_DIR + '*.txt')
# ソートをすることで画像とテキストファイルの対応している順番を揃える。
imgs.sort()
txts.sort()
num = 0
for i in range(len(imgs)):
img_origin = cv2.imread(imgs[i])
img_origin = cv2.cvtColor(img_origin, cv2.COLOR_BGR2RGB)
img = img_origin.copy()
transforms_1 = get_augmentation_1()
transforms_2= get_augmentation_2()
transforms_3 = get_augmentation_3()
augmented_1 = transforms_1(image=img)
augmented_2 = transforms_2(image=img)
augmented_3 = transforms_3(image=img)
img_1 = augmented_1['image']
img_2 = augmented_2['image']
img_3 = augmented_3['image']
img_pil_1 = Image.fromarray(img_1)
img_pil_2 = Image.fromarray(img_2)
img_pil_3 = Image.fromarray(img_3)
img_pil_1.save(f"./data/mask_data/train/blur_{num}.jpg")
img_pil_2.save(f"./data/mask_data/train/rgb_shift_{num}.jpg")
img_pil_3.save(f"./data/mask_data/train/hue_saturation_value_{num}.jpg")
shutil.copy(txts[i], f"./data/mask_data/train/blur_{num}.txt")
shutil.copy(txts[i], f"./data/mask_data/train/rgb_shift_{num}.txt")
shutil.copy(txts[i], f"./data/mask_data/train/hue_saturation_value_{num}.txt")
num += 1
実行し、画像の水増しを行います。
$ python augmentation.py
これで、データ数が4倍になったはずです。
学習(データ水増し後)
そして、学習のやり直しを行います。
$ python train.py --batch 16 --epochs 100 --data data.yaml
学習が終わると、重みが以下のファイルに作成されました。
Optimizer stripped from runs/train/exp2/weights/last.pt, 14.5MB
Optimizer stripped from runs/train/exp2/weights/best.pt, 14.5MB
テスト
結果は以下の通りです。


1枚目の画像はConfidense Scoreが上昇し、2枚目の画像は誤認識はあるものの、1回目と比べると検出漏れがなく、精度も向上しているのがみて取れます。
データを増やし、エポック数などのハイパーパラメータを調節すればもっと良い精度が出ることが期待される結果となりました。
おわりに
今回はYOLOv5の学習と検証、データの水増しについて書かせていただきました。
こんなに簡単なのに精度の高い結果を出すYOLOv5はすごいですね。。
物体検出はなんといってもアノテーションが面倒な作業かと思われます。
今回のように、現在アノテーション済みのデータを、座標変換がないように処理することでアノテーションの作業を省略することはある程度効果的です。
しかし、理想はもっと色々な手法でデータの水増しを行って、LabelImgなどのツールを用いてアノテーションを行い、頑健なモデルになるようにするべきでしょう。
最後までお読みいただき、ありがとうございました。