BackGround
GCP 環境(Cloud Storage, BigQuery, Data Portal)で ELT1 を構築する。
データパイプラインにおいて、なるべく自動化を実現したいと考えたのだが、公式でサポートされているような通常の方法2 では、痒いところに手が届かない箇所があり、それへの対処を盛り込んだ形で実装を試みた。
痒いところ
具体的には以下の2点である。
- BigQuery のテーブルにデータを追加するとき、CSV のカラム情報が毎回異なるような場合、既存のカラム情報(スキーマ)とアップロードする CSV のカラム情報で差分が存在するため、ロードに失敗する。
- BigQuery は日本語カラム名に対応していないため、Data Portal でテーブルを表示する時にも日本語対応できていない。
そこで、それぞれについて以下の対応策を考えてみた。
- データをロードする際、BigQuery のテーブル情報を取得し、「既存テーブルには存在せず、ロードしようとしているデータには存在するカラム」 を抽出し、ロードの直前に動的にカラムを追加する。
- CSV に各カラムに対応する日本語カラム名を1行追加し、BigQuery のテーブルの Description として設定し、Data Portal の「設定」に反映されるようにし、その後は手動でディメンションにコピペするという運用で代用する。
これをもとに、以降では具体的な実装方法について見ていきたい。
実装
アーキテクチャ
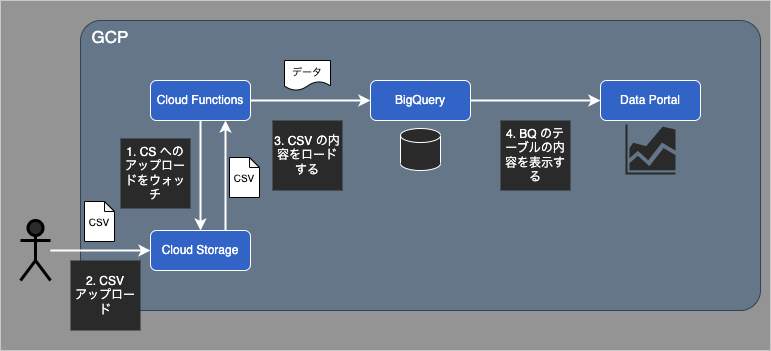
今回のデータパイプラインは、図のような流れとなる。
Cloud Storage に CSV ファイルをアップロードすると、Cloud Functions の関数がキックされる。その中の処理で、CSV からテーブル情報を抜き出し、いい感じに加工して BigQuery にロードする。BigQuery にロードされると、Data Portal 側でも確認することができるようになる。
準備
このデータパイプラインを実現する上で、あらかじめ準備しておく項目を挙げる。
本記事では設定方法などは割愛する。
- Cloud Storage での Bucket の作成3
- この Bucket にファイルがアップロードされたとき、Cloud Functions の関数がトリガーされるように index.ts を記述する4。この記事を参照されたし。
- BigQuery でのデータセットの作成
では、実際のコードを見ていきたい。
BigQuery へのいい感じなロード
Cloud Functions 関数内で以下のような処理を記述した。
痒いところ1 に対しては、①既存のテーブルのスキーマを取得し、②「既存テーブルには存在せず、ロードしようとしているデータには存在するカラム」を特定し、③「②」で追加カラムがある場合はそれを追加した新たなテーブルスキーマ情報で BigQuery 側を更新する、ということを行う。
痒いところ2 に対しては、ロードする CSV から取得する日本語カラム名を更新するスキーマ情報の description に設定する。
/**
* @param {string} bucketName バケット名
* @param {string} filename CSV ファイル名
* @param {any} data CSV ヘッダー情報(カラム名、日本語カラム名)
*/
export const loadCSVFromGCS = async (bucketName: string, filename: string, data: any[]) => {
const DATASET_ID = '<dataset_name>';
const TABLE_ID = '<table_name>';
// [Option]テーブルが存在しない場合は作成する
await bigquery.dataset(DATASET_ID).table(TABLE_ID).get({ autoCreate: true });
// 既存のテーブルのメタ情報を取得する
const [existTable] = await bigquery.dataset(DATASET_ID).table(TABLE_ID).exists();
if (!existTable) {
throw Error(`テーブルが存在しません:${TABLE_ID}`);
}
const table = bigquery.dataset(DATASET_ID).table(TABLE_ID);
const [metadata] = await table.getMetadata();
// テーブルを作成した場合は、必要なオブジェクトが undefined の可能性があるため、明示的に生成する
// また、カラム追加時、テーブルには少なくとも一つ以上のカラムが存在する必要があるので注意すること
if (!metadata.schema) metadata['schema'] = {};
const schema = metadata.schema;
if (!schema?.fields) schema['fields'] = [];
const existingFields: string[] = schema.fields.map((f: any) => f.name);
// 「既存テーブルには存在せず、ロードしようとしているデータには存在するカラム」を抽出する
type T = {
id: number;
name: string;
exist: boolean;
};
const incomingFields: T[] = data[0].split(',').map((d: string, i: number) => {
return { id: i, name: d, exist: existingFields.map((f) => f.toLowerCase()).includes(d.toLowerCase()) };
});
// この関数は、カラム名に対応するデータ型を返却する
// 今回のやり方では、カラム名とそれに対応するデータ型のマッピング定義をあらかじめ決めておく必要がある
const getDataType = (field: string) => {
const dataMapping = {
id: 'INTEGER',
name: 'STRING',
age: 'INTEGER',
height: 'INTEGER',
blood_type: 'STRING',
} as const;
const dataType = Object.keys(dataMapping).find((x) => field.includes(x));
if (!dataType) {
throw Error(`No Data type is found matching ${field}`);
}
return dataMapping[dataType as keyof typeof dataMapping];
};
const jpFieldNames = data[1].split(',');
const newColumns = incomingFields
.filter((field) => !field.exist)
.map((field, i) => {
// 日本語フィールド名を description に設定し、DataPortal に反映されるようにする
return { name: field.name, type: getDataType(field.name), description: jpFieldNames[field.id] };
});
const new_schema = schema;
newColumns.forEach((c) => new_schema.fields.push(c));
metadata.schema = new_schema;
// テーブルのスキーマを更新する
const [result] = await table.setMetadata(metadata);
// CSV から取得した、BigQuery にロードするデータ本体
const incomingData = data[0].split(',').map((field: string) => {
return { name: field, type: getDataType(field) };
});
const metadataForLoad = {
sourceFormat: 'CSV',
skipLeadingRows: 2, // ロードに際してスキップする行数。2行目までデータではないため 2 を設定
schema: { fields: incomingData },
location: 'asia-northeast1', // Cloud Storage のリージョンと一致する必要がある
};
const [job] = await bigquery
.dataset(DATASET_ID)
.table(TABLE_ID)
.load(storage.bucket(bucketName).file(filename), metadataForLoad);
};
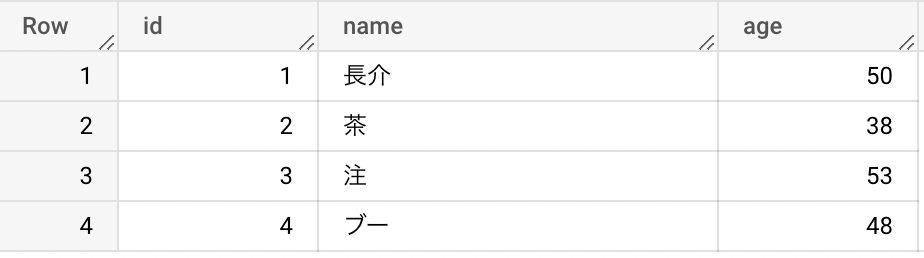
dataの内容例は、以下のようなものである。
// initial data
id,name,age
ID,名前,年齢
1,長介,50
2,茶,38
3,注,53
4,ブー,48
また、loadCSVFromGCS 関数の第三引数 data には、上の CSV ファイルの2行目までの内容が入っている。
すなわち、上記コード中でこのような中身となる。
data[0] = 'id,name,age';
data[1] = 'ID,名前,年齢';
検証
初回アップロード
まず、現状で Cloud Storage にCSV ファイルをアップロードして、データパイプラインを走らせてみると、 CSV にある3つの情報が BigQuery および Data Portal 上で確認できた。
-
BigQuery テーブル
-
Data Portal 接続

追加アップロード
次に、CSV の内容を変更して再度データパイプラインを走らせてみた。
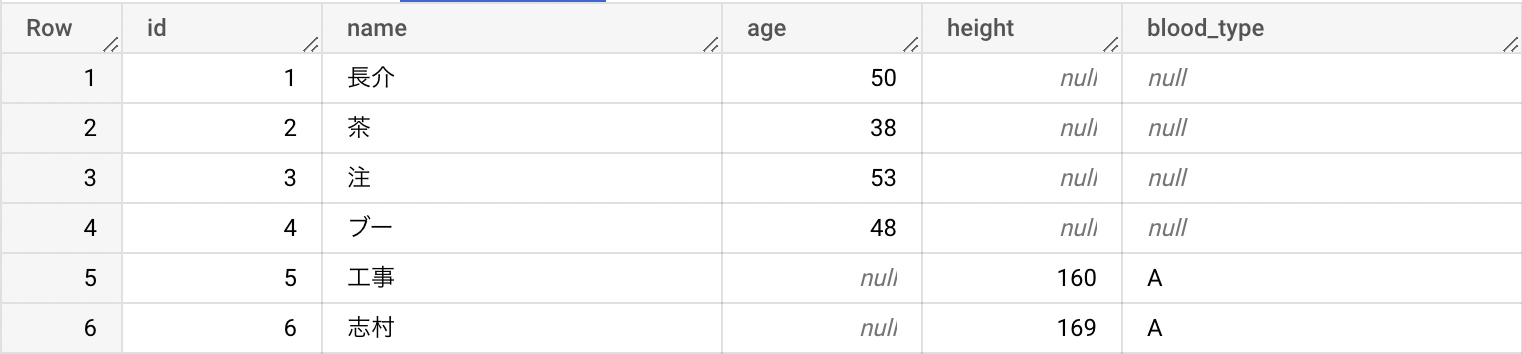
今回アップする CSV は以下の通り。
「年齢」が含まれておらず、「身長」と「血液型」が追加されている。
// second data
id,name,height,blood_type
ID,名前,身長,血液型
5,工事,160,A
6,志村,169,A
同様に、data の中身:
data[0] = 'id,name,height,blood_type';
data[1] = 'ID,名前,身長,血液型';
結果は以下の通り。
-
BigQuery テーブル
-
Data Portal 接続
このように、ロードする CSV 間の差異を吸収して、その時アップロードした内容のみを BigQuery に追加し、関係のない箇所(カラム)には手を加えない という直感的な処理を実装することができた。
初回ロードの CSV にのみ含まれていたカラム(年齢)は、2回目ロードには含まれていないため、2回目ロードで追加された行の該当カラムは null となり、同様に2回目ロードの CSV にのみ含まれていたカラム(身長、血液型)は、初回ロードには含まれていないため、初回ロードで追加された行の該当カラムは null となっているが、これは想定された挙動出ることに注意されたい。
カラムの日本語対応
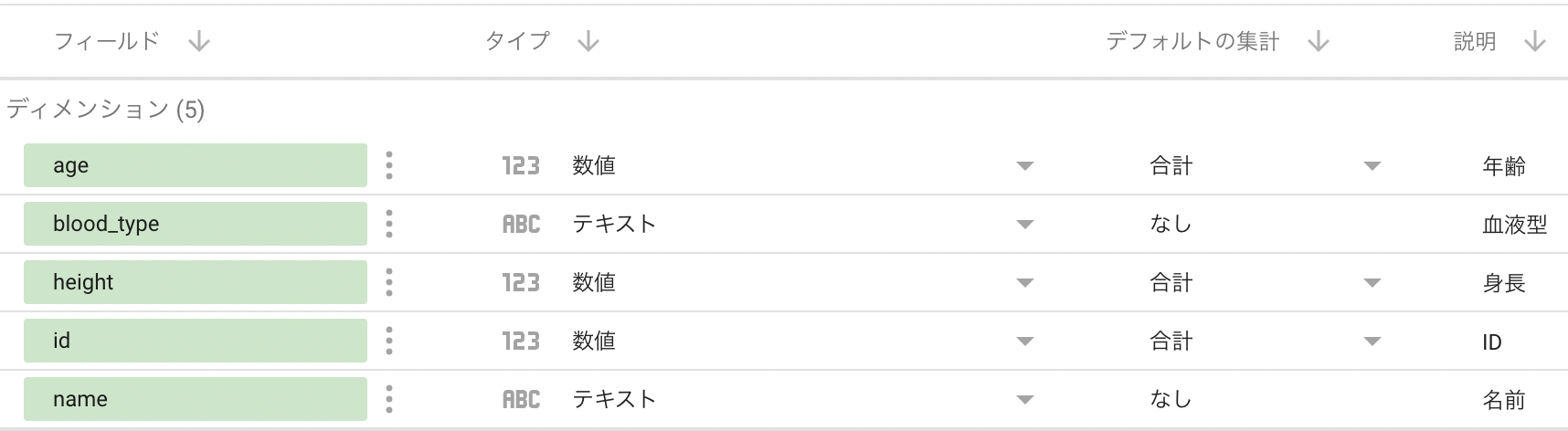
BigQuery および Data Portal 上で日本語カラム名が確認できるようになった。
-
BigQuery
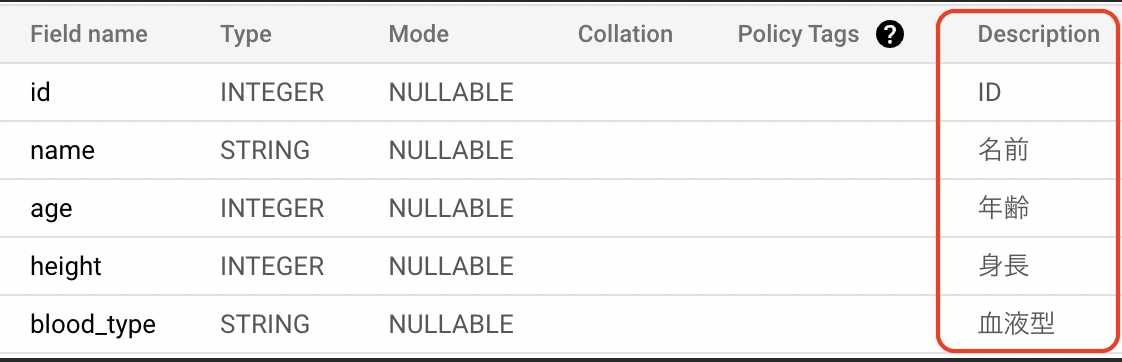
-
Data Portal
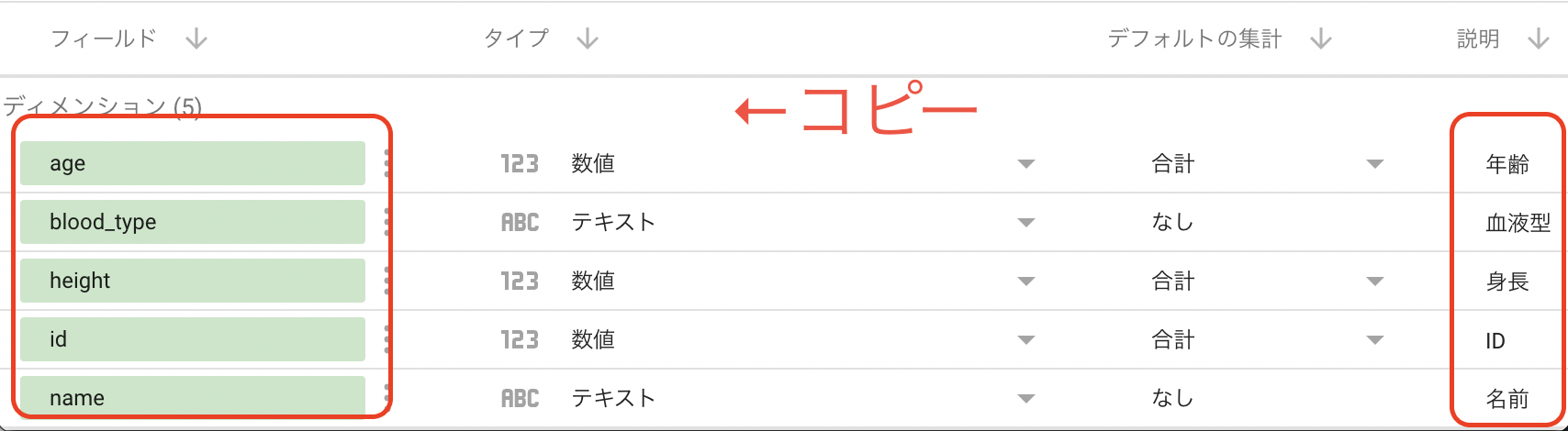
Data Portal の接続画面で、「説明」の項目を「ディメンション」へコピペすることで、Data Portal でレポートを作成する際などにも日本語カラム名を表示することができるようになった。
まとめ
- Cloud Functions を利用することで力づくで BigQuery へのロードを CSV データが毎回異なるような場合でもその差分をいい感じに吸収するように実現した。
- 日本語カラム名対応していない BiqQuery のワークアラウンドを考えた。
ただし、BigQuery のマネージドサービスではなくロード処理を自家製で行うことは、エラー処理や通知などの問題も考慮する必要があるということは覚えておきたい。
-
ELT(Extract, Load, Transform)やその前身である ETL(Extract, Transform, Load)についてはググるとたくさん出てきます。 ↩
-
例えば、BigQuery Data Transfer Service はアップロードするスキーマと、既存のスキーマが同じでないといけない。 ↩
-
https://cloud.google.com/storage/docs/samples/storage-create-bucket?hl=ja ↩
-
https://firebase.google.com/docs/functions/gcp-storage-events?hl=ja ↩