Background
Firebase には便利な拡張機能があり、今回そのうちの一つである Stream Collections to BigQuery を使用する機会があったので、調査したことのメモを残したいと思う。
Stream Collections to BigQuery
この拡張機能は、Firestore 上のドキュメントに変更(作成/更新/削除)があったときに、その情報を BigQuery にエクスポートするものである。
詳しい内容はこちらを参照いただきたい。
調査結果
以下の4つの項目について記載する。
- JSON 形式の変換: BigQuery のデータを JSON → RDB 仕様に変換したビューの作成
- Firestore のタイムスタンプ型の BigQuery での扱い
- Extension の仕様
- Partitioning option について
1. JSON 形式の変換: BigQuery のデータを JSON → RDB 仕様に変換したビューの作成
以下の2通りからどっちが後の分析がやりやすいか比較する
- 1a) スクリプトを使う(下で紹介している Extension 利用した方法)
- 1b) View を自分で作る(自分でスクリプトかくやり方)
「後の分析のしやすさ」を二つの視点で評価した
- i) JSON -> RDBS 仕様への変更そのものの作業
- ii) RDBS 仕様の View において、パーティションを利用したクエリを実行できる必要があるか
i) JSON -> RDBS 仕様への変更そのものの作業
| メリット | デメリット | |
|---|---|---|
| 1a(スクリプト) | スキーマを json ファイルに外出しすることで、管理しやすくなる | スクリプト(コマンド)実行の操作の学習コスト(慣れていない場合) |
| 1b(マニュアル) | BigQuery コンソール上で直感的に操作可能 | 変換すべき項目が多い時、クエリ記述量も多くなり煩雑化しやすい、管理が大変 |
ii) RDBS 仕様の View において、パーティションを利用したクエリを実行できる必要があるか
-
スクリプトの使用とマニュアルでのクエリの編集の両方を使うことで上手く目的を達成できそうである。
Extension のスクリプトを使用して作成する View({table_id}_schema_{json_file_name}_changelog)は、デフォルトではパーティションによる絞り込みが組み込まれていない。ただし、この View のクエリを編集することで、パーティションに応じたデータを取得可能となる。
具体的には、BigQuery コンソール上で、対象のView > DETAILS > EDIT QUERYでクエリ編集画面を開き、以下のように_PARTITIONTIMEによる絞り込みをクエリの条件文に挿入する:SELECT document_name, document_id, timestamp, operation, JSON_EXTRACT_SCALAR(data, '$.first_name') AS first_name, JSON_EXTRACT_SCALAR(data, '$.last_name') AS last_name, `{project_id}.{dataset_id}.firestoreNumber`(JSON_EXTRACT_SCALAR(data, '$.age')) AS age, `{project_id}.{dataset_id}.firestoreTimestamp`(JSON_EXTRACT(data, '$.event_log')) AS event_log, JSON_EXTRACT_SCALAR(data, '$.contact.telephone') AS contact_telephone, JSON_EXTRACT_SCALAR(data, '$.contact.email') AS contact_email FROM `{project_id}.{dataset_id}.users_raw_changelog` WHERE DATE(_PARTITIONTIME) = "2022-10-09"
以上より、基本的には Extension の機能を利用した方法により JSON → RDB の変換を行い、必要に応じてマニュアルによるクエリの調整を行うのが良いのではないかと考える。
1a) Extension を利用した方法について
credentials の設定
コマンドを実行する上で、credentials の設定が必要である。gcloud CLI ツールによる設定 または Firebase CLI ツールによる設定 の方法で行う(コマンドは GCP 上の Cloud shell で実行可能。その場合、この credentails の設定は画面に従って行うことができるため簡単)
今回は、ローカル環境で Firebase CLI を利用した設定方法をご説明する。
- Service accounts ページで、
App Engine default service accountのアカウントに対して key を json ファイルとして発行する。(例えば、key.jsonと名前をつけて保存) - ターミナルで以下を入力する。
export GOOGLE_APPLICATION_CREDENTIALS=./key.json
スキーマ定義ファイル の作成
Firestore にデータが作成(更新)されると、本 Extension により指定の BigQuery 上のデータセットのテーブルに追加される。デフォルトでは、data フィールドに json 形式でデータが貯められるため、これをどのように独立したフィールドにマッピングして View を作成するかの定義を記述する。
以下は、users.json という user テーブルのスキーマを定義するものである:
{
"fields": [
{
"name": "first_name",
"type": "string"
},
{
"name": "last_name",
"type": "string"
},
{
"name": "age",
"type": "number"
},
{
"name": "event_log",
"type": "timestamp"
},
{
"fields": [
{
"name": "telephone",
"type": "string"
},
{
"name": "email",
"type": "string"
}
],
"name": "contact",
"type": "map"
}
]
}
コマンド実行
以下のコマンドを実行することで、BigQuery 上に View を作成する:
npx @firebaseextensions/fs-bq-schema-views
--non-interactive
--project=<projectId>
--dataset=<datasetName>
--table-name-prefix=<tableName>
--schema-files=./users.json
2. Firestore のタイムスタンプ型の BigQuery での扱い
BigQuery の方でも timestamp 型として扱える。
ただし、そのためには以下のどちらかの処理が必要となる。
- 2a) スキーマ定義ファイル を用いてスキーマビューを作成する。
- 2b) BigQuery のテーブルに対してマニュアルで作成する。
2a) スキーマ定義ファイル を用いてスキーマビューを作成する。
Firestore -> BigQuery へエクスポートした直後は、Firestore 側のデータは data というフィールドとして JSON 形式で格納される。
この data を RDBS 仕様にするのが本操作となり、その時に スキーマ定義ファイルで定義した型でビューが生成される。
2b) マニュアルで data から該当するデータ(timestamp)を取り出す。
Firestore で timestamp 型のデータは、BigQuery にエクスポートするとまずは以下のような型になります:
{
_seconds: number, // unixtime
_nanoseconds: number
}
_seconds に unixtime でデータが入っているため、これを BigQuery の関数 TIMESTAMP_SECONDS を使用することで、timestamp に変換が可能である:
Select TIMESTAMP_SECONDS(1664624454)
-- 2022-10-01 11:40:54 UTC
3. Extension の仕様
- 3a) Firestore ドキュメントの更新がかかってもエクスポートされるのか?
- 3b) エクスポート対象のコレクション名は、同じコレクション名なら全部エクスポートされるか?
3a) ドキュメントの更新がかかってもエクスポートされるのか?
更新の場合もエクスポートされる。
BigQuery テーブル上の operation フィールドに UPDATE が格納される。
また、Firestore ドキュメント生成時には、operation = CREATE となる。
3b) エクスポート対象のコレクション名は、同じコレクション名なら全部エクスポートされるか?
本 Extension インストール時に指定した Collection path で指定した コレクションのみが対象となる。
例) collection1: /authors, collection2: /books/123/authors があった場合
-
「authors」 を指定した場合は、collection1 のみが対象となる。
-
collection2 を対象にしたい場合は、
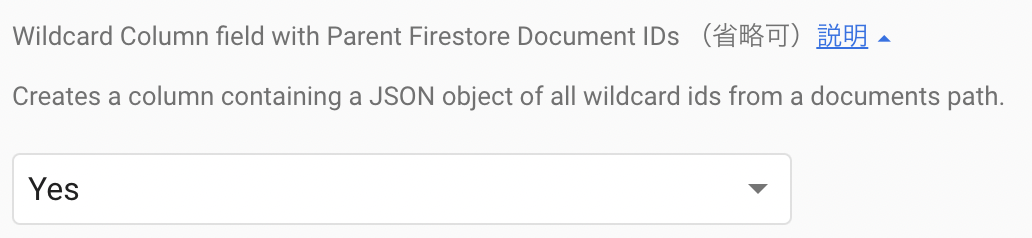
Collection pathに「authors/{author_id}/users」を指定する。- またこの時、Extension インストール時に以下の項目を
Yesにすることで「authors/{author_id}」の部分はpath_paramsとして BigQuery への エクスポートデータに含めることができる。
- またこの時、Extension インストール時に以下の項目を
4. Partitioning option について
拡張機能インストール時の設定画面:

① について
対象のテーブルに対して、どの間隔でパーティションを作成するかを指定する。
これらは、Ingestion time(Firestore から BigQuery にされたタイミング) によって以下のような分割単位に対応している:
| Time Partitioning | 分割の単位 |
|---|---|
| NONE | パーティションを作成しない |
| HOUR | 「時間」でパーティションを分割する |
| DAY | 「日」でパーティションを分割する |
| MONTH | 「月」でパーティションを分割する |
| YEAR | 「年」でパーティションを分割する |
② について
BigQuery のテーブルでのパーティションカラム名を指定します。このカラムに入る値の単位でデータがパーティションに分割される。
空白の場合は _PARTITIONTIME となる。
(ただしこのデフォルトのままだと、本 Extension によって生成される View のうち {table_id}_schema_{json_file_name}_latest の方は、このカラム名が使用できないようである)
またこの項目を変更すると、以下の ③ を指定しないと上手く動作しないようである。
すなわち、このカラム名を変更すると、Ingestion time によるパーティションは作成されないということになる。
③, ④ について
③ を指定することで、Ingestion time ではなく、Firestore ドキュメントの任意のフィールドに基づいてパーティションを作成することができる。
④ では、そのフィールドのデータ型を指定する。
これらを指定すると、Ingestion time によるパーティションは作成されない。
その他
パーティションを有効化するために、 本 Extension をインストールする際の注意点を以下に挙げる:
- Cloud Functions location/BigQuery Dataset location:
Tokyo (asia-northeast1)/Tokyo (asia-northeast1)の組み合わせではパーティションカラムによる絞り込みができなかった(エラー:Unrecognized name: _PARTITIONTIME)ため、 デフォルトの組み合わせIowa (us-central1)/United States (multi-regional)を指定した。