Twitter API Client を開発する過程の忘備録
もう退職をしてしまったのだが、以前 SNS のキャンペーンを実施する企業で働いていた。
その際、「事業のコア部分である SNS サービスの API は自前でクライアントを実装するべきである」と主張していたが、退職する最後の遺産として Twitter API Client のライブラリを勉強会で発表し、レポジトリを公開 した。
勉強会の段階では時間が足りず(また実装が追いつかず)、説明不足の部分もあったこと、
また自身の現時点でのプログラミングに対する考えの忘備録として、今回の内容を記しておく。
ビジネス的なコア部分は自前で持つべき
企業が他社と自身を差別化する際に重要となるのは、いわゆるドメインに対する知識であると考えている。
社員全員が等しく社内ドメインの知識の恩恵を受けるために、なるべく知識は共通化されたコードに埋め込まれておくべきであると考えているため、Twitter API は外部ライブラリを使わず、自前で実装すべきであると主張している。
自前で実装すべき対象はビジネスの形態によって異なるはずであり、なぜ Twitter API が自前で持つべき対象であるのかに関しては、詳しく勉強会で述べているので割愛する。
開発したライブラリの技術的な特徴
さて、これはエンジニアリングとしての記事であるため、開発した Twitter API Client の技術的な観点から、私の現在のプログラミングに対する認識を整理してみるのも良いだろう。
コーティングは対話的であることが望ましい
VSCode のようなエディタを使っていると良く感じるが、コーティングとはエディタとの対話のようなものだ。
今やりたいことを書き始めると、次に書くべきことが提示され、それを繰り返していく。
以降で出てくる技術的な見解のほとんどが「より良い対話を得るために、どのようにライブラリを書けば良いのか?」という考察から生まれている。
Literal 型の活用
仕事で上司から「開発したプロジェクトで使用されている Twitter API の一覧をください」と言われたらどうすれば良いだろう?
特に自分たちが制御していない外部のサービスを利用している場合、それらのサービスに依存した問題(利用料金やインターフェースの破壊的変更など)の影響度合いを知るために、こういった要求は来ることがある。
作業者の目線で言えば、とりあえず影響範囲があるところを直すしかないのだが、「影響範囲を見積もれていること」が管理者としては重要らしい。
さて、この問題、実は一般的な Twitter API のクライアントライブラリを利用していると調査が意外に難しい。
client.list(params)
このコードが実は https://api.twitter.com/2/lists/:id を呼んでいると、
すぐにわかる人は多くあるまい。
(このサンプルコードは少し悪意がある。 https://api.twitter.com/2/tweets/:id であれば、 client.tweet(params) となり、ツイート API を呼んでいると想像できそうだ。 grep による検索条件の絞り方で属人性がありそうだが)
カプセル化は詳細を隠すことを利点として上げられるが、今回の場合は具体的に詳細(実際に呼ばれている API が何か)を知りたいのだ。
これはカプセル化という素晴らしいアイデアが、私が求めている API クライアントへの要求に一致していないことを示している。
しかし、世の中の多くの API クライアントのライブラリは、カプセル化によって細部を隠してしまっている。
これは問題だ。
問題というのは認識に対する不都合であるので、今回のライブラリでは Literal 型というものを使って解決を試みた。
from twitter_api import TwitterApiClient
response_body = (
TwitterApiClient.from_oauth2_app_env()
.request("https://api.twitter.com/2/tweets")
.get({ "ids": ["1460323737035677698"] })
)
このコードはどの Twitter API を利用しているのか明確だ。そして、このコードはエディタからの補完候補の提示を受けながら書くことができる。

Rust を学んで以降に受けたプログラミング言語に対する最大の衝撃は、 TypeScript が持ち込んできたリテラル文字列の発展である。
これは、全く新しいスタイルのコーティングが可能だ。
実際の仕事上では、後で確認しやすいように(付箋なり特別な符号をセルに書いたり)検索用のキーを残すことがあるが、 Literal 型はそういったことにとても向いている。
コメントなどによるドキュメントよりもはるかに確実に、キーとなる用語をコーティング上にメモするよう強制できる。
(今回の例では API の URL がコード上で必ず明記されるようにしている)
このような作りにしておけば、Twitter API の何を使っているのかは明確であり、プロジェクトで使用している Twitter API の一覧の調査も容易だ。
https://api.twitter.com を検索すれば良いのだから。
Python は TypeScript を参考に発展しているが、 TypeScript の型定義ではもっと複雑なことができる。
しかし、現状では文字列による複雑な型チェックは、常に取るべき方法だとは思えない。クエリビルダの項目でこの話を行う。
JSON は共通データ言語
常々主張しているのだが、最近の言語は大体が JSON を貼り付けるだけで動くコードを書けるように合わせてきていると思う。
フォーマッタが文字列の囲み文字を'から " へ推奨するように変えているのも、きっとその一環だ。
Python でもいくつかの特殊な変数を用意すれば、JSON データを貼り付けるだけでコードが動く。
true = True
false = False
null = None
data = {"a": true, "b": [false], "c": {"d": null, "e": 12}}
これは、ちょっとした動作確認をしたいとき役にたつ。言語間の移行の閾値が下がるからだ。
今回のライブラリには、このための便利なヘルパーが用意されている。
from twitter_api.utils.json import *
data = {"a": true, "b": [false], "c": {"d": null, "e": 12}}
ただ、Twitter API クライアントのライブラリの責務ではないので、将来的には外してしまうかもしれない。
2023/06/22 json-literal というパッケージとして 0.9.0 で切り出しました。
TypeDict の活用
型安全に書きたいが、入力部分はなるべく少ない記述量で書きたい。
例えば次のコードは型安全だ。
from twitter_api import TwitterApiClient
response_body = (
TwitterApiClient.from_oauth2_app_env()
.request("https://api.twitter.com/2/tweets")
.get(GetTweetsQueryParameters(ids=["1460323737035677698"]))
)
しかし、GetTweetsQueryParameters が必要であることを調べ、 import しなければならない。
わずかな手間と言えるが、利用する段階ではできればこの手間を省きたい。
そう言った時、型安全な TypedDict は都合がいい。
from twitter_api import TwitterApiClient
response_body = (
TwitterApiClient.from_oauth2_app_env()
.request("https://api.twitter.com/2/tweets")
.get({ ids=["1460323737035677698"] })
)
これは、 ids などのクエリ要素に対して補完が効き、コード量も少なく、 GetTweetsQueryParameters を知る必要もない。
JSONを貼り付けるだけで動作可能だ。
今回は、 API の入力側に対しては TypedDict を利用することにした。
Pydantic の活用
入力側( QueryParameters, RequestBody)では TypeDict を用いたが、出力側( ResponseBody )では pydantic を用いている。
出力側で TypedDict を用いなかった理由は、下記だ。
- 未知のパラメータを扱うことができない
- プロパティやメソッドを生やすことができず、扱いを簡単にするヘルパーを用意できない
特に、1 の未知のパラメータを扱うことができない点は問題だ。
Twitter API の戻り値は利用者がコントロールできるものではないので、いつパラメータが追加されるかわからない。
そのため、将来の変更を検知でき、かつ変更が起きても従来通りライブラリとしては API を実行できる必要がある。
今回のライブラリでは、下記のように予期しないフィールドを検知できる。
assert get_extra_fields(response_body) == {}
また、戻り値のインスタンス化はライブラリ側が内部で行うため、入力側で懸念したような型名を探す手間も通常は発生しない。
基本的には、入力側に比べて、出力側はよりドメインに近い型(つまり、より豊かな表現力)をもった型になると考えている。そのため、入力側が JSON のようなプリミティブ型(int, float, str, bool, None)の組み合わせデータであることに比べ、出力側はヘルパーメソッドを使えたり、色々と便利な恩恵をより多く受けられるのだ。
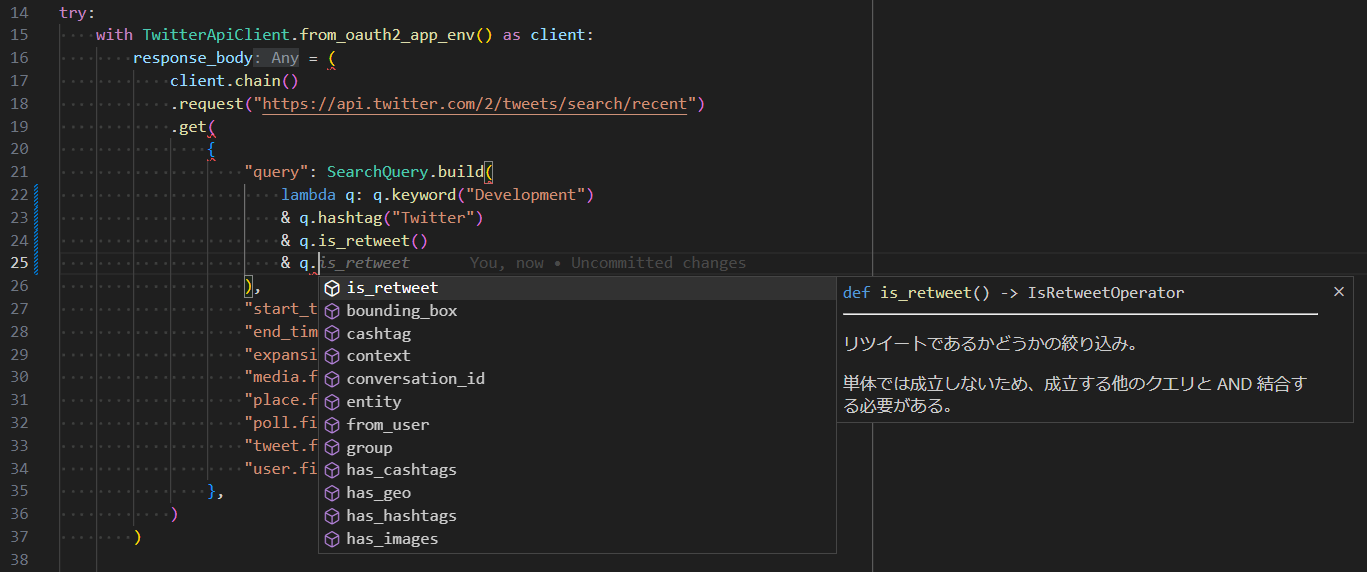
クエリビルダの活用
オブジェクト指向の継承は昨今では否定的な意見を受けることも多いが、それほど悪いアイデアであるとは思っていない。
特に、物理演算エンジンや今回のようなクエリビルダにおいては、継承を用いたコードは良く適合していると思う。
Twitter のドキュメント を読むと、クエリの基本的な構成要素はオペレータであり、その種類は事前に定義されている。
クエリを書くときは、構成要素を制約通りに正しく組み立てるだけだ。
今回のライブラリでは、 SearchQuery.build で検索条件のクエリを組み立てている。
from twitter_api import TwitterApiClient
response_body = (
TwitterApiClient.from_oauth2_app_env()
.request("https://api.twitter.com/2/tweets/search/recent")
.get(
{
"query": SearchQuery.build(
lambda q: (
q.keyword("day")
& q.group(
q.hashtag("#Twitter") | q.hashtag("Xcorp"),
)
& q.mention("@elonmusk")
& ~q.mention("SpaceX")
& q.is_retweet()
)
)
},
)
)
このようなクエリビルダは、比較的簡単に実装できる。
さて、私は API の入力側に TypeDict を用いた理由について、「入力部分の記述はなるべく少ないコード量で書きたい」と言っていたことを覚えているだろうか?
クエリビルダは記述が少し多めといえる。 SearchQuery を知らないといけない。しかし、対話的であるという観点からは現状クエリビルダの方が優れている。
もし Twitter の検索クエリの仕様を完璧に知っているのなら、直接文字列で次のように書くこともできる。
from twitter_api import TwitterApiClient
response_body = (
TwitterApiClient.from_oauth2_app_env()
.request("https://api.twitter.com/2/tweets/search/recent")
.get(
{
"query": "day (#Twitter OR #Xcorp) @elonmusk -@SpaceX is:retweet"
},
)
)
TypeScript であれば、これが正しいクエリであるのかを型チェックもできるだろう(残念ながら Python 3.11 ではまだできない)。
もちろん、それは面白い試みであるが、TypeScript であっても、現状ではクエリが正しいかの判定はできるが、文字列を書いている途中で補完候補が出たりはしないし、フォーマットを綺麗に整えてくれたりもしない。
SQL のようなものと異なり、Twitter の検索クエリのような特定のドメインの仕様までを完璧に記憶しているエンジニアは少ない。
実務では仕様を完全に覚えていなくても、何ができるのか簡単に選択できるような手段の方が好ましい。
将来的には、文字列ごとに異なる言語の補完やフォーマットを整えてくれる言語がでてくるかもしれない。
そうなると、次のようなコードもクエリビルダと同じように、補完候補やフォーマッタの恩恵を受けた開発ができるだろう。
users = query(`
SELECT
id,
name
FROM
users
WHERE
id = :id
`).execute({ id: 12345 })
しかし、現状では、まだそこまで発展していないようだ。
物理単位を明示する
もともとがハード屋であるため、単位系の扱いには少し敏感だ。私は物理単位は何であるかを明示する癖がある。
私が知る限りでは、下記のようなアプローチがある。
- 型で抑える:
calc(Hours(7) + MilliSeconds(12)) - 単位を表す定数で抑える:
calc(7 * Hours + 12 * MilliSeconds) - 引数名で抑える:
calc(hours=7, milliseconds=12)
対話的という観点からは、3番目の方法が好みだ。
単位の型・定数を import する 1 と 2 の方法では、Hours MilliSeconds の存在を知っていないといけないからだ。
特に 1 の方法は、言語レベルでのサポートがない場合は、プロジェクトで単位系の統一するためのコストが大きい。
ライブラリ側の提供する方法としては 3 が現実的な選択だと思う。
今回のライブラリでは、例えば下記のように使われている。
response_body = (
TwitterApiMockClient.from_oauth2_app_env()
.request("https://api.twitter.com/2/tweets/search/recent")
.get(
{
"query": SearchQuery.build(
lambda q: (
q.point_radius(
longitude_deg=135,
latitude_deg=45,
radius_km=5,
)
)
)
},
)
)
いずれの方法にせよ、物理単位が書いてある方が明確だ。
利用者はどの単位を入力すれば良いのか悩まずに済むし、単位変換ができていないことを察知することができる。
テストコード
APIのクライアントはテスト用の機能を提供すべきであると思う。
API を呼ぶコードをテストするために、自前でモック部分を記述するのは面倒だ。
そのため、今回のライブラリでも自前でテスト用の機能を用意した。
from twitter_api import TwitterApiClient, TwitterApiMockClient
def your_logic(twitter_client: TwitterApiClient):
...
def test_your_logic():
twitter_client = (
TwitterApiMockClient.from_oauth2_app_env()
.inject_post_response_body("https://api.twitter.com/2/tweets", post_response_body)
.inject_get_response_body("https://api.twitter.com/2/tweets/:id", get_response_body)
.inject_delete_response_body("https://api.twitter.com/2/tweets", delete_response_body)
)
assert your_logic(twitter_client) is True
ライブラリ側でモック機能を提供していると、自動テストを書くのも簡単だ。全ての公式 API クライアントは、モック機能まで提供して欲しいと考えている。
最後に
今回のライブラリは、APIクライアントがどのようなものであって欲しいかの私の見解を述べたものだ。
すべての Twitter API を網羅してはいないが、どのようなツールであって欲しいかの思想は感じ取れると思う。