はじめに
本記事は QualiArts Advent Calender 2019 16日目の記事です。
昨日は @tnbe21 さんの mongoDB3.2から3.4へのアップデート作業 でした。
明日は @Koheinimi さんの 開発ディレクターとしての役割 です。
QualiArtsのエンジニア施策の紹介
QualiArtsでは2019年前期にイノテックレポートという技術レポートをエンジニアが書く施策がありました。
また、後期はもくもく会という隔週で2時間の業務時間内に勉強時間を確保するエンジニア施策があります。
このアドベントカレンダーを書くにあたって
今回の内容はイノテックレポートの内容を外部用に加筆したもので、
このQittaはもくもく会の時間を使い編集しています。つまり業務時間でアドベントカレンダーを書きました(笑)
QualiArtsの空気感が少しでも伝われば良いと思いアドベントカレンダーに寄稿することを決めました。
TL;DR
RDSに格納されているログデータをAWS LamdaとAWS StepFunctionsを使ってサマリー集計処理で実現する。
Serverlessバッチアーキテクチャの実装
1. 概要と背景
サービスを運用する上で定期的にデータを更新するようなバッチ処理が必要なことがある。
バッチ処理を実行するにはJenkinsやcronなどを実行するサーバが必要だが、バッチ処理は単発的な処理もありサーバを常時立ちあげなくてもよい場合も多い。そこで、単発的なバッチ処理を実行にサーバレスを利用することで、必要なリソースのみを利用しコストの最適化を図りたい。
ただ、サーバレスサービスの一つであるAWS Lambdaではバッチ処理も実装出来るが、運用を考慮して例外や分岐処理を含めるとコードの量が膨大になったり実行時間の制約に抵触する可能性があった。
そこで、AWS Lambda関数をタスクとして実装し、AWS StepFunctionsを用いてパイプラインで繋ぎ、疎結合な関数群によって構成されるシステムの構築が可能となる。また、疎結合であるためタスク毎の再利用性も上がるというメリットも生まれる。
自分が担当しているサービスは分析用に1日のサマリーを集計するバッチがあり、
今回はこのディリー集計バッチをサーバレス環境に移行して、既存のバッチ用のJenkinsのインスタンスコストを軽減する足がかりにしたい。
2. 内容
2.1 全体の流れ
- 集計SQLを作成
- 2つのAWS Lamdaを作成
- 集計SQLを実行する AWS Lamdaを作成
- タスクの状態管理をする AWS Lamdaを作成
- AWS Lamdaを実行する AWS StepFunctionsを作成
- AWS StepFunctionsを実行するAWS CloudWatchEventを作成
2.2 集計SQLを作成
ここではRDSに各売上データが格納されているとし、売上データをOSと日付毎に集約したい。
具体的には group by で集計した結果を別のテーブルに書き込んでいる。
REPLACE INTO analytics_mid.daily_proceeds (
date,
os,
proceeds
)
SELECT
date,
os,
SUM(price) proceeds
FROM
analytics.log_xxxx
WHERE
type = 'xxx'
AND date like '{{dt}}%' -- 日付指定可能にしておく
GROUP BY date , os ;
ここで注意するべきはSQLの実行時間で、現在AWS Lambdaの実行時間が最長で15分なので必ず収めるようにする。
2.3 2つのAWS Lamdaを作成
2.3.1 集計SQLを実行する AWS Lamdaを作成
AWS Lamda関数では、上記で作成したSQLファイルを外部ファイルとして読み込みRDSコネクションを作成し、読み込んだSQLをDBで実行するスクリプトにした。これにより ./resources/sql/ 配下にSQLを配置すれば引数で実行出来るSQLをコントロール出来る。
import datetime
import pymysql
from jinja2 import Environment, FileSystemLoader
def query_bind_day(sql_name):
# 前日の日時を取得
JST = datetime.timezone(datetime.timedelta(hours=+9), 'JST')
target_day = (datetime.datetime.now(JST) - datetime.timedelta(
days=1)).strftime('%Y-%m-%d')
# ファイルを取得
j2_env = Environment(loader=FileSystemLoader("./resources/sql/"),
trim_blocks=True)
# 取得したSQLにデータ(前日の日付)をバインド
return (j2_env.get_template(sql_name).render(dt=target_day))
def lambda_handler(event, context):
# コネクションの作成
conn = pymysql.connect(host="host", port="port", db="db",
user="user", passwd="passwd")
# Lamdaの実行時に実行するSQLファイル名を外から指定できるようにしておく
filename = event.get("current").get("filename")
# SQLの実行
with conn.cursor() as cur:
sql = query_bind_day(filename)
cursor = conn.cursor()
cursor.execute(sql)
cursor.close()
conn.commit()
print(f'{filename} commit done.')
return event
2.3.2 タスクの状態管理をする AWS Lamda を作成
こちらは2.4で利用するワークロードを管理するための関数。
AWS StepFunctions では引数のデータをステートとして扱う。
ステートによって次の関数をコントロールするのが下記タスクになる。詳しくはステートマシン
を参照。
def lambda_handler(event, context):
"""
mid_table_daily_functionにつなげるためのデータを判定する処理
:param event:
:param context:
:return:
"""
current_index = event.get("current_index")
input_all = event.get("input_all")
if current_index == 0:
next_index = current_index
if event.get("current") != "":
next_index = 1
else:
next_index = current_index + 1
if next_index >= len(input_all):
event['end'] = 1
return event
event["current"] = input_all[next_index]
event["current_index"] = next_index
return event
2.4 集計SQL のAWS Lamda を実行する AWS StepFunctions を作成
【ワークロードの流れは】
0. 処理対象の集計テーブルのリストを引数として保持
1. Startで集計テーブルのリストを受け取り、InputIteratorに渡す
2. InputIteratorは集計テーブルのリストから、メインタスクのMidTableDailyLambdaProcessに渡すデータを選択
3. 次に処理すべき集計テーブルがあるかを判定
4. InputIterorからデータを受け取り、集計テーブルを作成
5. 次のメインタスクで処理するデータを取得
6. 次に処理すべき集計テーブルがあるかを判定
7. 処理すべき集計テーブルがない場合、終了
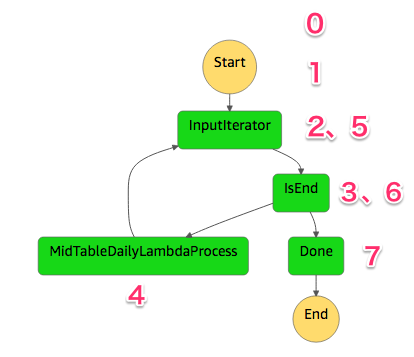
上記ワークロードをAWS StepFunctionsで実現するためには、下記のような AmazonStateLanguage で表現することが出来る。
{
"Comment": "mid_table_process",
"StartAt": "InputIterator",
"States": {
"InputIterator": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:0000:function:mid_table_iter",
"ResultPath": "$",
"Next": "IsEnd"
},
"IsEnd": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.end",
"NumericEquals": 0,
"Next": "MidTableDailyLambdaProcess"
}
],
"Default": "Done"
},
"MidTableDailyLambdaProcess": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:0000:function:mid_table_daily",
"ResultPath": "$",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error-info",
"Next": "CatchErrorSlackAlert"
}
],
"Next": "InputIterator"
},
"CatchErrorSlackAlert": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:0000:function:mid_table_slackalert",
"ResultPath": "$",
"Next": "InputIterator"
},
"Done": {
"Type": "Pass",
"End": true
}
}
}
上記 AmazonStateLanguage では各集計タクスがエラーを吐いた場合にSlack通知するタスクが含まれているが、今回は説明から省く。
2.5 AWS StepFunctionsを実行するAWS CloudWatchEventを作成
作成したAWS StepFunctionsを定期的に実行するためにAWS CloudWatchEventに登録する。
その際、AWS StepFunctionsに渡す定数を設定できる。

下記は引数の例です。 input_all でSQLを複数指定可能にしている。
{
"end": 0,
"current_index": 0,
"current": "",
"input_all": [
{
"filename": "daily_proceeds.sql"
}
]
}
まとめ
今回はJenkinsで実行していた集計処理をAWS StepFunctionsを利用して構築した。
AWS StepFunctionsを使うことで疎結合な関数群で構成されるシステムが構築でき、拡張や変更しやすいアプリケーションになった。
今後、他のバッチ処理をAWS StepFunctionsに置き換えていくことも検討する。