QualiArts Advent Calendar 2019 15日目担当の @tnbe21 です。
普段はNode.jsでゲーム機能やLPのサーバ側実装やコードレビューを行ったり
インフラ(ansibleとかterraform、fabricなどIaCやGCP、Jenkinsとか)の保守、
CS対応、PythonとかHiveQLとかで書いてある行動ログ集計バッチの保守など、
あるゲームのサーバーサイドのエンジニアリング全般を主に担当しています。
はじめに
ゲームサーバのデータベースにはMongoDBを用いています。
GCE(Google Compute Engine)上3.2系で稼働、
またクラウド上でレプリカセットやシャーディング構成や各ロールの設定保持(クラスタ管理)や監視、
バックアップなどを行ってくれるMongoDB Cloud Manager (MCM)も利用しているのですが、
-
MCMで主に活用されているのはバックアップ機能のみで、
クラスタ管理や各インスタンスのバージョン管理など
フルマネージドされている状態にしたい -
3.2系のEndOfLifeは昨年の9月、次の3.4系は来年の1月なので、
恐らくMCMフルマネージド環境で3.4に出来るデッドラインが来年の1月
(2月以降はいつまで3.4で構築できるかわからない)
-> 飛び級でアップデートするのはリスキーなので
ひとつ上の3.4へ来年の1月までにアップデートしたい
この2点を踏まえ来年1月をデッドラインとして
MCMフルマネージドな3.4へリニューアルするための準備をしてきました。
ステージング環境のリニューアル(=本番環境リニューアルのリハーサル)や
その際のフィードバックも加えた手順書の作成や準備は完了しており、
あとは本番環境のリニューアルを待つだけの状況となっています。
その試行錯誤の過程で得られた知見をお話しします。
手順
新規クラスタの作成
既存クラスタをアップデートするか
新規クラスタを作成しそこに移行するか2通りの方法が考えられますが、
3.4以降mongoc(クラスタのメタ情報を保持する設定サーバ群)の構成をSCCC型ではなくCSRS型に変える必要があったり、
そもそも後からMCM管理下に置こうとすると手順が煩雑になりそうだったので、
新規クラスタを作成しそこに移行する方法を採ることに決めました。
新たにGCEインスタンスを用意してMCMエージェントをセットアップして、
まっさらな3.4系で稼働するクラスタを作成します。
データ移行方法の検討
次はデータ移行方法を考えます。
MCMでバックアップは取られている状態でしたが、
-
先述の通りmongocが3.4以降未対応のSCCC型だったり、
mongocのDB(メタ情報DB)や実データRSのバックアップが別れて管理されていた関係か
MCMコンソール上から新規クラスタへ直接リストアすることが不可能
(-> だった?最近コンソールを閲覧してみたら可能そうだったかも?別の方法での手順が固まってしまったので未検証) -
各RSや設定DBのバックアップをダウンロードしてリストアする方法も難しい
ため、移行サーバを経由して
旧クラスタからmongodump、新クラスタへmongorestoreする形を採ることにしました。
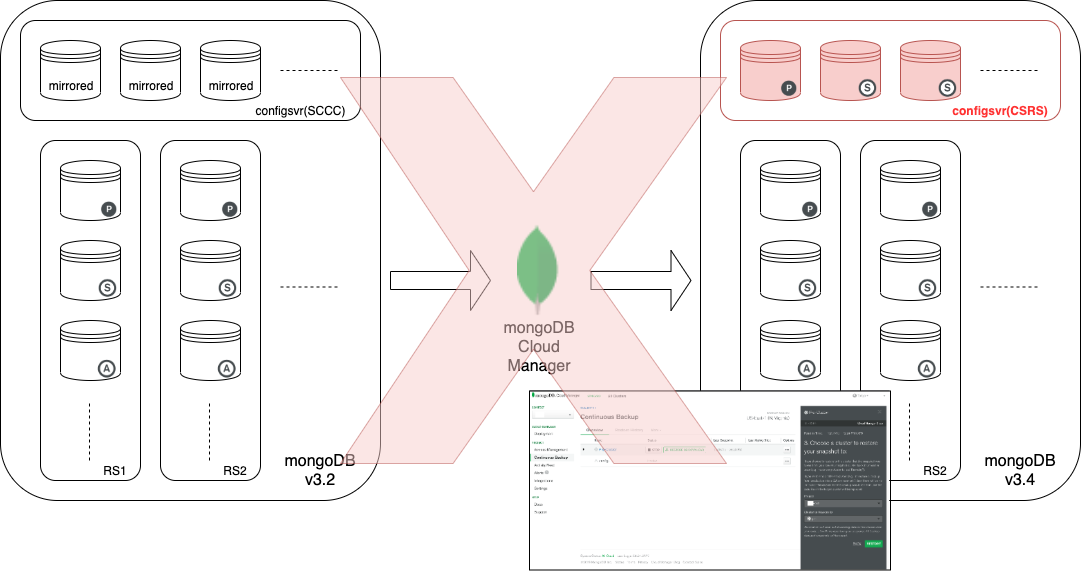
MCM上からのリストア
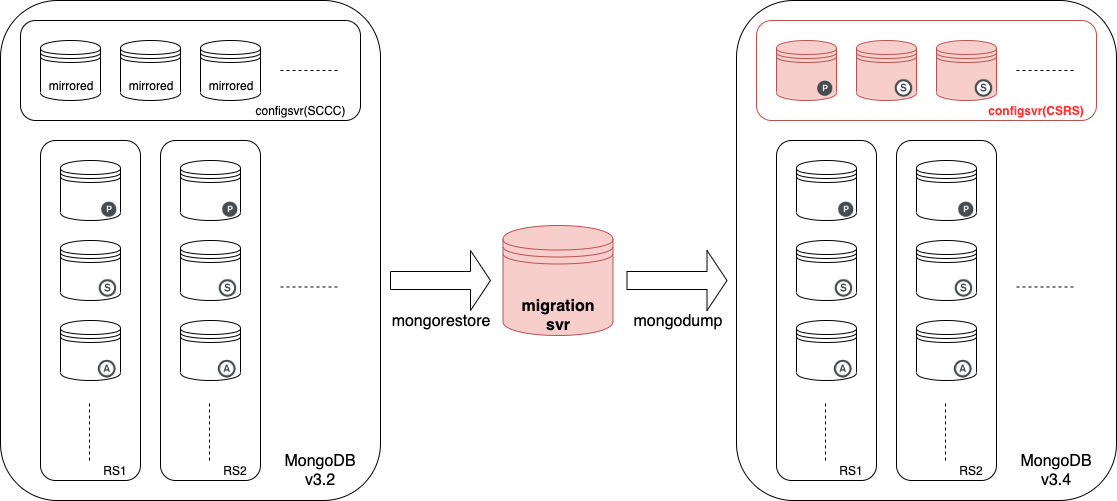
移行サーバ経由での手動リストア
ダンプ
移行サーバ上で既存クラスタを接続先としてmongosを起動し、mongodumpを実行します。
いずれも書いてみると単純ですが念のためトラップになりそうな点を言うと、
- 1度でダンプデータがディスクの半分以上を専有し、
2度3度と試す機会があったのでダンプの都度過去のデータ削除をしていました
ディスクフルになりそうになると途中で止まります - データベースを指定して実行(configDBのダンプは不要)
nohup mongodump --db {DB名} --out /data/mongodb/backup_`date +%Y%m%d%H%M` >
/data/mongodb/logs/dump_`date +%Y%m%d%H%M`.log &
新規クラスタに各コレクションのインデックスやシャードキーを作成
次は新規クラスタに向けてmongosを再起動し、
事前に対象のコレクションのインデックスやシャードキーを作成します。
リストア
引き続きmongosが新規クラスタ向けに起動されていることを確認した上でmongorestoreを実行します。
nohup mongorestore -v --writeConcern 1 --numInsertionWorkersPerCollection 8 --db {DB名} /data/mongodb/backup_{yyyymmddhhmm}/{DB名} > /data/mongodb/logs/restore_`date
+%Y%m%d%H%M`.log &
初め移行サーバはn1-standard-1で作成しており
numInsertionWorkersPerCollectionやwriteConcernオプションを指定せず実行していたところ
3h半ほどかかっていたのですが、
grep Tips *さんの記事を拝見し
マシンスペックをn1-standard-8 (8コア)に変更しこれらのオプションを設定することにより、
また後述しますが事前にチャンク情報が作成されている状態での実行で、
ドキュメント削除+リストアで1hと7分の2も減少することが出来ました。
記事のトレースとなりますが、
-
--numInsertionWorkersPerCollection: 各コレクションにinsertするワーカ数の指定
デフォルトは1で、CPUコア数辺りまでの指定でリストアの高速化が見込めます -
--writeConcern: writeConcern の指定
デフォルトはmajority = 所定レプリカセットで投票権をもつメンバの半数以上が
書き込みされたとみなされないと次のinsertに進みません
1を指定することでプライマリメンバに書き込まれた時点で次のinsertに進み、
デフォルトより高速化される見込みです
リストア処理以外での各コレクションへの書き込みがない状態の担保は必要です
金銭的コストとの兼ね合いはありますがCPUコア数を上げ上記の並列実行数指定を大きくすればするほど、
その分リストア時間はある程度まで短縮できるかと思います。
チャンク情報作成のための事前実行
NullPointer'sさんのこちらの記事に記載の通り
これらの作業を事前に実行しチャンク情報を予め作成しておきます。
本作業前に一度事前に実行しておくことでリストアの時間が減少するようです。
本実行
事前実行された状態からの本実行時のmongorestoreには注意が必要で、
書き込みはすべてinsertのためドキュメントの削除が必要です。
コレクションではなくドキュメントの削除です。
mongorestoreには--dropというオプションがあり
それによりドキュメントを削除した上でのリストアが可能ではありますが指定してはいけませんでした。
恐らくドキュメントの全削除ではなくコレクション自体のdropがされます。
改めてというかいつ何度見ても文字通りdropと書いてあるのに気づけよという感じですが、
リハーサル時に気づかずやらかしました・・
インデックスはmongodump時に作成されたダンプデータに基づきrestoreの際に改めて設定されますが、
シャードキーやチャンク情報は消えてしまうことになります。
# !/bin/sh
SCRIPT_NAME=remove_`date +%Y%m%d%H%M`.js
cat > $SCRIPT_NAME << EOF
function padZero(v) {
return v < 10 ? '0' + v : v;
}
function getDt() {
var date = new Date();
var ymd = [date.getFullYear(), padZero(date.getMonth() + 1), padZero(date.getDate())];
var time = [padZero(date.getHours()), padZero(date.getMinutes()), padZero(date.getSeconds())];
return ymd.join('-') + 'T' + time.join(':');
}
var cols = db.getCollectionNames();
for (var i = 0; i < cols.length; i++) {
var col = cols[i];
print(getDt() + ': ' + 'remove ' + col);
db[col].remove({});
print(getDt() + ': ' + 'finished removing ' + col);
}
EOF
mongo {db名} $SCRIPT_NAME
rm $SCRIPT_NAME
nohup sh remove.sh > /data/mongodb/logs/remove_`date +%Y%m%d%H%M`.log &
チャンク移行を止めるためバランサをオフにした上で
こんな感じのスクリプトを実行し事前にドキュメントのみ削除してから(dropするより時間がかかります)、
mongorestoreを--dropなしで実行します。
コレクション数の比較
リストア終了後新旧クラスタについて、
全ドキュメントすべての値が一致しているかどうかの確認までは行えないが
ドキュメントの数はせめてチェックしようということで、
db.collection.aggregate([
{ $group: { _id: null, count: { $sum: 1 } } }
]);
の結果の比較を行います。
もっと単純なコマンドで db.collection.count(); がありますが、シャードクラスタ環境では、
チャンク移行時失敗しクラスタ管理下から外れてしまった
orphaned document(孤児ドキュメント)もカウントされてしまい正確な数を取得することが出来ない場合があり、
aggregateによる上記のようなクエリでの取得の方が正確だと言われています。
まとめと感想
- mongocがSCCC型となっている3.2クラスタを3.4にアップデートする関係で、
MCM管理下で新規クラスタを作成して
移行サーバ経由でmongodump -> mongorestoreする手順をとることにした - mongorestoreはオプションチューニング、サーバのスケールアップで高速化できる
- さらなるリストア高速化のために事前のリストアを実施
- 本移行時のrestoreでは--dropは指定せず、
全コレクション db.collection.remove({}); をしてから実行する - 事前のリハーサルと手順書の作成は本当に大事
全データの移行でプレッシャーがかなりありますが、
その分MongoDBに関して高い密度で勉強することになり楽しかったです。
参考 
mongoDBクラスタにrestoreする時の高速化テクニック
https://paulownia.hatenablog.com/entry/2018/02/05/010704
mongorestoreを高速化する
https://www.greptips.com/posts/1261/
MongoDB Manual
https://docs.mongodb.com/manual/reference/program/mongodump
https://docs.mongodb.com/manual/reference/program/mongorestore
https://docs.mongodb.com/manual/reference/write-concern
https://docs.mongodb.com/manual/tutorial/manage-sharded-cluster-balancer
など多数