この記事は クローラー/Webスクレイピング Advent Calendar 2016 19日目の記事です。
最初に言っておくと、mitmproxy はスクレイピングツールでもクローリングツールでもありませんが、これをスクレイピングに活用するのが今回の記事の趣旨になります。
mtimproxy という最終兵器
mtimproxy は名前の通りプロキシーで、man-in-the-middle proxy の略だと思われます。Python 製の OSS です。
図で書くと、次のようなものです。いわば、自分で自分に中間者攻撃をするようなプロキシーのイメージでしょうか。
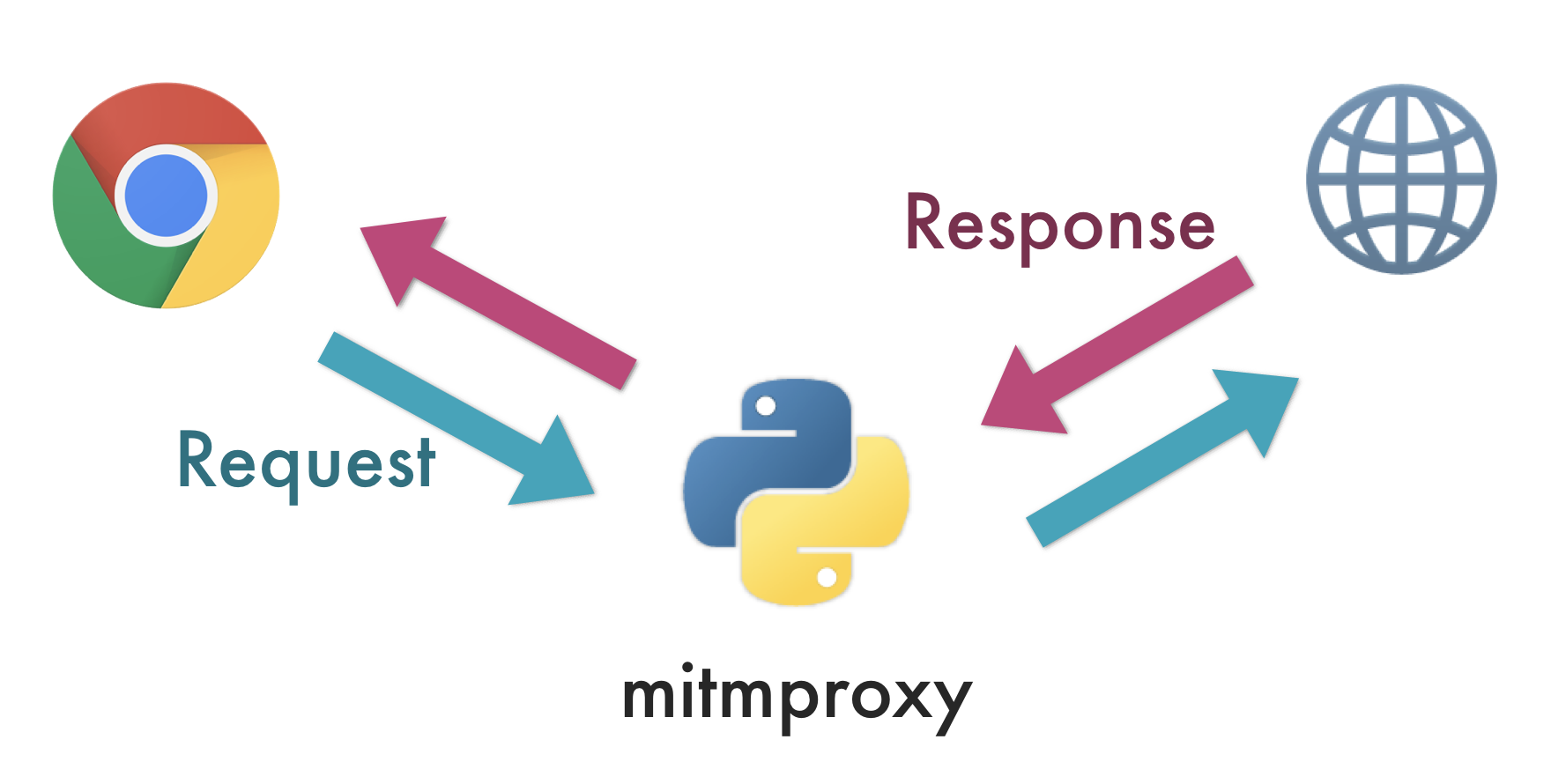
自分で書いてみて、あまりに意味のない図だったので少し驚いていますが、mitmproxy を使うと、
- 外部サイトに送るリクエストの内容をフックして、加工できる
- 外部サイトから届くレスポンスの内容をフックして、加工できる
ことができるので、閲覧したサイト全てを、Pythonのスクリプトで自動的に加工できるということになります。
Pythonでレスポンスを加工できるということは、レスポンスを保存できるということなので、一種のクローリングツールとして使える、ということです。
もちろん、mitmproxyはただのプロキシツールなので、自動的に何らかの戦略でクローリングしに行くことはできません。人間様が spider(bot) として稼働し、閲覧した結果を保存・スクレイピングするのが今回の戦略です。
具体的なユースケース
mitmproxy を使ったスクレイピングが最強な理由を説明しましょう。
- 人間様がどのページをダウンロードするかを決定するが、人間様は bot よりも賢い(2016年現在)
- 人間様は bot に比べて自然に振る舞う(2016年現在)
- プロキシが使えるなら、どんな態様のサイトでも保存できる
たとえば、次のようなユースケースがあるでしょうか。
- Javascript や Flash 製のサイトの API をクローリングしたい
- 自分が一日に見たサイトをまるっと分析したい
逆に、次のようなものは向かないと思います。
- 定時的にクローリングしたい
- 全世界中のサイトを自分ひとりでクローリングしたい
- SPA など、Javascript によるレンダリングが重要なサイトで、その結果をクローリングしたい
mitmproxy のインストール
インストールは簡単です。インストールにはまったら、公式の Docker 版とか使いましょう。
pip install mitmproxy
mitmproxy には2つのツールがあります。mitmproxyとmitmdumpです。前者は、CUI でインタラクティブなツールです。後者は、インタラクションをなくしたもので、スクレイピング用途ならこちらが良いでしょう。
起動方法は単純で、mitmdump とシェルに打ち込んであげるだけです。デフォルトでは、8080 番のポートで起動するので、127.0.0.1:8080 をプロキシとして指定してあげれば良いです(Chromeだと、Proxy SwitchySharp という拡張が使いやすいです)。
プロキシの設定がうまくいったら、適当なサイトを開いて下さい。うまくいくと、mtimdump が受け取ったコンテンツが、次のように表示されます。

mitmproxy でのスクレイピング方法
mitmproxy で Python スクリプトを実行する方法を紹介します。
mitmdump -s path_to_script.py
実行するスクリプトは、例えば次のようなものがあると思います。次の例は、Content Type が text/html のものだけ絞って、保存するものです。
def response(flow):
content_type = flow.response.headers.get('Content-Type', '')
path = flow.request.url.replace('/', '_').replace(':', '_')
if content_type.startswith('text/html'):
with open(path, 'w') as f:
f.write(flow.response.text)
もちろん、lxml などを使った要素の抽出などは適宜行えばよいかと思います。
その他、mitmproxy の機能を網羅した example は GitHub 上にあります。
まとめ
mitmproxy を使ったクローリングのテクニックをご紹介しました。人間様最高!
説明を省いてしまいましたが、SSL のサイトにも対応しています(詳細はググっていただけると)。
注意
今回の方法は、いわば中間者攻撃のような方法です。同意のない状態で他人に仕掛けた場合、立派な犯罪になるので絶対にやめて下さい。あくまで、自分の閲覧したサイトを、自分で保存して分析するために利用しましょう。また、利用規約によって禁止されている非公開の API の利用もやめましょう。