はじめに
時は2021年、「PoC死」と言われていた AI事業も徐々に導入事例が増える一方で、
機械学習サービスの継続的運用 (MLOps) の重要性が増しつつある。
その中で、AWSの機械学習サービスといえば必ず名前が挙がるのが Amazon SageMakerである。
本記事ではこの SageMakerの具体的な使い方のイメージを掴むために、
自作のコンテナイメージを用いて学習/推論を行うまでの一連の手順を示す。
これから AWSで機械学習を始める初学者の方々にとって、少しでも参考になれば幸いである。
また、興味があれば Azure Machine Learning版のこちらの記事も是非ご参照いただきたい。
---- 2024/07/16 追記 ----
この数年で AI 業界は激変し、生成 AI が主流となった。
最先端の生成 AI について徹底検証した以下の記事も併せてご参照いただきたい。
サマリ
完成図
本記事にて最終的に作成するアーキテクチャを下図に示す。
Amazon SageMakerでは最もオーソドックスな構成だと思われる。
※ Imageはコンテナイメージ、Trainは学習コンテナ、Serveは推論コンテナを表している。

このアーキテクチャを作成するまでの手順を、本記事では以下の3段階に分けて説明する。
- Step1/3. コンテナイメージの作成/動作確認
- Step2/3. AWSリソースの登録
-
Step3/3. SageMaker上での学習/推論実行

本記事の前提
- PC環境は Windows10 Proを使用し、Linux操作環境 (Git Bash) および
pipコマンドを導入済とする。 - AWSアカウントは作成済とし、アカウントIDは
222233334444とする。 - AWSリソースの命名ルールは
yamazo-qiita-{AWSリソース種別}を基本とする。- 例えば S3バケット名は yamazo-qiita-s3、ECRリポジトリ名は yamazo-qiita-ecr 等とする。
- 機械学習の題材は Kaggleの自然言語コンペを扱う。コンペについての説明は割愛する。
Step1/3. コンテナイメージの作成/動作確認
Step1/3では以下のことを行う:
- Dockerのインストール
- コンテナイメージの作成
- コンテナの動作確認 (ローカル)

Dockerのインストール
ローカルPC上で Dockerコンテナイメージを作成するために、
こちらの記事を参考に Docker Desktop for Windowsをインストールする。
基本的には Docker公式サイトにあるインストーラを実行するだけだが、
筆者のPC環境ではデフォルト設定だと警告 (WSL 2 installation is incomplete) が出力されて
Docker Daemonが起動しなかったため、ひとまず [Settings] → [General] から
[Use the WSL 2 based engine] のチェックを外して再起動したところ無事に起動した。
$ docker --version
Docker version 20.10.7, build f0df350
コンテナイメージの作成
詳細は Step3でも触れるが、SageMaker上でコンテナを用いた学習、あるいは推論を行うためには、
それぞれ下記 [要件1]、あるいは [要件2]~[要件4] を満たす必要がある:
- [要件1]
docker run {コンテナイメージID} trainコマンドで学習処理を実行する - [要件2]
docker run {コンテナイメージID} serveコマンドでエンドポイントを起動する - [要件3] healthcheck (
/pingへのHTTP GET) に対して 2秒以内に200 OKを返す - [要件4] 推論リクエスト (
/invocationsへのHTTP POST) に対して 60秒以内に200 OKを返す
より厳密にはポート番号 8080を使用する、ソケット通信を 250ms以内に受け入れる等もあるが、
ここでは割愛する。公式ドキュメントを参照いただきたい。
上記 [要件1]~[要件4] を満たすように、最終的に作成するコンテナ内の構成要素を下記に示す。
なお、今回は管理を楽にするために学習/推論を 1つのコンテナイメージにまとめる。
/opt/
├ yamazo-qiita/
│ ├ train # (1) 学習時に呼ばれる学習処理用スクリプト (自分で実装)
│ ├ serve # (2) 推論エンドポイント作成時に呼ばれるサーバ起動用スクリプト (公式サンプルの丸写し)
│ ├ predictor.py # (3) 推論エンドポイントがリクエスト受信時に呼ばれる推論処理用スクリプト (自分で実装)
│ ├ wgsi.py # (4) 推論リクエスト受信用インタフェース設定ファイル (公式サンプルの丸写し)
│ └ nginx.conf # (5) 推論リクエスト受信用設定ファイル (公式サンプルの丸写し)
│
└ ml/ # (6) SageMakerが勝手に作成するディレクトリ
├ input/data/{チャネル名}/ # (7) 学習前にS3からデータがDownloadされるパス
└ model/ # (8) 学習後にS3へデータがUploadされるパス
図中 (1)~(5) の学習/推論用スクリプトは本節にて後ほど作成する。
図中 (6)~(8) のディレクトリは SageMakerでコンテナ起動時に勝手に作成されるが、
ローカルで起動する際は代わりに以下ディレクトリをコンテナにマウントさせる。
なお、 {チャネル名} は yamazo-qiita-channelとする。
/c/yamazo-qiita-dir/
├ input/data/{チャネル名}/
│ └ train.csv # 今回使用する学習データ
└ model/
また、最終的な Dockerfileを以下に示す。
FROM nvidia/cuda:11.0-devel-ubuntu20.04
ENV PROGRAM_DIR=/opt/yamazo-qiita
ENV DEBIAN_FRONTEND=noninteractive
RUN mkdir -p $PROGRAM_DIR
WORKDIR $PROGRAM_DIR
RUN apt-get update
RUN apt-get install -y python3 python3-pip tzdata nginx
# 学習/推論の実装に必要なモジュール群をインストールする
RUN pip3 install -U numpy==1.19.5 pandas==1.1.5 torch==1.7.0 torchvision transformers==4.5.1 scikit-learn==0.24.1
# SageMaker上で使用する AWS SDKのモジュール等をインストールする
RUN pip3 install ipykernel && \
python3 -m ipykernel install --sys-prefix && \
pip3 install --quiet --no-cache-dir \
'boto3>1.0<2.0' \
'sagemaker>2.0<3.0'
RUN pip3 --no-cache-dir install flask gunicorn
# コンテナ内に学習/推論用スクリプト群を配置する
COPY train.py $PROGRAM_DIR/train
COPY serve.py $PROGRAM_DIR/serve
COPY wsgi.py $PROGRAM_DIR/wsgi.py
COPY predictor.py $PROGRAM_DIR/predictor.py
COPY nginx.conf $PROGRAM_DIR/nginx.conf
# train/serveを実行するためのパスを通す
ENV PATH=$PATH:$PROGRAM_DIR
# train/serveの実行権限を付与する
RUN chmod +x train
RUN chmod +x serve
Dockerfileの準備が済んだら、コンテナに配置する以下スクリプト (1)~(5) を実装する。
ここでは AWS公式のサンプル実装およびその説明書きを参考に進める。
train.py # (1) 学習時に呼ばれる学習処理用スクリプト (自分で実装)
serve.py # (2) 推論エンドポイント作成時に呼ばれるサーバ起動用スクリプト (公式サンプルの丸写し)
predictor.py # (3) 推論エンドポイントがリクエスト受信時に呼ばれる推論処理用スクリプト (自分で実装)
wgsi.py # (4) 推論リクエスト受信用インタフェース設定ファイル (公式サンプルの丸写し)
nginx.conf # (5) 推論リクエスト受信用設定ファイル (公式サンプルの丸写し)
(1) train.pyには学習処理を実装する。
ただし、コンテナに配置時はファイルの拡張子 (.py) を取る必要があるため、
1行目には shebang (スクリプト実行時のインタプリタ指定) を記述する。
#!/usr/bin/env python3
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
DATA_PATH = "../ml/input/data/yamazo-qiita-channel/train.csv" # S3からDownloadされる学習データ
MODEL_PATH = "../ml/model/model_1.pth" # S3へUploadされるモデル
train_df = pd.read_csv(DATA_PATH)
class MyModel(nn.Module):
def train():
...
torch.save(model.state_dict(), MODEL_PATH)
...
...
model = MyModel()
model.train()
(2) serve.pyには推論用エンドポイントの起動処理を実装する。
今回は AWS公式サンプルの gunicorn + nginx構成をそのまま流用し、
設定ファイルのパスだけ修正する。1行目には train.pyと同様に shebangを書くこと。
#!/usr/bin/env python3
import multiprocessing
import os
import signal
import subprocess
import sys
...
def start_server():
nginx = subprocess.Popen(['nginx', '-c', '/opt/yamazo-qiita/nginx.conf']) # ここだけ変更
gunicorn = subprocess.Popen(['gunicorn',
'--timeout', str(model_server_timeout),
'-k', 'sync',
'-b', 'unix:/tmp/gunicorn.sock',
'-w', str(model_server_workers),
'wsgi:app'])
...
if __name__ == '__main__':
start_server()
(3) predictor.pyには healthcheck処理と推論処理を実装する。
今回は AWS公式サンプルと同じく flaskでリクエストを振り分ける。
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import flask
MODEL_PATH = "../ml/model/model_1.pth" # S3からDownloadされるモデル
class MyModel(nn.Module):
...
model = MyModel()
model.load_state_dict(torch.load(MODEL_PATH))
def predict(): # ここに推論処理を実装する
model.eval()
...
app = flask.Flask(__name__)
@app.route("/ping", methods=["GET"]) # healthcheckリクエスト時の処理
def ping():
status = 200
return flask.Response(response="\n", status=status, mimetype="application/json")
@app.route("/invocations", methods=["POST"]) # 推論リクエスト時の処理
def transformation():
data = flask.request.data.decode("utf-8")
s = io.StringIO(data)
data = pd.read_csv(s)
predictions = predict(data) # 推論処理を呼び出す
out = io.StringIO()
pd.DataFrame({"results": predictions}).to_csv(out, header=False, index=False)
result = out.getvalue()
return flask.Response(response=result, status=200, mimetype="text/csv")
(4) wgsi.pyは predictor.pyのラッパーである。AWS公式サンプルを丸写しする。
import predictor as myapp
app = myapp.app
(5) nginx.confは HTTPリクエストの制御設定 (例えばポート番号やタイムアウト値等) である。
こちらも AWS公式サンプルをそのまま丸写しする。
worker_processes 1;
daemon off;
...
http {
...
server {
...
listen 8080 deferred;
client_max_body_size 5m;
keepalive_timeout 5;
proxy_read_timeout 1200s;
location ~ ^/(ping|invocations) {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_pass http://gunicorn;
}
}
}
コンテナの動作確認 (ローカル)
全てのスクリプトを実装した後はコンテナイメージの動作確認を行う。
まずは docker buildコマンドで Dockerfileからコンテナイメージを作成する。
その後 docker imagesでイメージ一覧を出力し、コンテナイメージの IDを控える。
$ docker build ./ -t yamazo-qiita-image
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
yamazo-qiita-image latest 3d61b4bfa011 57 seconds ago 6.82GB
続いて、コンテナイメージが以下 4つの要件 (再掲) を満たすことを確認する。
- [要件1]
docker run {コンテナイメージID} trainコマンドで学習処理を実行する - [要件2]
docker run {コンテナイメージID} serveコマンドでエンドポイントを起動する - [要件3] healthcheck (
/pingへのHTTP GET) に対して 2秒以内に200 OKを返す - [要件4] 推論リクエスト (
/invocationsへのHTTP POST) に対して 60秒以内に200 OKを返す
まずは trainコマンドで学習処理を実行してみよう。
先述した通り、SageMaker上で学習処理を実行すると、S3上にある学習データが
コンテナ内のディレクトリ /opt/ml/input/data/{チャネル名}にダウンロードされる。
ローカルの検証では、S3からコンテナ内にファイルがダウンロードされた状態を想定し、
前節で作成したローカルディレクトリを -vでコンテナにマウントさせて学習処理を実行する。
$ docker run -v "C:\yamazo-qiita-dir":/opt/ml/ {コンテナイメージID} train
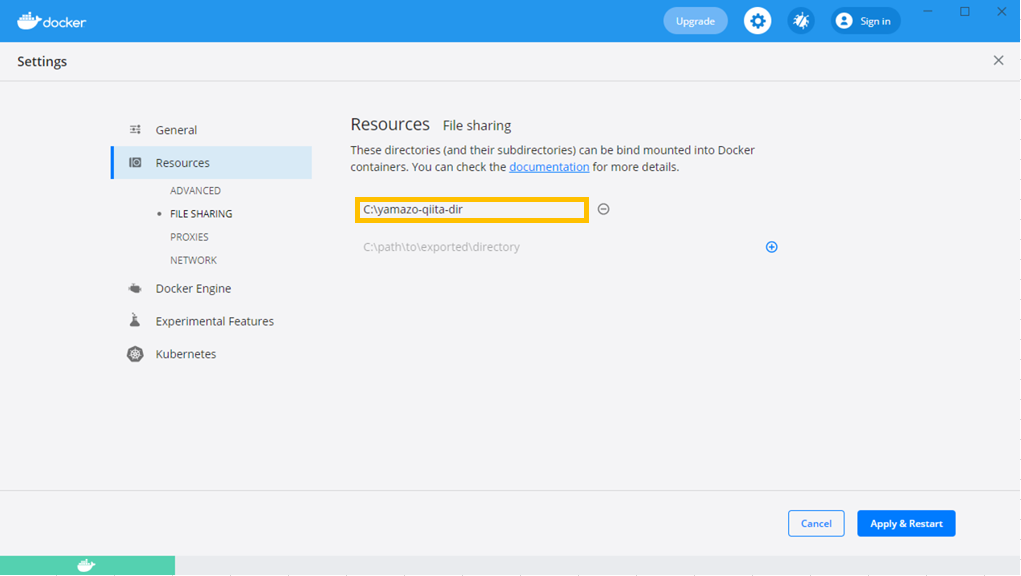
なお、Docker for Windowsを使用する場合、
コンテナにマウントするディレクトリを予め [FILE SHARING] に登録しないと起動できないため注意。
学習処理が完了したら、コンテナ上のパス /opt/ml/model/としてマウントしたディレクトリに
モデルが保存されていることを確認する。SageMaker上で学習処理を実行した場合は、
このパスにあるファイル群が全て S3にアップロードされる。
$ ls /c/yamazo-qiita-dir/model/
model_1.pth
次に、serveコマンドで推論用エンドポイント (つまりコンテナ) を起動する。
SageMakerでの推論時にはコンテナ上の /opt/ml/model/下にモデルがダウンロードされるため、
学習時と同様に、ローカルディレクトリをマウントすることで疑似的に同じ状況を作る。
コマンドを実行するとコンテナが起動し、HTTPリクエストを受信できる状態になるはずだ。
$ docker run -v "C:\yamazo-qiita-dir":/opt/ml/ {コンテナイメージID} serve
[2021-08-25 20:18:10 +0000] [13] [INFO] Starting gunicorn 20.1.0
[2021-08-25 20:18:10 +0000] [13] [INFO] Listening at: unix:/tmp/gunicorn.sock (13)
[2021-08-25 20:18:10 +0000] [13] [INFO] Using worker: sync
[2021-08-25 20:18:10 +0000] [16] [INFO] Booting worker with pid: 16
[2021-08-25 20:18:10 +0000] [17] [INFO] Booting worker with pid: 17
実際に推論用エンドポイントに healthcheck、および推論処理のリクエストを送信してみる。
それぞれ、 /pingへの HTTP GET、および /invocationsへの HTTP POSTを送信すればよい。
Docker内部からコマンド実行するために、ここではまず docker psコマンドで
起動したコンテナIDを特定後、docker execコマンドでコンテナ内部のコンソールを表示している。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
78a7d3f6b360 3d61b4bfa011 "serve" 29 seconds ago Up 26 seconds dazzling_liskov
$ winpty docker exec -it {コンテナID} bash
# curl -v http://localhost:8080/ping
# curl -v http://localhost:8080/invocations -X POST -H "Content-Type: text/csv" -d $'id,url_legal,license,excerpt\nID001, URL001, 1, I have a dream.\nID002, URL002, 2, I have a pen.'
0.20822687447071075
-0.02715710550546646
以上で Dockerコンテナの動作確認は完了だ。
もし途中でエラーが発生した場合、下記コマンドで Dockerコンテナの出力ログを確認できる。
$ docker logs -f {コンテナID}
Step2/3. AWSリソースの登録
Step2/3では以下のことを行う:
- AWSリソースの作成 (ECR/S3/IAM)
- AWS CLI設定
- AWS上に学習データ/コンテナイメージを転送
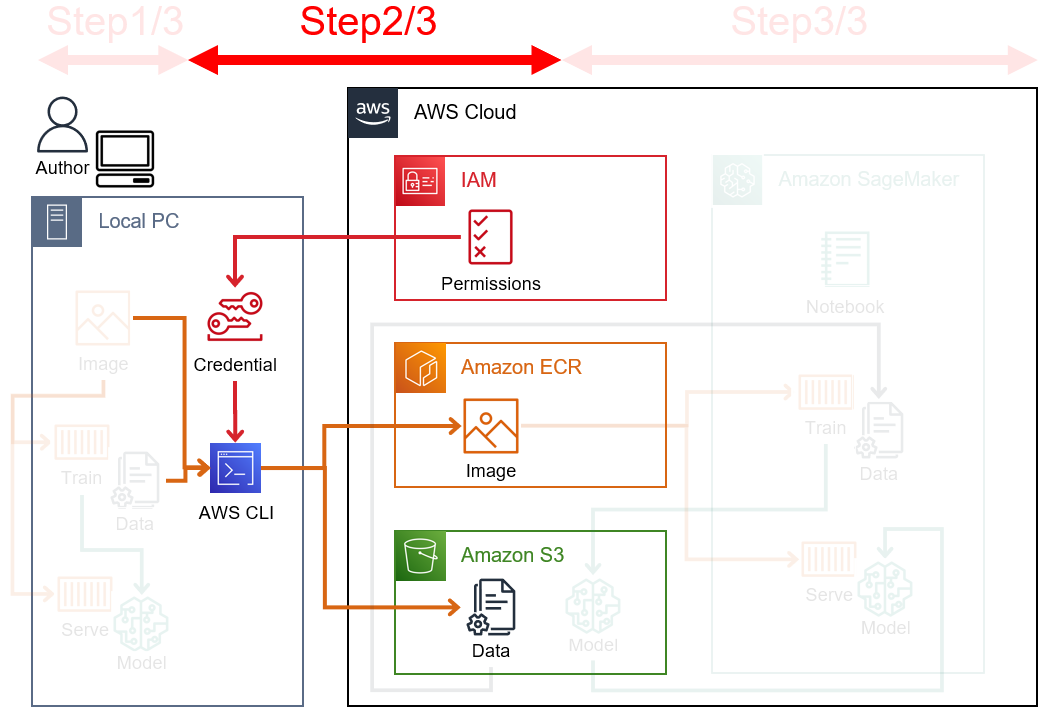
AWSリソースの作成 (ECR/S3/IAM)
学習で使用するデータおよびコンテナイメージのストレージとして、
それぞれ S3バケットと ECRリポジトリを AWSコンソール画面上で作成する。
リージョンは東京リージョン (ap-northeast-1) を指定する。
これらの作業は GUI操作で非常に直感的に行えるため、手順の詳細は割愛する。
S3バケットは yamazo-qiita-s3という名前で作成し、

ECRリポジトリは yamazo-qiita-ecrという名前で作成する。

ちなみに、S3および ECRは作成しただけでは課金されない。
これらはストレージ保存ファイルの合計サイズ数におおよそ比例して課金される。
料金の目安として、例えば ECRに 100GBのイメージ、S3に 600GBのデータを保存した場合、
それぞれ 10USD/月、15USD/月程度のストレージ料金が発生する。
※より厳密には無料枠やデータ転送料等も考慮が必要。
次に、ローカルPCから ECRや S3にデータを転送するための権限設定、つまり IAMユーザを作成する。
IAMユーザには S3FullAccessと AmazonEC2ContainerRegistryFullAccessをアタッチする。
作成した IAMユーザの Credential情報 (AccessKey/SecretKey) は次節にて使用するため控えておく。

AWS CLI設定
本節ではローカルPCから AWSコマンドを使用して AWS上にコンテナやデータを転送するための設定、
つまり AWS CLIの設定を行う。まずは pipコマンドで PCに AWS CLIをインストールする。
$ pip install awscli
次に、AWS公式サイトを参考に、AWS CLIコマンドの権限 (Credential) を設定する。先ほど控えた
AccessKey/SecretKeyを入力後、リージョンは東京リージョン (ap-northeast-1) を入力する。
$ aws configure
AWS Access Key ID [None]: AKIAXXXXXXXXXXXJBC
AWS Secret Access Key [None]: XXXXXXXXXXXXXXXXXXXXXXXXXXXRJ1t
Default region name [None]: ap-northeast-1
Default output format [None]:
$
この設定の元、ローカルPC上で AWSコマンドを実行すると、
先ほど作成した IAMユーザの権限が適用されることになる。
試しに S3や ECRの一覧を取得すると、結果が出力されるはずである。
(ECRにはまだイメージを登録していないため、空の結果が出力されている)
$ aws s3 ls s3://yamazo-qiita-s3
PRE data/
PRE models/
$ aws ecr list-images --repository-name yamazo-qiita-ecr
{
"imageIds": []
}
AWS上に学習データ/コンテナイメージを転送
ローカルPCに AWS CLIの設定が完了したら、AWS上に学習データとコンテナイメージを送信する。
ECRはログインを忘れると認証エラー (no basic auth credentials) で送信が失敗するため注意。
$ aws s3 cp ./train.csv s3://yamazo-qiita-s3/data/train.csv
$ aws ecr get-login-password | docker login --username AWS --password-stdin https://222233334444.dkr.ecr.ap-northeast-1.amazonaws.com
Login Succeeded
$ docker tag yamazo-qiita-image 222233334444.dkr.ecr.ap-northeast-1.amazonaws.com/yamazo-qiita-ecr
$ docker push 222233334444.dkr.ecr.ap-northeast-1.amazonaws.com/yamazo-qiita-ecr
Step3/3. SageMaker上での学習/推論実行
ここまで準備が済んだら、いよいよ SageMaker上で学習/推論処理を動かしてみる。
なお、SageMaker上の実装は非常に簡単である。Step3/3では以下のことを行う:
- SageMaker Studioの初期設定
- 学習処理 (トレーニングジョブ) の実行
- 推論用エンドポイントの作成&推論処理の実行
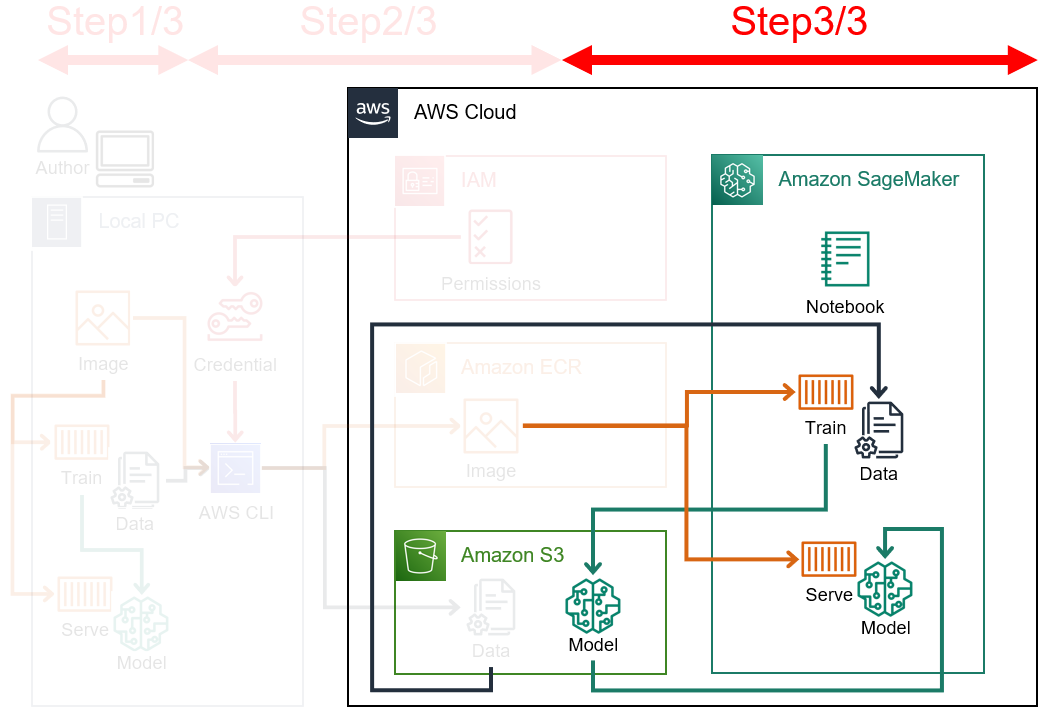
ここからは EC2インスタンスの停止忘れによる無駄な課金が発生しないように気を付ける。
[サービス] → [Billing] で課金状況を参照できるため、定期的にチェックしておくとよい。
閾値を超えるとメール通知する設定も可能だが、手順についてはこちらの記事を参照いただきたい。
SageMaker Studioの初期設定
SageMaker Studioとは SageMakerの統合開発環境 (IDE) である。
SageMaker Studioのリソース単位を理解するために、AWS公式サイトの概念図を以下に示す。

| リソース名 | 単位 | 備考 |
|---|---|---|
| ドメイン | リージョン毎に1つ | SageMaker Studioの 1プロジェクト。認証方法をSSO/IAMから選択可能。 |
| ユーザ | 1ドメインにNつ | SageMaker Studioにログインするユーザ。 |
| JupyterServerApp | 1ユーザに1つ | SageMaker Studioの操作画面。ユーザ毎に独立している。 |
| KernelGatewayApp | 1ユーザにNつ | Notebook Kernelを起動する EC2インスタンス。EC2内ではコンテナが動作している。起動時間に比例して課金される。 |
| Notebook Kernel | 1KernelGatewayAppにNつ | コンテナ上の Jupyter Notebookプロセス。同一インスタンスタイプの Notebookは同じ KernelGatewayAppに属する。 |
| EFS | 1ユーザに1つ | EFSの実態 (リソースID) は 1ドメインに 1つだが、ユーザ毎に論理的に独立している。ストレージ使用量に応じて課金される。 |
それでは実際に SageMaker Studioの初期設定を進める。
上の概念図において、左から順にリソースを作成していくことになる。
まずは SageMaker Studioのドメインおよびユーザを作成する。
- [サービス] → [SageMaker] → [SageMaker Studio] から SageMaker Studioを作成
- ユーザの実行ロール (IAMロール) には
AmazonSageMakerFullAccessをアタッチ
この時点で、JupyterServerAppおよび永久ストレージとして EFSが作成される。
実際に、SageMaker Studio上で Notebookを起動してみよう。
[{ユーザ名}] → [Studio を開く] から JupyterServerApp画面を開き、
下図の黄枠をクリックすると、Notebookが表示される。

ちなみに、本画面から自作のコンテナイメージを Notebookの実行環境として指定することも可能だ。
詳しい設定手順についてはこちらの記事を参照いただきたい。
Notebookを開くと、自動的に実行環境のインスタンスが裏で起動される。
下図は Notebook Kernelを3つ起動した例である。

図中①の [KERNEL SESSIONS] 部分に現在実行中の Notebookが 3つ表示されている。
一方、[RUNNING INSTANCES] 部分にはインスタンスが 2つしか表示されていないが、
これは 2つの Notebookが同じインスタンスタイプ (ml.t3.medium) を指定しており、
同一のインスタンス (KernelGatewayApp) を共有しているためだ。図中②はコードの実行場所であり、
以下ではここに処理を実装していく。なお、実行環境のスペックは図中③から変更可能だ。
学習処理 (トレーニングジョブ) の実行
Notebookの実装準備が整ったので、実際に学習処理を実行する。
学習処理は fit({'チャネル名':'S3パス'})で呼び出す。この引数指定により、
S3パス下の全ファイルがコンテナのディレクトリ /opt/ml/{チャネル名}下にコピーされる。
import sagemaker
from sagemaker.estimator import Estimator
estimator = Estimator(
image_uri="222233334444.dkr.ecr.ap-northeast-1.amazonaws.com/yamazo-qiita-ecr:latest",
role=sagemaker.get_execution_role(),
instance_type="ml.p3.2xlarge",
instance_count=1,
)
estimator.fit({'yamazo-qiita-channel':'s3://yamazo-qiita-s3/data/input/'})
fit関数を呼び出すと、SageMaker内部では学習用コンテナを動かすためのインスタンスが起動し、
docker run {コンテナイメージID} trainに相当する処理が実行される。
このコマンドに見覚えのない方は Step1の [要件1]~[要件4] をもう一度確認いただきたい。
学習処理が終了するとインスタンスは自動で削除される。
推論用エンドポイントの作成&推論処理の実行
学習の次は推論を行う。まず、deploy関数で推論用エンドポイントを作成する。
my_predictor = estimator.deploy(initial_instance_count=1,instance_type='ml.t2.medium')
# ---------------------------------------------!
deploy関数を実行すると、推論用コンテナを動かすためのインスタンスが起動し、
docker run {コンテナイメージID} serveに相当する処理が実行される。
エンドポイント作成後もインスタンスは削除されない。
また、このタイミングから /pingへの HTTP GETによる healthcheckが行われる。
SageMaker上の出力で---------!と「!」マークが出たら起動が成功している。
エンドポイント名は [Amazon SageMaker] → [エンドポイント] から確認可能だ。

作成したエンドポイントで推論処理を実行する場合は、predict関数を呼び出す。
もうお分かりかとは思うが、SageMaker内部では /invocationsへの HTTP POSTが実行される。
my_predictor.predict(data='id,url_legal,license,excerpt\nID001, URL001, 1, I have a dream.\nID002, URL002, 2, I have a pen.')
# b'0.20822687447071075\n-0.02715710550546646\n'
ちなみに、このエンドポイントは一般的な APIリクエストも受信可能である。
例えば Pythonの AWS SDKである Boto3を使用して、通常の APIと同様に推論処理を呼び出せる。
import boto3
client = boto3.client('sagemaker-runtime')
custom_attributes = "idxxxxx-yamazo-qiita-aaaa-1234567890ab" # トレース用ID
endpoint_name = "yamazo-qiita-ecr-2021-08-26-11-34-55-453" # 推論エンドポイント名
content_type = "text/csv" # コンテンツタイプ
payload = b'id,url_legal,license,excerpt\nID001, URL001, 1, I have a dream.\nID002, URL002, 2, I have a pen.'
response = client.invoke_endpoint(
EndpointName=endpoint_name,
Body=payload
)
print(response['Body'].read())
# b'0.20822687447071075\n-0.02715710550546646\n'
以上、ここまでが SageMaker Studioの基本的な使い方である。
一通りの検証が済んだら、起動したエンドポイントを削除する。
sagemaker.predictor.Predictor.delete_endpoint(my_predictor, delete_endpoint_config=True)
振り返り
本記事では AWSの機械学習サービスである Amazon SageMakerについて、
筆者自身も勉強しながら基本的な構築手順を紹介した。少しでも参考になれば幸いである。
また、SageMakerには他にも様々な機能があり、例えば下記等が挙げられる。
- 実験管理サービス (Amazon SageMaker Experiments)
- ETLサービス (Amazon SageMaker Data Wrangler)
- CI/CDサービス (Amazon SageMaker Pipelines)
これらについては【応用編】として、時間ができたタイミングで別途記事を書きたいと思う。