序文
前回mecabだけを使っていたらうまくいかなくて、そのまま世にお披露目をしたところ各方面(qiitaやtwitterやほぼ全方面)から「IPA辞書だけで日本語いけると思うな、NEologdを使え」とのまさかりが飛んできたのでありがたく 顔面 正面から受け止めてみました。
また、ElasticsearchのPluginで日本語解析ができる elasticsearch-analysis-kuromoji も使ってみました。
構想した時点での所感(口語調)
- NEologdは現代語に対応しているらしいけど、今流行りだしたばかりの新語が横行するTwitterでどこまで通用するだろうか。
- kuromojiは日本語分割はできるらしいけど、どこまで現代語的なのだろうか。リプやハッシュタグを取り除く方法はよく分からないな。
環境
前回をご参照ください。
作業したこと
- NEologdのインストール
githubから引っ張ってきます。
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
アップデートを取り込むには以下のようです。
$ ./bin/install-mecab-ipadic-neologd -n
次のコマンドで、NEologdがインストールされた場所を探します。
$ echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
使い方は、pythonのコードでご紹介。
Elasticsearchがインストールされてる場所($ES_HOME)で以下を実行します。
$ sudo bin/elasticsearch-plugin install analysis-kuromoji
今回は、textフィールドを解析するので、以下のtemplateを投入します。(もちろんElasticsearchを起動してからです。)
curl -XPUT --user elastic:changeme localhost:9200/_template/text_analysis?pretty -d '{
"template": "twitter-*",
"settings": {
"analysis": {
"tokenizer": {
"kuromoji_user_dict": {
"type": "kuromoji_tokenizer",
"mode": "normal"
}
}
}
},
"mappings": {
"twitter": {
"properties": {
"text": {
"type": "text",
"fielddata": true,
"analyzer": "kuromoji",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
}'
--user elastic:changeme は、x-packをインストールした後のcurlの投げ方です。ちなみにusername=elastic、password=changemeです。(ごめんなさいまだパスワード変えてません)
- Twitterから情報収集
Twitter APIの使い方は前回をご覧ください。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from requests_oauthlib import OAuth1Session
import json
import MeCab
CK = '***********'
CS = '***********'
AT = '***********'
AS = '***********'
url = "https://api.twitter.com/1.1/search/tweets.json"
# here can be set ID of tweet (ordered by time), and number of tweets (default is 20, max 200)
params = {'q':'#逃げ恥', 'count':'200'}
# GET request
twitter = OAuth1Session(CK, CS, AT, AS)
req = twitter.get(url, params = params)
f = open("json/search_nigehaji.json","a")
if req.status_code == 200:
timeline = json.loads(req.text)
print(timeline)
for tweet in timeline["statuses"]:
word_array = []
mecab_combo = [[] for j in range(3)]
word_combo = []
print(tweet)
for word in tweet["text"].split(" "):
word_array.append(word)
print(word)
if (not word.startswith('http')) and (not word.startswith('@')) and (word != 'RT'):
tagger = MeCab.Tagger(' -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
text_str = word.encode('utf-8')
node = tagger.parseToNode(text_str)
mecab_array_noun = [];mecab_array_verb = []
while node:
mecab_word = node.surface.decode("utf-8")
pos = node.feature.split(",")[0]
mecab_combo[0].append(pos)
mecab_combo[1].append(mecab_word)
mecab_combo[2].append(node.feature.split(",")[6])
if pos == "名詞":
mecab_array_noun.append(mecab_word)
print(pos)
print(mecab_word)
elif pos == "動詞":
mecab_array_verb.append(mecab_word)
print(pos)
print(mecab_word)
print(node.feature.split(",")[6])
node = node.next
print(mecab_combo)
print("###########")
print(len(mecab_combo[0]))
for i in xrange(0, len(mecab_combo[0])):
print("########################################")
print(mecab_combo[0][i])
stage_count = 0
if mecab_combo[0][i] == "名詞":
print("start for")
l = []
for j in xrange(i, len(mecab_combo[0])):
print(mecab_combo[1][j])
if mecab_combo[0][j] == "名詞":
l.append(mecab_combo[1][j])
word_combo.append(''.join(l))
print(''.join(l))
elif mecab_combo[0][j] in ["助詞", "助動詞", "動詞"]:
if stage_count != 0:
break
l.append(mecab_combo[1][j])
word_combo.append(''.join(l))
stage_count += 1
print(''.join(l))
else:
print(''.join(l))
print("end")
break
if mecab_combo[0][i] == "動詞":
print("start for")
l = []
for j in xrange(i, len(mecab_combo[0])):
print(mecab_combo[1][j])
if mecab_combo[0][j] == "動詞":
l.append(mecab_combo[1][j])
word_combo.append(''.join(l))
print(''.join(l))
elif mecab_combo[0][j] in ["形容詞", "助詞"]:
l.append(mecab_combo[1][j])
word_combo.append(''.join(l))
print(''.join(l))
print("end")
break
else:
print(''.join(l))
print("end")
break
print("%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%")
#injection
tweet['words']=word_array;tweet['mecab_noun']=mecab_array_noun;tweet['mecab_verb']=mecab_array_verb;tweet['word_combo']=word_combo
json.dump(tweet, f)
f.write('\n')
else:
print("Error: %d" % req.status_codea)
前回と違う点はまず、NEologdを適用した点です。
tagger = MeCab.Tagger(' -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
あとは、前回の反省を生かして、URLリンク(httpから始まる)やリプライ(@から始まる)やRTを除いたりもしてますが、
一番大きいところは、名詞+名詞+…や名詞+助詞+名詞などをまとめあげているところです!
ヒットワードを拾うために工夫してみました。
パターンはいくらでも自分で増やせます。
これで例えば…
星野源
月曜日のたわわ
結果
なんか今ちょうど最終回の一番いいシーンで抱きついてるんですが…それは置いておいて。。
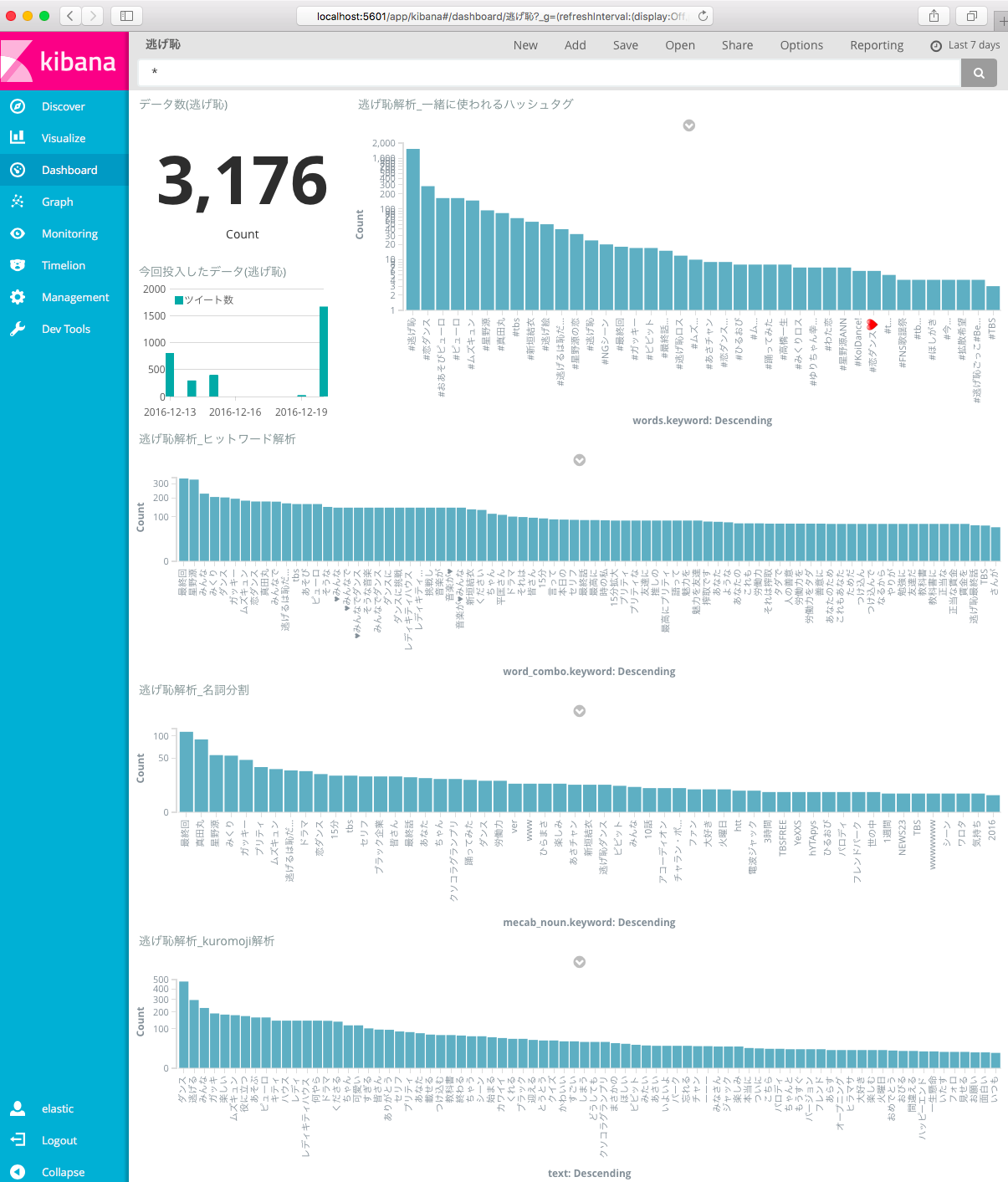
だいぶ、いい結果が出たと思います!
ハッシュタグ以外の逃げ恥解析グラフにはX-AxisのAdvanced->Exclude Patternに
.*https.*|\#.*|逃げ恥|.|..
を指定してあります。
日本語解析の方ですが、kuromojiも、mecab(名詞分析)も、何となく登場人物や役者やシーンが想像できますね。
pythonを噛ませるほどのやりたいことがなければkuromojiですね。
そしてヒットワード解析ではみんながセリフをそのまま呟くようで…
最高にプリティ
とか
労働力をタダ
とか
人の善意
とか
15分拡大
とかがランクインしてますね。
僕、2話だけ見てからずっと見てないし、最終回も最初と最後の5分くらいしか見てないので、
これらのキーワードが何の話だか分からないんですがきっとそんなセリフがあったんでしょう(ひとごと)
さて、寝ましょうか。あのシーンはワシには強すぎた…。