パワーアップしました!!
はじめに
ツイッターを見ていると時々回ってくるアプリメーカーで
仲のいい人・マイブーム(よく呟く単語)などなど…
なんてよくありますよね、やりますよね。
本当か?って思うこと、あるじゃないですか。
あ、業務効率化じゃないけど書きます。新人です。
業務を効率化したいとお悩みの方はこちらをご参照ください。
みんなツイッターのタイムラインをどうやって取得して、どうやって処理するか、気になりませんか?
私は気になります。
そういう好奇心って、大事ですよね。
こうやるみたいです。
環境
- macOS Sierra 10.12.1
- Emacs 22.1.1
- Python 2.7.10
- Mecab 0.996
- Mecab-ipadic 2.7.0-20070801
- Logstash 5.0.1
- Elasticsearch 5.0.1
- Kibana 5.0.1
但し書き
水曜のお昼に思いついて、その日から2晩で作ったのでコンテンツのクオリティには限りがあります。
環境構築
- Macbook
みなさんMacbookは持ってますか?たまたま今持ってないんだよーという人はまずApple Shopに行ってください。
そしたらとりあえずEmacsとPythonを入れておけば良いです。
- ツイッター開発者アカウント
APIで取ってくるのにConsumer Key, Consumer Key Secret, Oauth Token, Oauth Token Secretなるものが必要です。
これらはツイッター開発者アカウントを登録すると入手できます。結果的にツイッターのユーザーアカウントも必要です。
どのサイトみたか忘れましたがこちらなんかどうぞ。
- Elastic Stack(ELK)
こちらも必要です。基本的には公式サイトからzipを落としてbinaryを実行すれば良いです。
- Windowsがいいんだけど…
仕方ないですね、こちらをどうぞ。
- Ubuntuならある
じゃこちらで。
- Macabをインストール
こちらからSourceとIPA 辞書をDLして解凍してください。それぞれの中で
$ ./configure --with-charset=utf8
$ make
$ sudo make install
したらOKです。
書くコード
ツイートを取得するコード
Twitter APIで特定のユーザーのタイムラインを取得します。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from requests_oauthlib import OAuth1Session
import json
import MeCab
CK = 'AAAAAAAAAAAAAAAAAAA'
# Consumer Key
CS = 'BBBBBBBBBBBBBBBBBBB'
# Consumer Key Secret
AT = 'CCCCCCCCCCCCCCCCCCC'
# Oauth Token
AS = 'DDDDDDDDDDDDDDDDDDD'
# Oauth Token Secret
url = "https://api.twitter.com/1.1/statuses/user_timeline.json" #this url for getting home timeline
# here can be set ID of tweet (ordered by time), and number of tweets (default is 20, max 200)
params = {'count':200, 'screen_name':'ACCOUNT'}
# ACCOUNT = ツイッターでリプするときに@ACCOUNTで表示される部分
# GET request
twitter = OAuth1Session(CK, CS, AT, AS)
req = twitter.get(url, params = params)
f = open("user.json","w")
if req.status_code == 200:
timeline = json.loads(req.text)
for tweet in timeline:
array=[]
for word in tweet["text"].split(" "):
array.append(word)
tweet['words']=array
array=[]
tagger = MeCab.Tagger()
text_str = tweet["text"].encode('utf-8')
node = tagger.parseToNode(text_str)
mecab = []
while node:
pos = node.feature.split(",")[0]
if pos == "名詞":
word = node.surface.decode("utf-8")
mecab.append(word)
elif pos == "動詞":
word = node.surface.decode("utf-8")
mecab.append(word)
node = node.next
tweet['mecab']=mecab
json.dump(tweet, f)
f.write('\n')
else:
print("Error: %d" % req.status_code)
自分のTLが欲しい人は
...
url = "https://api.twitter.com/1.1/statuses/home_timeline.json"
...
params = {'count':200}
...
ツイート検索の結果が欲しい人は
...
url = "https://api.twitter.com/1.1/search/tweets.json"
...
params = {'q':'碧志摩メグ', 'count':'200'}
...
です。
Elastic Stackの設定ファイル
Logstashのconfigファイルは必須です。起動時に指定するものです。
(serviceで起動する人は、/etc/logstash/conf.d/以下に置いてください)
input {
file {
path => "/Users/you/py/timeline.json"
start_position => "beginning"
type => "timeline"
codec => "json"
}
file {
path => "/Users/you/py/user.json"
start_position => "beginning"
type => "user"
codec => "json"
}
}
filter {
date {
match => [ "created_at" , "EEE MMM dd HH:mm:ss Z yyyy"]
target => "created_at"
}
grok {
match => { "created_at" => "%{YEAR}-%{MONTHNUM}-%{MONTHDAY}T%{HOUR:tweet_hour:int}:%{MINUTE}:%{SECOND}.000Z"}
}
ruby {
code => "event.set('[tweet_hour]', event.get('tweet_hour') + 9)"
}
if [tweet_hour] > 23 {
ruby {
code => "event.set('[tweet_hour]', event.get('tweet_hour') - 24)"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "twitter-%{type}-%{+YYYY.MM.dd}"
}
}
あとのElastic Stackたちはよしなにしてくれます。
Kibanaの設定は奥が深いんですが、ひとまずこちらから設定ファイルをコピーしてImportしましょう。
Kibanaの画面(http://localhost:5601)の左側の[Management]->[Saved Objects]->[Import]
です。
あとはこれを弄り回して体で覚えましょう。
実行
Elastic Stackたちは先に実行しておいてください。
zip解凍派は(Elastic Stack-version)/bin/(Elastic Stack)、
自動起動派はservice (Elastic Stack) startです。
先ほどのツイートを取得するコードを実行します。
$ python user.py
出てきたファイルをLogstashで読み込む場所(上例なら/home/you/py)に置くとLogstashが吸い取ってくれます。
あとはKibanaの画面を見るだけです。
http://localhost:5601
結果
さて、結果を見てみましょう。
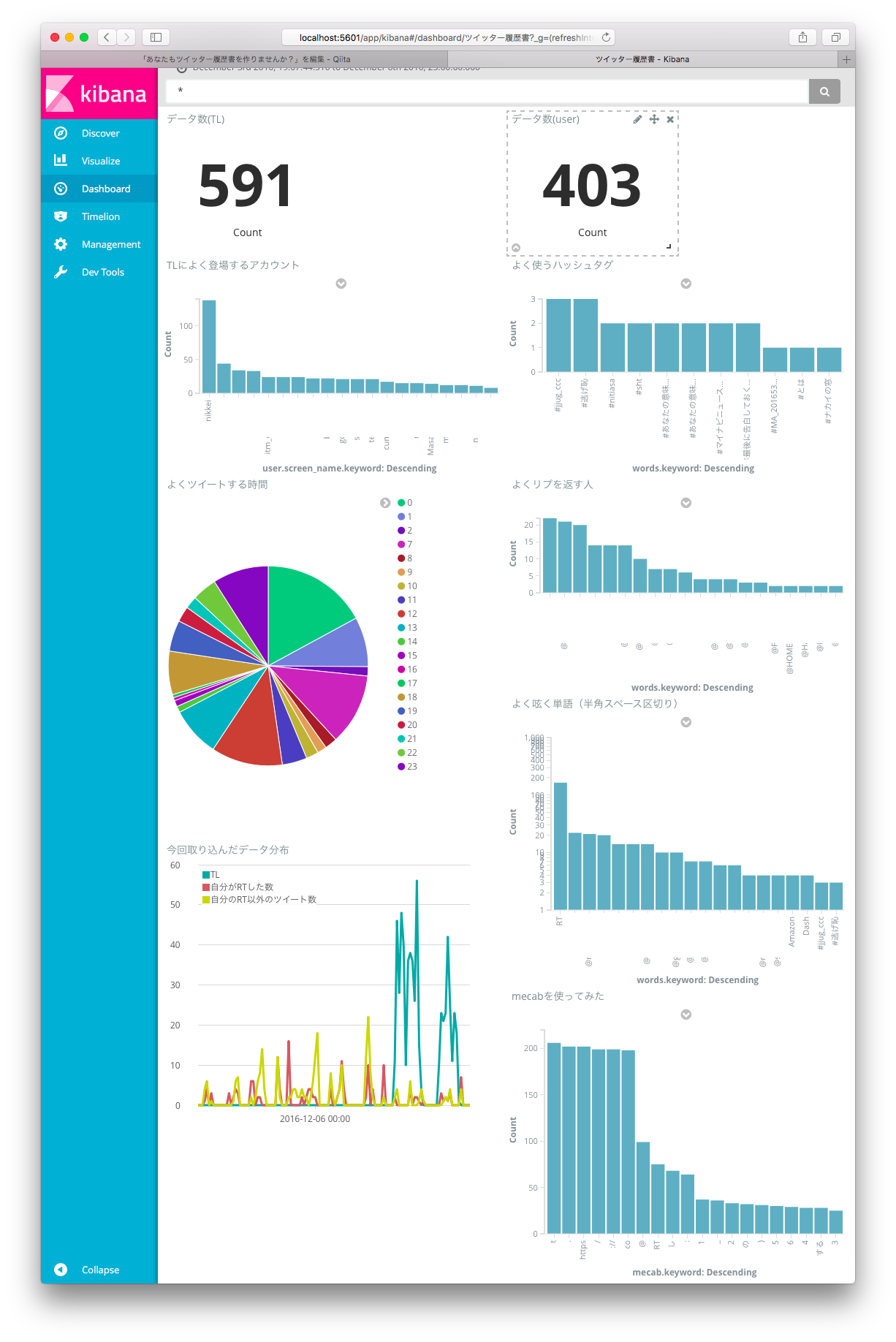
※Twitter APIの制限などもあり、データ数はあまり多くありません。
よく使うハッシュタグや、よくリプする人がよく分かりますね。
私がRT魔なのもよく分かりますね。
Amazonがなぜか私のヒットワードらしいです。心当たりは…あ、もしかしてAmazon Dash ButtonをRTしまくったからかな。こういうこともわかるんですね。
よくツイートする時間も可視化されるわけですが…うーん目が疲れててよく見えないなぁ
さて、せっかく入れたMecabですが、日本語が難敵なのかめっちゃ細かく分けられてしまいました。
Mecabのことはよくわからないんですが、多分、kibana側で3文字以上の単語というふうに絞れたらもっとまともな結果が見れるのかなと思います。
感想
楽しかったですね!
この2日間、仕事でWindowsと睨めっこして帰ってもMacとお友達してたわけですが、楽しいことは疲れないものです。
Kibanaには他にもいろんなvisualize方法があります。是非皆さんの手で試していただくか、少しググると興味をそそる実例が出てくると思います。
あれ、これ何で書き始めたんだっけ…楽しかったからまあいっか…
悪用は禁止ですよ?
お兄さんとの約束ですからね?