本記事は https://qiita.com/yamathcy/items/144f91c0ac873b1f3feb の続きです.
Deep salienceは任意の楽器のピッチだけを求めるだけでなく,一部の特定の楽器のピッチだけ取り出すことも可能になっています.
今回は歌声のピッチ取り出しを試してみます.
Melody Extraction
音源分離を挟まず,歌声のピッチを伴奏付き音源から直接取り出す技術はmelody extractionと呼ばれていて,これからやる事はそのmelody extractionに該当します.
イメージは以下の通りです.

弊サーベイまとめ記事(https://speakerdeck.com/yamathcy/lun-wen-satadenaito-number-01-semi-supervised-learning-using-teacher-student-models-for-vocal-melody-extraction )より
今回使う音源
Karissa Hobbs - Let’s Go Fishin’
Librosa同梱のExampleファイルの一つで,フォークソング風の(?)の曲です. 女性歌手が歌っています.
1番の部分を抜き出して可視化してみます.
曲のCQTスペクトログラム
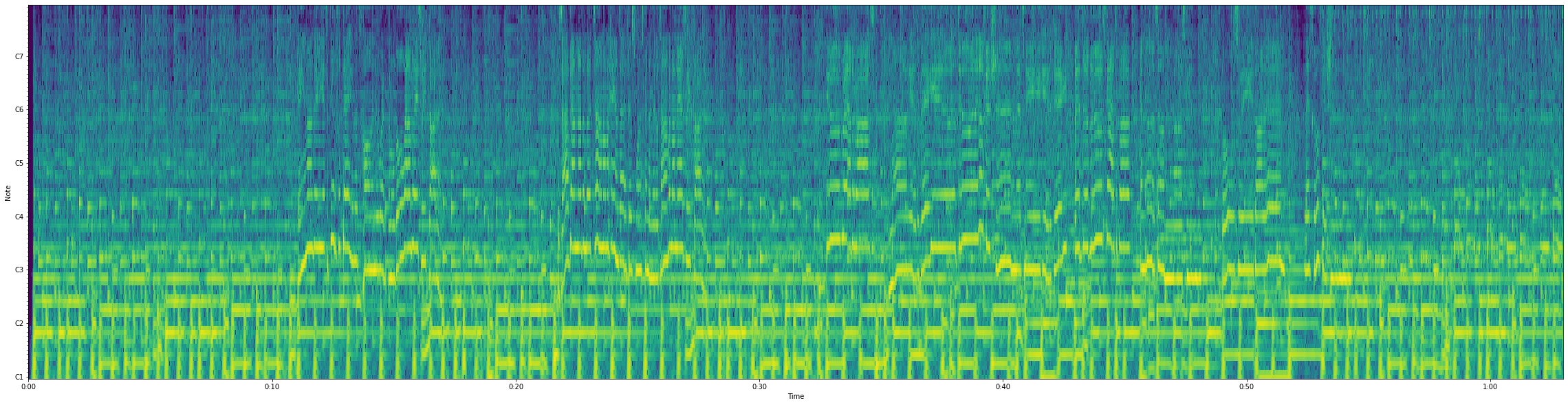
歌声のピッチだと思われる部分(白線)
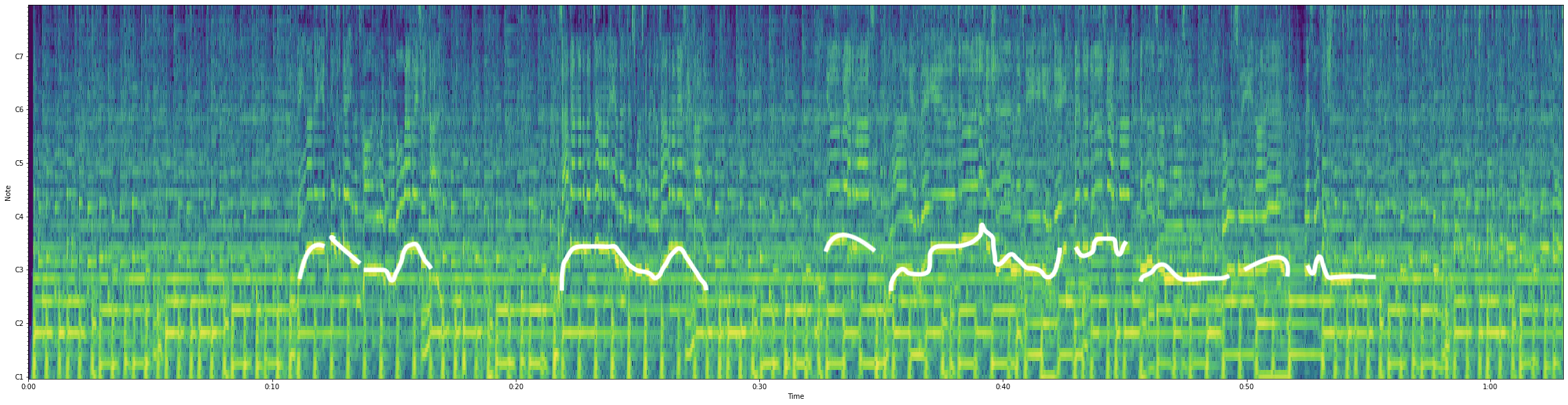
この白線部分をうまく抽出することが目標となります.
実装
まず下準備として前回の記事の前半部分を予め実装しておき,
後半部分を以下のようにカスタマイズしてください.
また,weightsフォルダにはmultif0.h5ではなくvocal.h5を入れておいてください.
spec = compute_hcqt(librosa.example('fishin'))
model = load_model('vocal')
pitch_activation_mat = get_single_test_prediction(model, spec[0])
これによって抽出したpitch salienceは以下のようになりました.まるまる1曲分入力した結果です.

CQTスペクトログラム
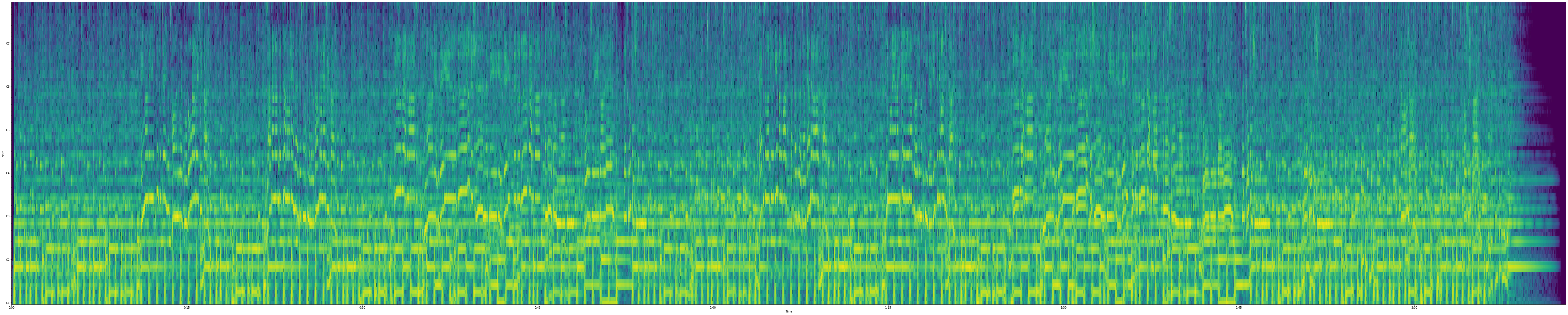
多少伴奏のバンジョーのピッチを拾っていますが,概ね歌声のピッチを抽出できているのがわかります.
さらに推定したpitch salienceからピッチ系列を求めてみます.
著者のリポジトリ(https://github.com/rabitt/ismir2017-deepsalience )から,pitch salienceを入力にピッチ系列を出力するコードを抜粋します.
def get_singlef0(pitch_activation_mat, freq_grid, time_grid, thresh=0.3,
use_neg=True):
"""Compute single-f0 output containing the maximum likelihood per time frame.
Frames with no likelihoods above the threshold are given negative values.
Parameters
----------
pitch_activation_mat : np.ndarray
Deep salience prediction
freq_grid : np.ndarray
Frequency values
time_grid : np.ndarray
Time values
thresh : float, default=0.3
Likelihood threshold
use_neg : bool
If True, frames with no value above the threshold the frequency
are given negative values of the frequency with the largest liklihood.
If False, those frames are given the value 0.0
Returns
-------
times : np.ndarray
Time values
freqs : np.ndarray
Frequency values
"""
max_idx = np.argmax(pitch_activation_mat, axis=0)
est_freqs = []
for i, f in enumerate(max_idx):
if pitch_activation_mat[f, i] < thresh:
if use_neg:
est_freqs.append(-1.0*freq_grid[f])
else:
est_freqs.append(0.0)
else:
est_freqs.append(freq_grid[f])
est_freqs = np.array(est_freqs)
return time_grid, est_freqs
返り値として,フレーム時刻とその時刻におけるピッチの値が返ってきます.
こちらはpitch salienceの各時刻,最も高い値をとった周波数の部分を抜き出し,
閾値(デフォルト0.3)より高ければアクティブ(そのピッチを歌っている),非アクティブ(歌っていない)な時刻として処理するものです.
結果を可視化してみます.
estimated_pitch = get_singlef0(pitch_activation_mat,spec[1], spec[2], use_neg=False)
plt.figure(figsize=(100,20))
plt.plot(estimated_pitch[1], marker='s', linestyle='-')

若干パタ付きはあるものの,メロディはおおむね捉えています.
この結果をcsvに書き出し,
sonic visualizerなどを使えばピッチとして再合成し,どうだったか評価することができそうです.
(再合成した音声も作りましたが,著作権上どうなってるかわからずグレーゾーンなので,音源の共有は割愛します.ご自分でぜひ試してください.)
おわりに
本記事では伴奏付きトラックからdeep salienceによって歌声のピッチを求めました.
これさえあれば,あとはピッチ系列を音符に変換するだけです.ピッチの変動への工夫などは色々あるので,そこも調べて良さげな方法があればまた記事を書きたいと思います.
参考
前回の記事
https://qiita.com/yamathcy/items/144f91c0ac873b1f3feb
Deep Salience Representations for f0 Estimation in Polyphonic Music
Rachel. M. Bittner, B. McFee, J. Salamon, P. Li, and J. P. Bello.
In 18th International Society for Music Information Retrieval Conference, Suzhou, China, Oct. 2017.
Librosa
筆者によるサーベイまとめスライド
https://speakerdeck.com/yamathcy/lun-wen-satadenaito-number-01-semi-supervised-learning-using-teacher-student-models-for-vocal-melody-extraction
Semi-supervised Learning Using Teacher-student Models for Vocal Melody Extraction
S. Kum, J. Lin, L. Su, J. Nam.
In 21st International Society for Music Information Retrieval Conference, 2020.