先日,自動採譜に使えそうな特徴表現であるDeep salienceを使ってみたので備忘録.
書誌情報はこちら↓
Deep Salience Representations for f0 Estimation in Polyphonic Music
Rachel. M. Bittner, B. McFee, J. Salamon, P. Li, and J. P. Bello.
In 18th International Society for Music Information Retrieval Conference, Suzhou, China, Oct. 2017.
Deep salienceとは
Deep salienceは,楽音の特徴表現である**Pitch Salience(ピッチサリエンス)**を畳み込みニューラルネットワーク(CNN)によって計算して獲得する手法の一つです.
Pitch salienceとは,スペクトログラムのように 周波数×時間の2次元の特徴表現で各時刻,各ピッチ(周波数ビン)における音符の存在確率を表したものです.すなわち,各要素は$[0,1]$の値をとります.
自動採譜では 楽音に含まれる各楽器のピッチ(基本周波数;f0)を同定することが重要になりますが,そのうちの一つのやり方として,
楽音(1次元の信号波形) - > スペクトログラム(2次元の行列) - > Pitch Salience(同じく2次元の行列,倍音や雑音成分の抑制) -> 各楽器のf0値 (または音符)
という流れで処理をします.
よいPitch salienceを得ることができないと,自動採譜もうまくいかず,その部分がボトルネックとなってしまいます.
従来(参考: https://www.audiolabs-erlangen.de/resources/MIR/FMP/C8/C8S2_SalienceRepresentation.html )
は信号処理の知見をあれこれ使いPitch salienceを得ていましたが,
この手法はCNNを用いて各楽器のピッチの部分だけを際立たせるようにし,精度を上げたPitch salienceを得る事ができるものです.
Deep salienceの処理
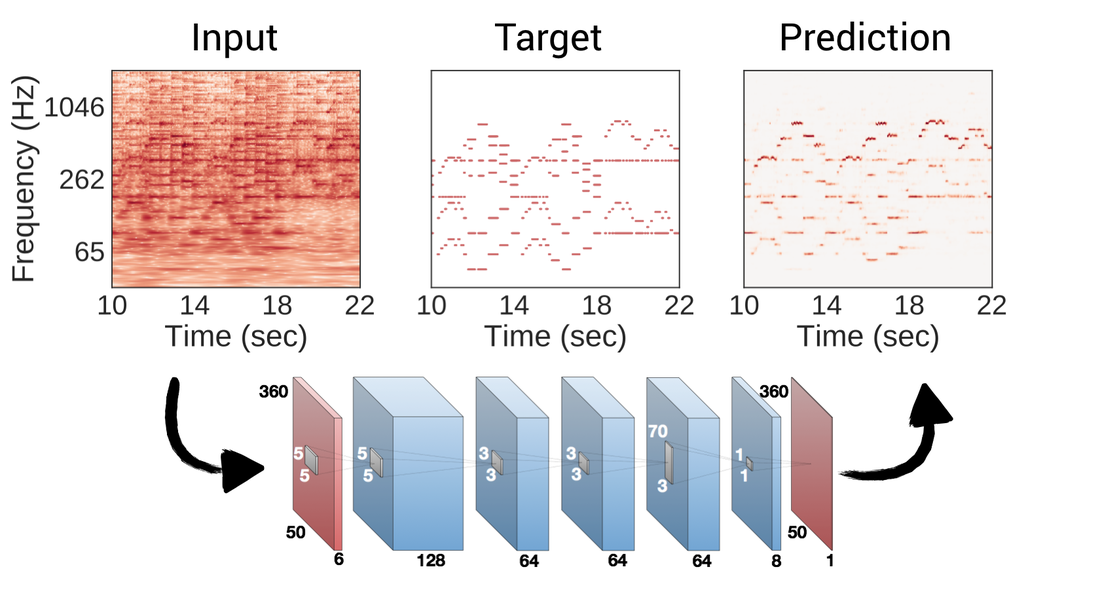
- 入力 Harmonic CQT(HCQT):CQTスペクトログラム(http://librosa.org/doc/main/generated/librosa.cqt.html ) を半オクターブ・1オクターブ・2オクターブ...と下にピッチシフトしてチャンネル方向に重ねたもの. 形状:(6 * 360 * 時間フレーム数)
- 処理 6層の畳み込み層をもつCNN: keras+tensorflowを利用
- 出力 Pitch salience 形状:(360 * 時間フレーム数)
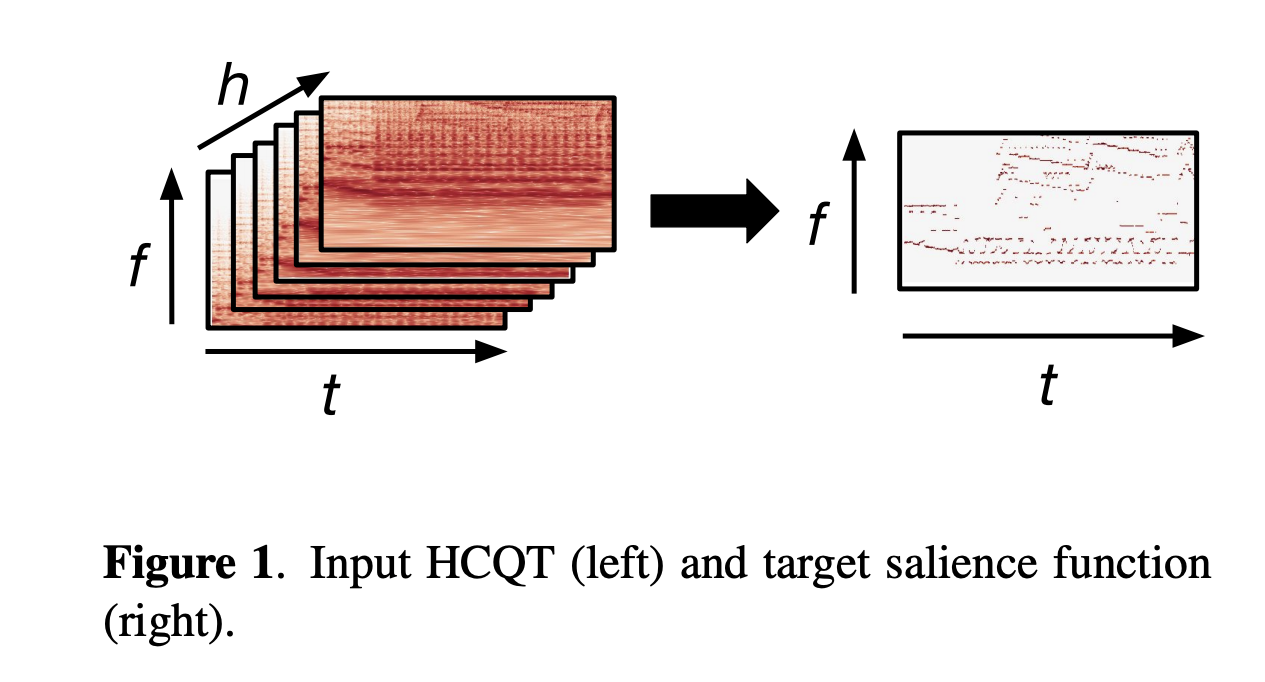 (論文から抜粋. HCQTからpitch salienceを得る.)
(論文から抜粋. HCQTからpitch salienceを得る.)
実装
特徴表現として有用なものだとは思いますが,残念ながら2021年6月現在,PyPIからインストールできるようなライブラリにはなっていません.
そのため,論文の著者のgithubリポジトリ(https://github.com/rabitt/ismir2017-deepsalience )から該当部分を抜粋し,さらに学習済みモデルのパラメータをインストールします.
(このリポジトリ,実験が充実しているのは素晴らしいですが,コア部分を探し出すのに苦労しました...)
import numpy as np
import matplotlib.pyplot as plt
import librosa
import librosa.display
from keras.models import Model
from keras.layers import Dense, Input, Reshape, Lambda
from keras.layers.convolutional import Conv2D
from keras.layers.normalization import BatchNormalization
from keras import backend as K
from keras.models import load_model
# ハイパーパラメータ
# どの楽器のSalienceが欲しいか bass:ベース, melody1,2,3:メロディ, multif0:複数楽器, pitch:単音, vocal:歌声
TASKS = ['bass', 'melody1', 'melody2', 'melody3', 'multif0', 'pitch', 'vocal']
# 1オクターブに含まれる周波数ビン数
BINS_PER_OCTAVE = 60
# オクターブ数
N_OCTAVES = 6
# HCQTのピッチシフト半・1・2・3・4・5オクターブピッチシフトしたものをチャンネル方向に重ねる
HARMONICS = [0.5, 1, 2, 3, 4, 5]
# サンプリング周波数
SR = 44100
# CQTの最低周波数
FMIN = 36.0
# ホップ幅
HOP_LENGTH = 1024
def compute_hcqt(audio_fpath):
# 楽音のファイルパスを入力するとHCQTを計算する関数
# HCQTそのものと時間の値,周波数の値を返す
"""
----------
audio_fpath : str
path to audio file
Returns
-------
hcqt : np.ndarray
Harmonic cqt
time_grid : np.ndarray
List of time stamps in seconds
freq_grid : np.ndarray
List of frequency values in Hz
"""
y, fs = librosa.load(audio_fpath, sr=SR)
cqt_list = []
shapes = []
for h in HARMONICS:
cqt = librosa.cqt(
y, sr=fs, hop_length=HOP_LENGTH, fmin=FMIN*float(h),
n_bins=BINS_PER_OCTAVE*N_OCTAVES,
bins_per_octave=BINS_PER_OCTAVE
)
cqt_list.append(cqt)
shapes.append(cqt.shape)
shapes_equal = [s == shapes[0] for s in shapes]
if not all(shapes_equal):
min_time = np.min([s[1] for s in shapes])
new_cqt_list = []
for i in range(len(cqt_list)):
new_cqt_list.append(cqt_list[i][:, :min_time])
cqt_list = new_cqt_list
log_hcqt = ((1.0/80.0) * librosa.core.amplitude_to_db(
np.abs(np.array(cqt_list)), ref=np.max)) + 1.0
freq_grid = librosa.cqt_frequencies(
BINS_PER_OCTAVE*N_OCTAVES, FMIN, bins_per_octave=BINS_PER_OCTAVE
)
time_grid = librosa.core.frames_to_time(
range(log_hcqt.shape[2]), sr=SR, hop_length=HOP_LENGTH
)
return log_hcqt, freq_grid, time_grid
def bkld(y_true, y_pred):
"""
KL Divergence where both y_true an y_pred are probabilities
"""
y_true = K.clip(y_true, K.epsilon(), 1.0 - K.epsilon())
y_pred = K.clip(y_pred, K.epsilon(), 1.0 - K.epsilon())
return K.mean(K.mean(
-1.0*y_true* K.log(y_pred) - (1.0 - y_true) * K.log(1.0 - y_pred),
axis=-1), axis=-1)
def model_def():
# Kerasのモデルをビルドするための関数
"""
Created compiled Keras model
Returns
-------
model : Model
Compiled keras model
"""
input_shape = (None, None, 6)
inputs = Input(shape=input_shape)
y0 = BatchNormalization()(inputs)
y1 = Conv2D(128, (5, 5), padding='same', activation='relu', name='bendy1')(y0)
y1a = BatchNormalization()(y1)
y2 = Conv2D(64, (5, 5), padding='same', activation='relu', name='bendy2')(y1a)
y2a = BatchNormalization()(y2)
y3 = Conv2D(64, (3, 3), padding='same', activation='relu', name='smoothy1')(y2a)
y3a = BatchNormalization()(y3)
y4 = Conv2D(64, (3, 3), padding='same', activation='relu', name='smoothy2')(y3a)
y4a = BatchNormalization()(y4)
y5 = Conv2D(8, (70, 3), padding='same', activation='relu', name='distribute')(y4a)
y5a = BatchNormalization()(y5)
y6 = Conv2D(1, (1, 1), padding='same', activation='sigmoid', name='squishy')(y5a)
predictions = Lambda(lambda x: K.squeeze(x, axis=3))(y6)
model = Model(inputs=inputs, outputs=predictions)
model.compile(loss=bkld, metrics=['mse'], optimizer='adam')
return model
def load_model(task):
# 学習済みモデルの読み込み
"""Load a precompiled, pretrained model
Parameters
----------
task : str
One of
-'bass'
-'melody1'
-'melody2'
-'melody3'
-'multif0'
-'pitch'
-'vocal'
Returns
-------
model : Model
Pretrained, precompiled Keras model
"""
model = model_def()
if task not in TASKS:
raise ValueError("task must be one of {}".format(TASKS))
weights_path = os.path.join('weights', '{}.h5'.format(task))
if not os.path.exists(weights_path):
raise IOError(
"Cannot find weights path {} for this task.".format(weights_path))
model.load_weights(weights_path)
return model
def get_single_test_prediction(model, input_hcqt):
# モデルにHCQTを入力してpitch salienceを得る処理
"""Generate output from a model given an input numpy file
Parameters
----------
model : Model
Pretrained model
input_hcqt : np.ndarray
HCQT
Returns
-------
predicted_output : np.ndarray
Matrix of predictions
"""
input_hcqt = input_hcqt.transpose(1, 2, 0)[np.newaxis, :, :, :]
n_t = input_hcqt.shape[2]
n_slices = 2000
t_slices = list(np.arange(0, n_t, n_slices))
output_list = []
for i, t in enumerate(t_slices):
print(" > {} / {}".format(i + 1, len(t_slices)))
prediction = model.predict(input_hcqt[:, :, t:t+n_slices, :])
output_list.append(prediction[0, :, :])
predicted_output = np.hstack(output_list)
return predicted_output
実際にpitch salienceを計算してみます.
ここでは例としてlibrosaのutilに入っているexample音源のpitch salienceを計算してみます.
下準備としてさらに,
- カレントディレクトリに”weights”という新しいディレクトリを作る
- リポジトリのweightsフォルダ https://github.com/rabitt/ismir2017-deepsalience/tree/master/predict/weights から,
所望の学習済みモデルパラメタファイルをダウンロードして作ったディレクトリに入れる
の2つを済ませておいてください.
あとは簡単です.
# 音源の読み込み
file = librosa.example('vibeace')
# HCQTを計算
spec = compute_hcqt(file)
# モデルの用意
model = load_model('multif0')
# salienceを算出
salience = get_single_test_prediction(model, spec[0])
入力音源のCQTスペクトログラム(モデルの入力のHCQTではない)

計算して得たPitch salience

ここまで.
次は,ここからピッチ系列を得たり音符まで採譜してみるところまでやってみようと思います.